Page Cache
Context
You are working with a Web-based application that presents dynamic information to users. You have observed that many users access a specific page without the dynamic information changing.
Problem
How can you improve the response time of dynamically generated Web pages that are requested frequently but consume a large amount of system resources to construct?
Forces
The following forces act on a system within this context and must be reconciled as you consider a solution to the problem:
-
Generating a dynamic Web page consumes a variety of system resources. When the Web server receives a page request, the server usually has to retrieve the requested information from an external data source, such as a database or a Web service. Access to these resources often occurs over a limited pool of resources, such as database connections, sockets, or file descriptors. Because a Web server typically handles many concurrent requests, contention for these pooled resources may delay the page request until a resource becomes available. After the request has been sent to the external data source, the results still have to be transformed into HTML code for display.
-
One obvious approach to making systems faster is to buy more hardware. This option may be appealing because hardware is cheap (or so the vendors say) and the program does not have to change. On the other hand, more hardware only helps until you reach its physical limitations. Network limitations, such as data transfer rates, or latency make these physical limitations more apparent.
-
A second approach to making systems faster is to do less (processing) work. This approach requires more effort from developers, but can provide enormous increases in performance. The following paragraphs explore the challenges that this approach poses.
The following paragraphs use a weather example to show how extra development effort can relieve the processing load. If 10,000 users view the weather forecast for London within one hour, a default Web server implementation may connect to the weather service 10,000 times, and render 10,000 HTML pages with images of clouds and rain, even though it rains all day. To reduce processing, you could just get the actual weather forecast during the first request, render the HTML page, and then save that pre-rendered page for later use. When the next request for London weather arrives, the system could return the saved page to the client browser; there would be no need to connect to the weather service or render another page.
This would save CPU cycles to render redundant HTML pages and improve response times. The cost, however, would be the memory allocated to store the pre-rendered pages. Providing the weather forecast for each postal code may require that you store thousands of weather forecast pages. (There are thousands of postal codes in the United States alone.) To figure out which page the user is requesting, you would also need to index the pre-rendered pages by postal code, or possibly additional parameters such as which Web browser the user is running (the HTML may differ slightly by browser). Also, you may receive a lot more requests for the weather in a large city than for a small town. Likewise, the forecast may change more often in some regions than in others. Therefore, you need to be smart about which pages you are pre-rendering and how long you keep them around before you re-render them.
Another item to consider is the composition of the page. Maybe you want to display a combination page with the weather and the current stock prices. Because stock prices change more often than the weather, you can no longer store the complete page. You can store pieces of the page, but then you must manage each page component separately and reassemble it from pre-rendered components as requests arrive.
Yet another consideration is the variability of the pages. For example, the weather data may not change, but the page may still look different for different users based on user preferences such as language, color, browser, and device (computer, Personal Digital Assistant (PDA), or phone). If you store the rendered page, you have to store each version separately. If you store the weather data, however, you save a trip to the weather service, but you still have to render the page. So you use a few more CPU cycles, but need to cache much less information. For a more detailed description of this approach, see Page Data Caching.
Solution
Use a page cache for dynamic Web pages that are accessed frequently, but change less often.
Structure
The basic structure of a page cache is relatively simple. The Web server maintains a local data store with pre-rendered pages (see Figure 3.28).
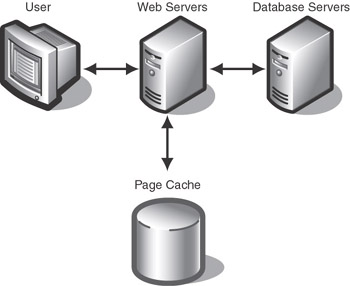
Figure 3.28: Basic page cache configuration
Dynamics
The following sequence diagrams make it clear why a page cache can improve performance. The first sequence diagram (Figure 3.29, on the next page) depicts the initial state where the desired page is not yet cached (a so-called cache miss). In this scenario, the Web server must access the database, render the HTML page, store it in the cache, and then return the page to the client browser. Note that this process is slightly slower than the scenario without caching because it performs the following extra steps:
-
Determines whether the page is cached
-
Stores the page in the cache after it is rendered into HTML
Neither step should take very long in comparison to the database access and the HTML generation. Because this scenario requires extra processing, however, you must ensure a good series of cache hits after the system goes through the steps associated with a cache miss, which are shown in Figure 3.29 on the next page.
