| In any real application you'll be managing lists and groups of things. Java provides a healthy and useful set of library classes to help with this: the Collections utilities. Hibernate provides natural ways for mapping database relationships onto Collections, which are usually very convenient . You do need to be aware of a couple semantic mismatches , generally minor. The biggest is the fact that Collections don't provide 'bag' semantics, which might frustrate some experienced database designers. This gap isn't Hibernate's fault, and it even makes some effort to work around the issue. NOTE Bags are like sets, except that the same value can appear more than once. Enough abstraction! The Hibernate reference manual does a good job of discussing the whole bag issue, so let's leave it and look at a working example of mapping a collection where the relational and Java models fit nicely . It might seem natural to build on the Track examples from Chapter 3 and group them into albums, but that's not the simplest place to start, because organizing an album involves tracking additional information, like the disc on which the track is found (for multi-disc albums), and other such finicky details. So let's add artist information to our database. NOTE As usual, the examples assume you followed the steps in the previous chapters. If not, download the example source as a starting point. The information we need to keep track of for artists is, at least initially, pretty simple. We'll start with just the artist's name . And each track can be assigned a set of artists , so we know who to thank or blame for the music, and you can look up all tracks by someone we like. (It really is critical to allow more than one artist to be assigned to a track, yet so few music management programs get this right. The task of adding a separate link to keep track of composers is left as a useful exercise for the reader after understanding this example.) 4.1.2 How do I do that? For now, our Artist class doesn't need anything other than a name property (and its key, of course). Setting up a mapping document for it will be easy. Create the file Artist.hbm.xml in the same directory as the Track mapping document, with the contents shown in Example 4-1. Example 4-1. Mapping document for the Artist class 1 <?xml version="1.0"?> 2 <!DOCTYPE hibernate-mapping PUBLIC"-//Hibernate/Hibernate Mapping DTD 2.0//EN" 3 "http://hibernate.sourceforge.net/hibernate-mapping-2.0.dtd"> 4 5 <hibernate-mapping> 6 7 <class name="com.oreilly.hh.Artist" table="ARTIST"> 8 <meta attribute="class-description"> 9 Represents an artist who is associated with a track or album. 10 @author Jim Elliott (with help from Hibernate) 11 </meta> 12 13 <id name="id" type="int" column="ARTIST_ID"> 14 <meta attribute="scope-set">protected</meta> 15 <generator class="native"/> 16 </id> 17 18 <property name="name" type="string"> 19 <meta attribute="use-in-tostring">true</meta> 20 <column name="NAME" not-null="true" unique="true" index="ARTIST_NAME"/> 21 </property> 22 23 <set name="tracks" table="TRACK_ARTISTS" inverse="true"> 24 <meta attribute="field-description">Tracks by this artist</meta> 25 <key column="ARTIST_ID"/> 26 <many-to-many class="com.oreilly.hh.Track" column="TRACK_ID"/> 27 </set> 28 29 </class> 30 31 </hibernate-mapping>
Our mapping for the name property on lines 18-21 introduces a couple of refinements to both the code generation and schema generation phases. The use-in-tostring meta tag causes the generated class to show the artist's name as well as the cryptic synthetic ID when it is printed, as an aid for debugging (you can see the result near the bottom of Example 4-3). And expanding the column attribute into a full-blown tag allows us finer-grained control over the nature of the column, which we use in this case to add an index for efficient lookup and sorting by name. Notice that we can represent the fact that an artist is associated with one or more tracks quite naturally in this file (lines 23-27). This tells Hibernate to add a property named tracks to our Artist class, whose type is an implementation of java.util.Set . This will use a new table named TRACK_ARTISTS to link to the Track objects for which this Artist is responsible. The attribute inverse="true" is explained in the discussion of Example 4-2, where the bidirectional nature of this association is examined. The TRACK_ARTISTS table we just called into existence will contain two columns : TRACK_ID and ARTIST_ID . Any rows appearing in this table will mean that the specified Artist object has something to do with the specified Track object. The fact that this information lives in its own table means that there is no restriction on how many tracks can be linked to a particular artist, nor how many artists are associated with a track. That's what is meant by a 'many-to-many' association. [4.1] [4.1] If concepts like join tables and