| That was pretty easy, wasn't it? You'll be happy to learn that creating database tables is a very similar process. As with code generation, you've already done most of the work in coming up with the mapping document. All that's left is to set up and run the schema generation tool. 2.3.1 How do I do that? The first step is something we alluded to in Chapter 1. We need to tell Hibernate the database we're going to be using, so it knows the specific ' dialect ' of SQL to use. SQL is a standard, yes, but every database goes beyond it in certain directions and has a specific set of features and limitations that affect real-life applications. To cope with this reality, Hibernate provides a set of classes that encapsulate the unique features of common database environments, in the package net.sf.hibernate.dialect . You just need to tell it which one you want to use. (And if you want to work with a database that isn't yet supported 'out of the box,' you can implement your own dialect.) In our case, we're working with HSQLDB, so we want to use HSQLDialect . The easiest way to configure Hibernate is to create a properties file named hibernate.properties and put it at the root level somewhere in the class path . Create this file at the top level of your src directory, and put the lines shown in Example 2-4 into it. NOTE You can use an XML format for the configuration information as well, but for the simple needs we have here, it doesn't buy you anything. Example 2-4. Setting up hibernate.properties hibernate.dialect=net.sf.hibernate.dialect.HSQLDialect hibernate.connection.driver_class=org.hsqldb.jdbcDriver hibernate.connection.url=jdbc:hsqldb:data/music hibernate.connection.username=sa hibernate.connection.password=
In addition to establishing the SQL dialect we are using, this tells Hibernate how to establish a connection to the database using the JDBC driver that ships as part of the HSQLDB database JAR archive, and that the data should live in the data directory we've created ”in the database named music . The username and empty password (indeed, all these values) should be familiar from the experiment we ran at the end of Chapter 1.  | Notice that we're using a relative path to specify the database filename. This works fine in our examples ”we're using ant to control the working directory. If you copy this for use in a web application or other environment, though, you'll likely need to be more explicit about the location of the file. | |
You can put the properties file in other places, and give it other names , or use entirely different ways of getting the properties into Hibernate, but this is the default place it will look, so it's the path of least resistance (or, I guess, least runtime configuration). We also need to add some new pieces to our build file, shown in Example 2-5. This is a somewhat substantial addition, because we need to compile our Java source in order to use the schema generation tool, which relies on reflection to get its details right. Add these targets right before the closing </project> tag at the end of build.xml . Example 2-5. Ant build file additions for compilation and schema generation 1 <!-- Create our runtime subdirectories and copy resources into them --> 2 <target name="prepare" description="Sets up build structures"> 3 <mkdir dir="${class.root}"/> 4 5 <!-- Copy our property files and O/R mappings for use at runtime --> 6 <copy todir="${class.root}" > 7 <fileset dir="${source.root}" > 8 <include name="**/*.properties"/> 9 <include name="**/*.hbm.xml"/> 10 </fileset> 11 </copy> 12 </target> 13 14 <!-- Compile the java source of the project --> 15 <target name="compile" depends="prepare" 16 description="Compiles all Java classes"> 17 <javac srcdir="${source.root}" 18 destdir="${class.root}" 19 debug="on" 20 optimize="off" 21 deprecation="on"> 22 <classpath refid="project.class.path"/> 23 </javac> 24 </target> 25 26 <!-- Generate the schemas for all mapping files in our class tree --> 27 <target name="schema" depends="compile" 28 description="Generate DB schema from the O/R mapping files"> 29 30 <!-- Teach Ant how to use Hibernate's schema generation tool --> 31 <taskdef name="schemaexport" 32 classname="net.sf.hibernate.tool.hbm2ddl.SchemaExportTask" 33 classpathref="project.class.path"/> 34 35 <schemaexport properties="${class.root}/hibernate.properties" 36 quiet="no" text="no" drop="no" delimiter=";"> 37 <fileset dir="${class.root}"> 38 <include name="**/*.hbm.xml"/> 39 </fileset> 40 </schemaexport> 41 </target>
