9.6 Limitations of XML Canonicalization
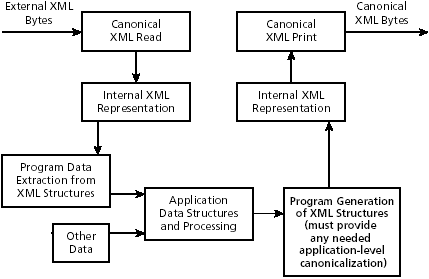
| XML canonicalization provides, where possible, a canonical form based on the XML and XML Namespace standards. That is, it strives to change all cases of the "same" XML, according to these standards, into identical sequences of octets. Of course, what is considered the "same" inherently depends on the particular application. Ignoring such issues as changes in ancestor bindings that appear not to be used in a subdocument to be signed, consider the foo2:bar element: <wrapper xmlns:foo2="http://example.com" xmlns:foo3="ftp://x.example"> <foo2:bar attribute="value">content</foo2:bar> </wrapper> If the foo2:bar element and its content are signed, should we assume that foo2 is intended to always represent the namespace to which it is bound in the start tag of the wrapper element? Even Exclusive XML Canonicalization would include the namespace binding of foo2 from the wrapper element, because it is visibly used. But suppose that the application merely thought of foo2 as a selector between the two namespaces bound to prefixes in a wrapper element start tag, with the other selector being foo3. The application designer might expect to be able to move this foo2:bar element to a different context, where foo2 and foo3 are bound to different namespace URIs, and have it select from the new pair of namespaces that also have bar elements. For example: <NewWrapper xmlns:foo2="https://10.1.2.3" xmlns:foo3="http://x42.net"> <foo2:bar attribute="value">content</foo2:bar> </NewWrapper> This way to use namespaces in an application might seem a little odd, but is certainly consistent with the way many people and XML standards view the "real" XML that is, as the surface character sequence. Conversely, other people and standards view the "real" XML as a logical tree structure without surface representation artifacts such as CDATA sections and namespace prefixes. The application designer might want to sign the foo2:bar element, send it in a message, verify the signature at the destination, and then insert it in a different wrapper for interpretation. To accomplish this goal without the XML subdocument being "changed" from this application designer's point of view, a custom canonicalization is needed. The two existing standard canonicalizations rely on the premise that they need to include the visibly used namespace binding in the foo2:bar start tag to avoid changing context effects. Of course, it is exactly those effects on which this application designer is counting in this hypothetical case! Canonicalization algorithms cannot read the application designer's mind, so the application designer must specify the appropriate canonicalization. Beyond this situation, in some cases canonicalization does not take into account some application-level equivalence as described in Section 9.6.1. Also, some important considerations arise with Unicode character normalization, which is deliberately left outside XML canonicalization (as discussed in Section 9.6.2). In addition, canonicalized XML may not always be operationally equivalent to its non-canonical input. Section 9.6.3 describes these situations and explains how to minimize the potential operational and security problems. Finally, the inclusion or exclusion of ancestor namespace declaration and/or xml namespace attributes can result in problems requiring adjustment, as described in Section 9.6.4. 9.6.1 Application EquivalencesOften, two instances of XML are equivalent from the point of view of an application but XML canonicalization does not turn them into the same external representation. For example, the following may have the same meaning for some applications but different meaning and effects for other applications: <ex> 1</ex> <!-- example A --> <ex>00001</ex> <!-- example B --> <ex>1.0e0 </ex> <!-- example C --> If examples A through C are passwords, they are very different. If A and B are just meant to be integers, they are the same. For a numeric calculator application that recognizes scientific notation, examples A through C may be the same. Usually no problems occur where XML simply flows through storage or communications channels and a signature is then verified. (See Figure 9-6.) For more complex protocol cases, where, for example, fields are stored in a database and later retrieved to reconstitute XML over which a signature is verified, applications usually must determine and rigorously adhere to their own canonical forms. (See Figure 9-8.) Figure 9-8. XML application processing and canonicalization
In the future, a "deeper" XML canonicalization may be specified based on knowledge of data types for XML content, perhaps derived from XML Schema [Schema]. 9.6.2 Character NormalizationCanonical XML does not perform Unicode character normalization. In many cases, multiple representations represent the "same" character for example a precomposed character versus a sequence. It is recommended that applications creating new XML always generate text in Unicode Normalization Form C [NFC]. It would be inappropriate for canonicalization to normalize characters within the Unicode domain for the following reasons:
Conversely, it is appropriate for an application to normalize characters upon their generation. An application is likely to know the appropriate NFC or other normalization it would like to use for its repertoire of characters. Also, it is easier to generate character-normalized text initially than it is to check for all possible non-normalized sequences and convert them to their normal form. 9.6.3 Operational NonequivalenceIt would be desirable for the replacement of XML by a canonicalization to have no application effect. This is particularly true because the XML digital signature, using a canonicalization, will not change if that canonicalization replaces a document or subset. Neither type of XML canonicalization makes a change when applied to output of that canonicalization, assuming that the comment inclusion flag remains the same in both cases. Thus the canoni calizations of the original XML and of the original XML with replacement canonicalization will be identical, as will their digital signatures. This signature equivalence could pose a security problem if the operational differences between the original and canonicalized XML violate a security policy, as signature checks would not detect them. The next three sections discuss particular cases where original and canonicalized XML may be operationally nonequivalent and suggest corrective actions that can be taken. Notations and Unparsed External EntitiesBecause XML canonicalization discards the DTD, NOTATION declarations are discarded along with the binding of such entities to a URI as well as the attribute type that binds the attribute value to an entity name. These features are rarely used, however, and it is recommended that applications use a URI attribute value to reference unparsed data. Attribute TypesBecause XML canonicalization eliminates XML DTDs, output will not include information about attribute types. For example, ID nodes no longer have that type, so XPath expressions over the output using the "id( )" function cease to operate, except for applications with built-in type knowledge. This problem does not arise with attributes of type ENTITY or ENTITIES. Entity replacement and the rules concerning notations and unparsed external entities cover such attributes. Applications for which DTD elimination might create a problem due to subsequent XML processing of canonical output can simply prefix that output with appropriate external and/or internal DTD information. Keep in mind that after adding such information, the output will no longer be canonical. Applications that are affected by DTD information should sign and verify the signature on such information as well as the signature on the XML to which the DTD applies. Relative URIsDocuments containing relative URIs have an operational meaning that depends on their base URI. The base URI is the URI used to access the document, except inside the scope of an xml:base attribute when xml:base is supported as described in Chapter 7. For example, if an XHTML Web page contains relative URI references to images, then the URI used to fetch the images depends on the URI used to access the initial Web page. In addition, if external general parsed entity references contain relative URIs, canonicalization will import such entities without changing the URIs. In the canonical form, the initial base URI for such external entities will be changed from the external entity location to the location of the XML into which canonicalization imports them. An application can overcome these problems in either of two ways:
9.6.4 Exclusion/Inclusion of Ancestor Namespace Declarations and xml Namespace AttributesAs mentioned previously, XML's correct operation may depend on making the appropriate choice between including and excluding namespace declarations and xml namespace attributes that appear on ancestor nodes above the portion of XML being canonicalized. The application designer must select a particular strategy: use Canonical XML, use Exclusive XML Canonicali zation, or use a "home brew" canonicalize. With the last choice, keep in mind that for any other process to verify the signature, it must implement the chosen canonicalization algorithm. If the designer chooses Canonical XML or Exclusive XML Canonicalization, other adjustments can be made as well. The XML being canonicalized may depend on the effect of xml namespace attributes, such as xml:lang and xml:space, appearing in ancestor nodes. To avoid problems due to the non-importation of such attributes into an enveloped document subset with Exclusive XML Canonicalization, the attributes must
Also, the XML being canonicalized may depend on the effect of XML namespace declarations where the namespace prefix being bound is not visibly utilized. For example, the evaluation of an attribute whose value is an XPath expression might depend on namespace prefixes referenced in that expression. To avoid problems with the omission of such namespace declarations due to Exclusive XML Canonicalization,
|

EAN: 2147483647
Pages: 186