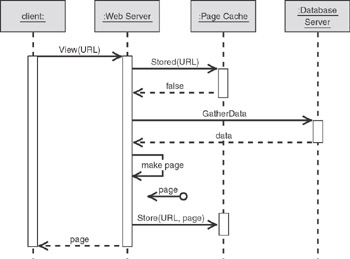
Figure 3.29: Sequence for a cache miss (when the page is not in the cache)
In the cache hit scenario shown in Figure 3.30, the page is already in the cache. A cache hit saves cycles by skipping the database access, the page rendering, and the storing of the page.
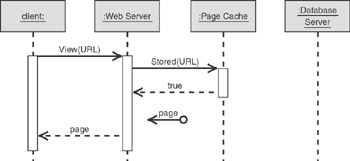
Figure 3.30: Sequence for a cache hit (when the page is in the cache)
Implementation
Caching strategies are an extensive topic that cannot be covered exhaustively in a single pattern. Nevertheless, it is important to discuss the considerations that are most relevant when implementing a solution that includes Page Cache.
A Page Cache solution consists of the following key mechanisms:
-
Page (or page fragments) storage
-
Page indexing
-
Cache refresh
The following paragraphs discuss each of these mechanisms.
Page Storage
A page cache must store pre-rendered pages so that the system can retrieve them quickly. You also want to be able to store as many pages as possible to increase the chances of a cache hit. When it comes to storage, you usually face a tradeoff between speed, size, and cost. Assuming that you do not have unlimited funds at hand, the choice is usually between small or fast. Smaller caches can live in memory and can be very fast. Larger disk storage caches offer more storage, but are significantly slower.
To reach the best compromise between speed and size, you must be careful about which pages you cache. Some pages will be accessed much more frequently than others, so, ideally, you should cache only the popular pages and forget about the rarely used ones. This decision is not always easy to make, because usage patterns tend to vary. Many caches implement strategies such as Least Frequently Used (LFU) to remove pages that have been used infrequently since being stored. Other caching schemes let the user specify the caching strategy for each individual page.
The next most important decision is how big the pieces in the cache should be. Storing complete pages enables quick page display after a page hit, because the system retrieves the page from the cache and immediately sends it to the client without any other action. However, if some portions of the page change frequently and others do not (for example, a page with weather and stock prices), storing complete pages could lead to a lot of extra storage. Storing smaller pieces improves the chances of a page hit, but also requires more storage overhead (there are more pieces to index) and more CPU consumption (testing the cache for multiple segments and assembling the final page). For a description on how to assemble pages from cached segments, see Page Fragment Caching.
Page Indexing
It is also important to consider how the system locates pages in the cache. The simplest method for a system to locate pages is by URL. If a page does not depend on any other factors, you can retrieve it from the cache simply by comparing the requested URL to the URLs of the pages stored in the cache. However, this scenario rarely occurs. Almost all dynamic pages are built based on parameters such as user preferences, query strings, form fields, and internal application state. For example, the weather page in the earlier example depends on the postal code that users enter. So the system may have to store multiple instances of one page, based on the parameter. In the postal code example, this could translate to thousands of pages. This is inefficient because weather services do not actually maintain the forecast for every postal code, but rather by city or region. If you know how the weather service translates postal codes into weather regions, you can reduce the number of cached pages by an order of magnitude and increase the average hit rate. As always, the more information you have, the more efficient you can be. You can use Vary-By-Parameter Caching to implement this type of caching, where the page content depends on parameters.