many-to-many associations aren't familiar, spending some time with a good data modeling introduction would be worthwhile. It will help a lot when it comes to designing, understanding, and talking about data-driven projects. George Reese's Java Database Best Practices (O'Reilly) has one, and you can even view this chapter online at www.oreilly.com/catalog/javadtabp/chapter/ch02.pdf. On the flip side, since these links are in a separate table you have to perform a join query in order to retrieve any meaningful information about either the artists or the tracks. This is why such tables are often called 'join tables.' Their whole purpose is to be used to join other tables together. Finally, notice that unlike the other tables we've set up in our schema, TRACK_ARTISTS does not correspond to any mapped Java object. It is used only to implement the links between Artist and Track objects, as reflected by Artist 's tracks property. As seen on line 24, the field-description meta tag can be used to provide JavaDoc descriptions for collections and associations as well as plain old value fields. This is handy in situations where the field name isn't completely self-documenting . The tweaks and configuration choices provided by the mapping document, especially when aided by meta tags, give you a great deal of flexibility over how the source code and database schema are built. Nothing can quite compare to the control you can obtain by writing them yourself, but most common needs and scenarios appear to be within reach of the mapping-driven generation tools. This is great news, because they can save you a lot of tedious typing! With that in place, let's add the collection of Artists to our Track class. Edit Track.hbm.xml to include the new artists property as shown in Example 4-2 (the new content is shown in bold). Example 4-2. Adding an artist collection to the Track mapping file ... <property name="playTime" type="time"> <meta attribute="field-description">Playing time</meta> </property> <set name="artists" table="TRACK_ARTISTS"> <key column="TRACK_ID"/> <many-to-many class="com.oreilly.hh.Artist" column="ARTIST_ID"/> </set> <property name="added" type="date"> <meta attribute="field-description">When the track was created</meta> </property> ...
This adds a similar Set property named artists to the Track class. It uses the same TRACK_ARTISTS join table introduced in Example 4-1 to link to the Artist objects we mapped there. This sort of bidirectional association is very useful. It's important to let hibernate know explicitly what's going on by marking one end of the association as 'inverse.' In the case of a many-to-many association like this one, the choice of which side to call the inverse mapping isn't crucial. The fact that the join table is named 'track artists' makes the link from artists back to tracks the best choice for the inverse end, if only from the perspective of people trying to understand the database. Hibernate itself doesn't care, as long as we mark one of the directions as inverse. That's why we did so on line 23 of Example 4-1. While we're updating the Track mapping document we might as well beef up the title property along the lines of what we did for name in Artist : <property name="title" type="string"> <meta attribute="use-in-tostring">true</meta> <column name="TITLE" not-null="true" index="TRACK_TITLE"/> </property>
With the new and updated mapping files in place, we're ready to rerun ant codegen to update the Track source code, and create the new Artist source. This time Hibernate reports that two files are processed , as expected. If you look at Track.java you'll see the new Set -valued property artists has been added, and toString() has been enhanced. Example 4-3 shows the content of the new Artist.java . Example 4-3. Code generated for the Artist class package com.oreilly.hh; import java.io.Serializable; import java.util.Set; import org.apache.commons.lang.builder.EqualsBuilder; import org.apache.commons.lang.builder.HashCodeBuilder; import org.apache.commons.lang.builder.ToStringBuilder; /** * Represents an artist who is associated with a track or album. * @author Jim Elliott (with help from Hibernate) * */ public class Artist implements Serializable { /** identifier field */ private Integer id; /** nullable persistent field */ private String name; /** persistent field */ private Set tracks; /** full constructor */ public Artist(String name, Set tracks) { this.name = name; this.tracks = tracks; } /** default constructor */ public Artist() { } /** minimal constructor */ public Artist(Set tracks) { this.tracks = tracks; } public Integer getId() { return this.id; } protected void setId(Integer id) { this.id = id; } public String getName() { return this.name; } public void setName(String name) { this.name = name; } /** * Tracks by this artist */ public Set getTracks() { return this.tracks; } public void setTracks(Set tracks) { this.tracks = tracks; } public String toString() { return new ToStringBuilder(this) .append("id", getId()) .append("name", getName()) .toString(); } public boolean equals(Object other) { if ( !(other instanceof Artist) ) return false; Artist castOther = (Artist) other; return new EqualsBuilder() .append(this.getId(), castOther.getId()) .isEquals(); } public int hashCode() { return new HashCodeBuilder() .append(getId()) .toHashCode(); } }