First we add a prepare target that is intended to be used by other targets more than from the command line. Its purpose is to create, if necessary, the classes directory into which we're going to compile, and then copy any properties and mapping files found in the src directory hierarchy to corresponding directories in the classes hierarchy. This hierarchical copy operation (using the special ' **/* ' pattern) is a nice feature of Ant, enabling us to define and edit resources alongside to the source files that use them, while making those resources available at runtime via the class loader. The aptly named compile target at line 14 uses the built-in java task to compile all the Java source files found in the src tree to the classes tree. Happily, this task also supports the project class path we've set up, so the compiler can find all the libraries we're using. The depends="prepare " attribute in the target definition tells Ant that before running the compile target, prepare must be run. Ant manages dependencies so that when you're building multiple targets with related dependencies, they are executed in the right order, and each dependency gets executed only once, even if it is mentioned by multiple targets. If you're accustomed to using shell scripts to compile a lot of Java source, you'll be surprised by how quickly the compilation happens. Ant invokes the Java compiler within the same virtual machine that it is using, so there is no process startup delay for each compilation. Finally, after all this groundwork , we can write the target we really wanted to! The schema target (line 26) depends on compile , so all our Java classes will be compiled and available for inspection when the schema generator runs. It uses taskdef internally at line 31 to define the schemaexport task that runs the Hibernate schema export tool, in the same way we provided access to the code generation tool at the top of the file. It then invokes this tool and tells it to generate the database schema associated with any mapping documents found in the classes tree. There are a number of parameters you can give the schema export tool to configure the way it works. In this example (at line 35) we're telling it to display the SQL it runs so we can watch what it's doing ( quiet="no" ), to actually interact with the database and create the schema rather than simply writing out a DDL file we could import later or simply deleting the schema ( text="no", drop="no" ). For more details about these and other configuration options, consult the Hibernate reference manual. | | You may be wondering why the taskdef for the schema update tool is inside our schema target, rather than at the top of the build file, next to the one for hbm2java. Well, I wanted it up there too, but I ran into a snag that's worth explaining. I got strange error messages the first time I tried to build the schema target, complaining there was no hibernate.properties on the class path and our compiled Track class couldn't be found. When I ran it again, it worked. Some detective work using ant -verbose revealed that if the classes directory didn't exist when the taskdef was encountered , Ant helpfully removed it from the class path. Since a taskdef can't have its own dependencies, the solution is to move it into the schema target, giving it the benefit of that target's dependencies, ensuring the classes directory exists by the time the taskdef is processed . | |
With these additions, we're ready to generate the schema for our TRACK table.  | You might think the drop="no" setting in our schema task means you can use it to update the schema ”it won't drop the tables, right? Alas, this is a misleading parameter name: it means it won't just drop the tables, rather it will go ahead and generate the schema after dropping them. Much as you want to avoid the codegen task after making any changes to the generated Java source, you mustn't export the schema if you've put any data into the database. Luckily, there is another tool you can use for incremental schema updates that works much the same way, as long as your JDBC driver is powerful enough. This SchemaUpdate tool can be used with an Ant taskdef too. | |