Cache Refresh
How long the system keeps items in the cache is also important. Storing pages for a fixed amount of time is the simplest method (see Implementing Page Cache in ASP.NET Using Absolute Expiration). This method may not always be sufficient, however. In the weather example, if an unusual weather pattern such as a cold front or a hurricane is approaching a major city, you may want to update every 15 minutes. You can resolve these issues by tying the caching duration to external events. For example, you may choose to flush the cache when an external event arrives (for example, late-breaking news), forcing the page to be re-rendered when the next request arrives.
Some caching strategies try to pre-render pages during low-traffic periods. This approach can be very effective if you have predictable traffic patterns and you can hold pages long enough to avoid refreshing during peak traffic times.
Resulting Context
Page Cache results in the following benefits and liabilities:
Benefits
-
Conserves CPU cycles required to render pages. This results in faster response times and increases the scalability of the Web server to a larger number of concurrent users.
-
Eliminates unnecessary round-trips to the database or other external data sources. This benefit is particularly important, because these external sources usually provide only a limited number of concurrent connections that must be shared by all concurrent page requests in a resource pool. Frequent access to external data sources can quickly bring a Web server to an abrupt halt due to resource contention.
-
Conserves client connections. Each concurrent connection from a client browser to the Web server consumes limited resources. The longer it takes to process a page request, the longer the connection resource is tied up.
-
Enables concurrent access by many page requests. Because a page cache is primarily a read-only resource, it can be multithreaded rather easily. Therefore, it prevents resource contention that can occur when the system accesses external data sources. The only portion that must be synchronized is the cache update, so the considerations around frequency of update are most critical to good performance.
-
Increases the availability of the application. If the system accesses an external data source to render pages, it depends on the data source being available. Page caching enables the system to deliver cached pages to the clients even when the external source becomes unavailable; the data may not be current, but it is likely better than no data at all.
Note If this function is critical to your caching strategy, consider using Page Data Cache, which can provide more flexibility for external data sources.
Liabilities
-
Displays information that is not current. If the cache refresh mechanism is configured incorrectly, the Web site could display invalid data, which could be confusing or even harmful. For example, an overly extended caching interval in a live stock feed could become very costly for the user who makes purchasing decisions based on the data.
-
Requires CPU and memory (RAM or disk) resources. Caching pages that are not frequently viewed or setting refresh intervals that are too short can incur additional overhead and actually decrease server performance. As with all performance measures, perform a thorough analysis using actual measurements and performance indicators to determine the correct settings. Hasty decisions, such as caching every page, can do more harm than good.
-
Adds complexity to the system and can make it more difficult to test and debug. In most cases, you should develop and test the application without caching and then enable caching options during the performance-tuning phase.
-
Requires additional security considerations. This implication of caching is often overlooked. When a Web server is processing concurrent requests for confidential information from multiple users, it is important to avoid crossover between these requests. Because the page cache is a global entity, an improperly configured page cache may deliver a page to the browser that was originally rendered for another user. This may not be an issue with weather forecasts, but would pose a serious problem if, for example, the system displayed a user’s bank statement to another user.
-
Can produce dramatically inconsistent response times. Although delivering pages quickly in 99 percent of the cases is surely better than delivering slow pages every time, a caching strategy that is over-optimized for cache hits and under-optimized for cache misses can cause sporadic timeouts. This concern is particularly relevant for Web services as opposed to simple HTML pages.
Related Patterns
The following patterns describe various strategies for implementing Page Cache:
-
Implementing Page Cache in ASP.NET Using Absolute Expiration. This pattern inserts a directive into each page that is to be cached. The directive specifies the refresh interval in seconds. The refresh interval does not depend on external events, and the cache cannot be flushed.
-
Vary-By-Parameter Caching. This pattern uses a variation of Absolute Expiration that enables the developer to specify parameters that affect the contents of the page. As a result, the cache stores multiple versions of the page, which are indexed by the parameter values.
-
Sliding Expiration Caching. This pattern is similar to Absolute Expiration in that the page is valid for a specified time. However, the refresh interval is reset on each request. For example, you could use sliding expiration caching to cache a page for a maximum of 10 minutes. As long as requests for the page are made within 10 minutes, the expiration is postponed for another 10 minutes.
EAN: N/A
Pages: 107