Once the classes are created, we can use ant schema to build the new database schema that supports them.  | Of course you should watch for error messages when generating your source code and building your schema, in case there are any syntax or conceptual errors in the mapping document. Not all exceptions that show up are signs of real problems you need to address, though. In experimenting with evolving this schema, I ran into some stack traces because Hibernate tried to drop foreign key constraints that hadn't been set up by previous runs. The schema generation continued past them, scary as they looked , and worked correctly. This may be something that will improve in future versions (of Hibernate or HSQLDB), or it may just be a wart we learn to live with. | |
The generated schema contains the tables we'd expect, along with indices and some clever foreign key constraints. As our object model gets more sophisticated, the amount of work (and expertise) being provided by Hibernate is growing nicely. The full output from the schema generation is rather long, but Example 4-4 shows highlights. Example 4-4. Excerpts from our new schema generation [schemaexport] create table TRACK_ARTISTS ( [schemaexport] ARTIST_ID INTEGER not null, [schemaexport] TRACK_ID INTEGER not null, [schemaexport] primary key (TRACK_ID, ARTIST_ID) [schemaexport] ) ... [schemaexport] create table ARTIST ( [schemaexport] ARTSIT_ID INTEGER NOT NULL IDENTITY, [schemaexport] name VARCHAR(255) not null [schemaexport] unique (name) [schemaexport] ) ... [schemaexport] create table TRACK ( [schemaexport] Track_id INTEGER NOT NULL IDENTITY, [schemaexport] title VARCHAR(255) not null, [schemaexport] filePath VARCHAR(255) not null, [schemaexport] playTime TIME, [schemaexport] added DATE, [schemaexport] volume SMALLINT [schemaexport] ) ... [schemaexport] alter table TRACK_ARTISTS add constraint FK72EFDAD84C5F92B foreign key (TRACK_ID) references TRACK [schemaexport] alter table TRACK_ARTISTS add constraint FK72EFDAD87395D347 foreign key (ARTIST_ID) references ARTIST [schemaexport] create index ARTIST_NAME on ARTIST (name) [schemaexport] create index TRACK_TITLE on TRACK (title))
NOTE Cool! I didn't even know how to do some of that stuff in HSQLDB! Figure 4-1 shows HSQLDB's tree view representation of the schema after these additions. I'm not sure why two separate indices are used to set up the uniqueness constraint on artist names , but that seems to be an implementation quirk in HSQLDB itself, and this approach will work just fine. Figure 4-1. The HSQLDB graphical tree view of our updated schema 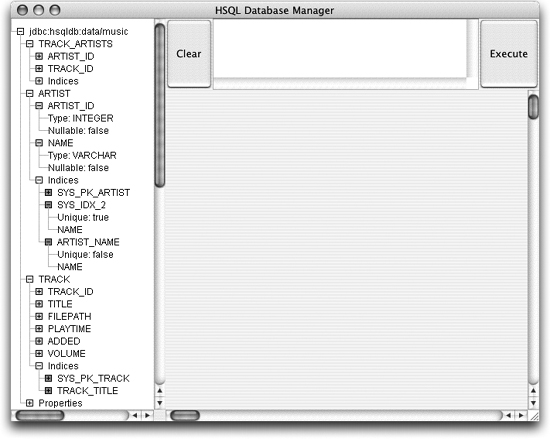
4.1.3 What just happened ? We've set up an object model that allows our Track and Artist objects to keep track of an arbitrary set of relationships to each other. Any track can be associated with any number of artists, and any artist can be responsible for any number of tracks. Getting this set up right can be challenging, especially for people who are new to object-oriented code or relational databases (or both!), so it's nice to have Hibernate help. But just wait until you see how easy it is to work with data in this setup. It's worth emphasizing that the links between artists and tracks are not stored in the ARTIST or TRACK tables themselves . Because they are in a many-to-many association, meaning that an artist can be associated with many tracks, and many artists can be associated with a track, these links are stored in a separate join table called TRACK_ARTISTS . Rows in this table pair an ARTIST_ID with a TRACK_ID , to indicate that the specified artist is associated with the specified track. By creating and deleting rows in this table, we can set up any pattern of associations we need. (This is how many-to-many relationships are always represented in relational databases; the chapter of Java Database Best Practices cited earlier is a good introduction to data models like this.) Keeping this in mind, you will also notice that our generated classes don't contain any code to manage the TRACK_ARTISTS table. Nor will the upcoming examples that create and link persistent Track and Artist objects. They don't have to, because Hibernate's special Collection classes take care of all those details for us, based on the mapping information we added to Example 4-2 and lines 23-27 of Example 4-1. NOTE Note to self: time to start selling coworkers on this Hibernate stuff! All right, let's create some tracks and artists.... |