Because we've asked the schema export task not to be 'quiet,' we want it to generate some log entries for us. In order for that to work, we need to configure log4j , the logging environment used by Hibernate. The easiest way to do this is to make a log4j.properties file available at the root of the class path. We can take advantage of our existing prepare target to copy this from the src to the classes directory at the same time it copies Hibernate's properties. Create a file named log4j.properties in the src directory with the content shown in Example 2-6. An easy way to do this is to copy the file out of the src directory in the Hibernate distribution you downloaded, since it's provided for use by their own examples. If you're typing it in yourself, you can skip the blocks that are commented out; they are provided to suggest useful logging alternatives. Example 2-6. The logging configuration file, log4j.properties ### direct log messages to stdout ### log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.Target=System.out log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
### direct messages to file hibernate.log ### #log4j.appender.file=org.apache.log4j.FileAppender #log4j.appender.file.File=hibernate.log #log4j.appender.file.layout=org.apache.log4j.PatternLayout #log4j.appender.file.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n ### set log levels - for more verbose logging change 'info' to 'debug' ### log4j.rootLogger=warn, stdout log4j.logger.net.sf.hibernate=info ### log just the SQL #log4j.logger.net.sf.hibernate.SQL=debug ### log JDBC bind parameters ### log4j.logger.net.sf.hibernate.type=info ### log schema export/update ### log4j.logger.net.sf.hibernate.tool.hbm2ddl=debug ### log cache activity ### #log4j.logger.net.sf.hibernate.cache=debug ### enable the following line if you want to track down connection ### ### leakages when using DriverManagerConnectionProvider ### #log4j.logger.net.sf.hibernate.connection.DriverManagerConnectionProvider=trace
| | With the log configuration in place, you might want to edit the codegen target in build.xml so that it, too, depends on our new prepare target. This will ensure logging is configured whenever we use it, preventing the warnings we saw when first running it. As noted in the tip about class paths and task definitions in the previous section, though, to make it work the very first time you'll have to move the taskdef for hbm2java inside the codegen target, in the same way we put schemaexport inside the schema target. | |
Time to make a schema! From the project directory, execute the command ant schema . You'll see output similar to Example 2-7 as the classes directory is created and populated with resources, the Java source is compiled, [2.1] and the schema generator is run. [2.1] We're assuming you've already generated the code shown in Example 2-3, or there won't be any Java source to compile, and the schema generation will fail. The schema target doesn't invoke codegen to automatically generate code, in case you've manually extended any of your generated classes. Example 2-7. Output from building the schema using HSQLDB's embedded database server % ant schema Buildfile: build.xml prepare: [mkdir] Created dir: /Users/jim/Documents/Work/OReilly/Hibernate/Examples/ ch02/classes [copy] Copying 3 files to /Users/jim/Documents/Work/OReilly/Hibernate/ Examples/ch02/classes compile: [javac] Compiling 1 source file to /Users/jim/Documents/Work/OReilly/ Hibernate/Examples/ch02/classes schema: [schemaexport] 23:50:36,165 INFO Environment:432 - Hibernate 2.1.1 [schemaexport] 23:50:36,202 INFO Environment:466 - loaded properties from resource hibernate.properties: {hibernate.connection.username=sa, hibernate. connection.password=, hibernate.cglib.use_reflection_optimizer=true, hibernate. dialect=net.sf.hibernate.dialect.HSQLDialect, hibernate.connection.url=jdbc: hsqldb:data/music, hibernate.connection.driver_class=org.hsqldb.jdbcDriver} [schemaexport] 23:50:36,310 INFO Environment:481 - using CGLIB reflection optimizer [schemaexport] 23:50:36,384 INFO Configuration:166 - Mapping file: /Users/jim/ Documents/Work/OReilly/Hibernate/Examples/ch02/classes/com/oreilly/hh/Track.hbm. xml [schemaexport] 23:50:37,409 INFO Binder:225 - Mapping class: com.oreilly.hh. Track -> TRACK [schemaexport] 23:50:37,928 INFO Dialect:82 - Using dialect: net.sf.hibernate. dialect.HSQLDialect [schemaexport] 23:50:37,942 INFO Configuration:584 - processing one-to-many association mappings [schemaexport] 23:50:37,947 INFO Configuration:593 - processing one-to-one association property references [schemaexport] 23:50:37,956 INFO Configuration:618 - processing foreign key constraints [schemaexport] 23:50:38,113 INFO Configuration:584 - processing one-to-many association mappings [schemaexport] 23:50:38,124 INFO Configuration:593 - processing one-to-one association property references [schemaexport] 23:50:38,132 INFO Configuration:618 - processing foreign key constraints [schemaexport] 23:50:38,149 INFO SchemaExport:98 - Running hbm2ddl schema export [schemaexport] 23:50:38,154 INFO SchemaExport:117 - exporting generated schema to database [schemaexport] 23:50:38,232 INFO DriverManagerConnectionProvider:41 - Using Hibernate built-in connection pool (not for production use!) [schemaexport] 23:50:38,238 INFO DriverManagerConnectionProvider:42 - Hibernate connection pool size: 20 [schemaexport] 23:50:38,278 INFO DriverManagerConnectionProvider:71 - using driver: org.hsqldb.jdbcDriver at URL: jdbc:hsqldb:data/music [schemaexport] 23:50:38,283 INFO DriverManagerConnectionProvider:72 -connection properties: {user=sa, password=} [schemaexport] drop table TRACK if exists [schemaexport] 23:50:39,083 DEBUG SchemaExport:132 - drop table TRACK if exists [schemaexport] create table TRACK ( [schemaexport] TRACK_ID INTEGER NOT NULL IDENTITY, [schemaexport] title VARCHAR(255) not null, [schemaexport] filePath VARCHAR(255) not null, [schemaexport] playTime TIME, [schemaexport] added DATE, [schemaexport] volume SMALLINT [schemaexport] ) [schemaexport] 23:50:39,113 DEBUG SchemaExport:149 - create table TRACK ( [schemaexport] TRACK_ID INTEGER NOT NULL IDENTITY, [schemaexport] title VARCHAR(255) not null, [schemaexport] filePath VARCHAR(255) not null, [schemaexport] playTime TIME, [schemaexport] added DATE, [schemaexport] volume SMALLINT [schemaexport] ) [schemaexport] 23:50:39,142 INFO SchemaExport:160 - schema export complete [schemaexport] 23:50:39,178 INFO DriverManagerConnectionProvider:137 - cleaning up connection pool: jdbc:hsqldb:data/music BUILD SUCCESSFUL Total time: 10 seconds
Toward the end of the schemaexport section you can see the actual SQL used by Hibernate to create the TRACK table. If you look at the start of the music.script file in the data directory, you'll see it's been incorporated into the database. For a slightly more friendly (and perhaps convincing) way to see it, execute ant db to fire up the HSQLDB graphical interface, as shown in Figure 2-1. Figure 2-1. The database interface with our new TRACK table expanded, and a query 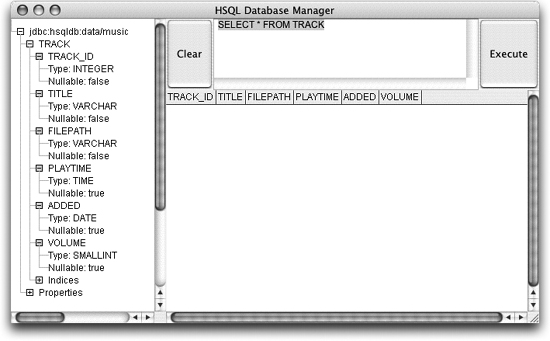
2.3.2 What just happened ? We were able to use Hibernate to create a data table in which we can persist instances of the Java class it created for us. We didn't have to type a single line of SQL or Java! Of course, our table is still empty at this point. Let's change that! The next chapter will look at the stuff you probably most want to see: using Hibernate from within a Java program to turn objects into database entries and vice versa. NOTE It's about time? Yeah, I suppose. But at least you didn't have to figure out all these steps from scratch! Before diving into that cool task, it's worth taking a moment to reflect on how much we've been able to accomplish with a couple of XML and properties files. Hopefully you're starting to see the power and convenience that make Hibernate so exciting. 2.3.3 What about... ...Other approaches to ID generation? Keys that are globally unique across a database or the world? Hibernate can support a variety of methods for picking the keys for objects it stores in the database. This is controlled using the generator tag, line 15 in Example 2-1. In this example we told Hibernate to use the most natural kind of keys for the type of database that it happens to be using. Other alternatives include the popular 'hi/lo' algorithm, global UUIDs, leaving it entirely up to your Java code, and more. See the 'generator' section in the Basic O/R Mapping chapter of the Hibernate reference documentation for details. And, as usual, if none of the built-in choices are perfect for your needs, you can supply your own class to do it exactly how you'd like, implementing the interface net.sf.hibernate.id.IdentifierGenerator and supplying your class name in the generator tag. |