9.1 CanonicalizationEssential for Signatures Over XML
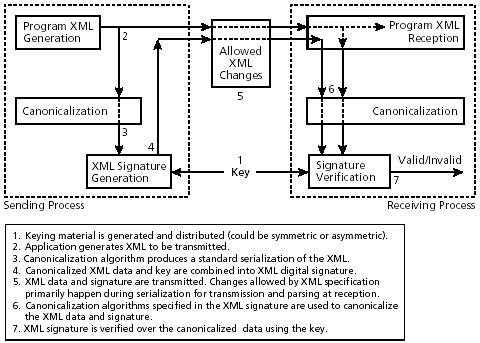
9.1 Canonicalization Essential for Signatures Over XMLAssume we have some data we want to sign. We calculate a digital signature, as described in Chapter 10, over the data using some key and algorithm. Next, we store the data and the digital signature or send them to another place. After subsequently retrieving or receiving the data, we expect the verification of the digital signature to indicate whether the data remains the "same." It might seem that what it means to say that two instances of XML are the "same" is clear. In the real world, however, this determination turns out to be a difficult question. The calculation of modern digital signatures involves signing a sequence of eight-bit binary bytes or octets. If the data being signed already consist of a fixed sequence of bytes (e.g., a JPEG image), then we're probably fine. But if the data actually consists of XML or even plain text, it is not so easy to ensure that the verifier will perform the verification calculations with the same sequence of octets used by the signer. See Figure 9-2. Figure 9-2. Canonicalization:XML signature over XML data
Let's look at some text as a simple example. If we send it from one application to another as text, quite often we find changes such as the following:
A signature calculated over text will not verify over the text modified in these ways because the modified text consists of a different byte sequence. Signing a canonical (or "normalized" or "standardized") form of the text solves this problem. For example, you might pick a standard line ending and convert all line endings to it, use a standard character encoding, or employ another tactic. Chapter 17 describes a Minimal Canonicalization, which does just that; it is appropriate for data treated as text but is inadequate for data treated as XML. With insufficient canonicalization, signatures become brittle. In such a case, any trivial change in the surface form of data will cause them to fail, even if the change is insignificant for that application. Conversely, with excessive canonicalization, signatures become insecure. A signature is then verifiable even after significant changes in the meaning of the data if excessive canonicalization discards those changes. For example, discarding accents on characters before they are fed into a signature algorithm would enable an attack, undetectable by signature checking, in which a name in a message is changed to refer to someone else whose name differs only in character accents. As you can see, achieving robust and secure signatures requires just the right canonicalization. 9.1.1 Some Simple Aspects of XML CanonicalizationXML is, of course, even more flexible than text. When it is being read, the XML Recommendation [XML] specifies which data passes to the application and which data is discarded. For example, it includes the following provisions:
XML canonicalization must precisely specify all choices for such discarded formatting. That way, if two instances of XML provide the same data to an application and their external representations are canonical, then their external representations will be byte-for-byte identical. As a result, a signature over one can be verified over the other representation. 9.1.2 The Problems with XML White SpaceReadable formatting is supposed to be an advantage of XML. If you use white space for formatting, three cases arise. Consider the example <a><b c="d">foo8 foo9</b><e f="ghijklmno">bar</e></a> where element "a" is specified in the DTD you are using as having only element content, not mixed element and text content. The first type of white space, which you can freely add, occurs in many places inside the start and end tag. For example, <a><b c="d" >foo8 foo9</b ><e f="ghijklmno" >bar</c ></a > is the same as the one-line example given earlier, according to the basic XML specification. The additional white space inside the start and end tags isn't passed to an application reading this XML, so it can't be significant. XML canonicalization simply specifies a fixed way of handling such spacing so that the XML is always serialized in the same way. To see the second type of white space, consider the following example: <a><b c="d"> foo8 foo9 </b><e f="ghijklmno"> bar </e></a> Here white space has been added to the actual text content. It is considered significant white space under the XML Recommendation [XML], must be passed along to the application exactly, and is not altered by XML canonicalization. Changing it will break a signature (unless, for example, you use a nonstandard canonicalization that strips all leading and trailing white space from text content and changes all internal runs of white space to, say, a single space). The trickiest case is the third and last type of white space. Consider the following example: <a> <b c="d">foo8 foo9</b> <e f="ghijklmno">bar</e> </a> Here white space has been added inside element "a" but outside the elements that are the content of "a". Because our DTD specified "a" to have only element content, this extra white space is considered insignificant. The XML recommendation, however, requires that it be passed to the application, albeit flagged as "insignificant." Thus an application can act as it chooses when it encounters such white space. Furthermore, if the DTD had provided that "a" had mixed content (text and elements), this white space would be significant. If the DTD is not accessible and we use a nonvalidating parser, we would have no way of telling the status of this white space! XML canonicalization has chosen to handle this problem by assuming that the second and third types of white space must be exactly retained and serialized unchanged from their appearance in the text nodes of an input XPath node-set. 9.1.3 The Problems with XML NamespacesXML namespaces [Names] enrich XML but also provide another range of options that appear, by definition, identical in meaning. For example, a namespace prefix declaration affects all child nodes unless a child node re declares the prefix. Thus, if a namespace is set up at the apex node of some XML and child nodes do not redeclare the prefix, then it is immaterial whether redundant identical declarations of that prefix also appear in the children. Are the prefixes themselves significant? You might think not, assuming that they are just dummy symbols bound to a URI. In reality, XPath and other expressions can explicitly match prefix names, and such expressions can appear inside attribute values or text content or even be calculated dynamically. For this reason, in general, you must consider namespace prefix names to be significant and not altered by canonicalization.
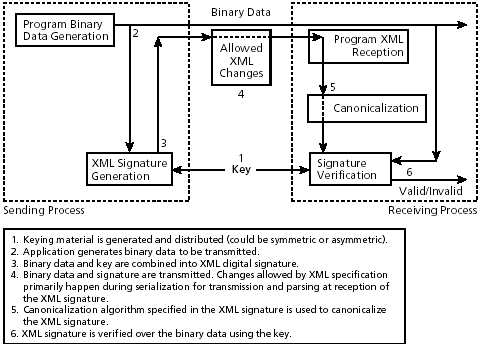
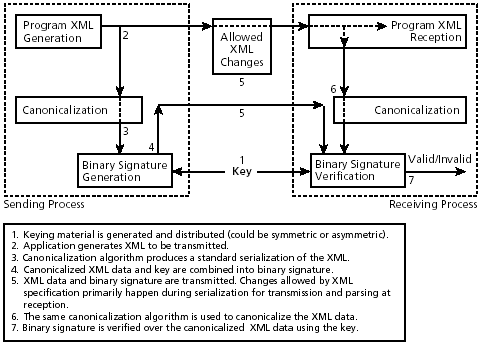
As references to namespace prefixes can lurk in text, attribute values, and other locations, it is generally impossible to determine algorithmically whether a namespace prefix is actually referenced by some XML. On the other hand, problems can arise if you assume that all namespace declarations in scope might be used and so need to be copied into a descendant element, if that element and its content are being canonicalized. In particular, if the element moves to a different ancestor context, as frequently happens with protocols, its canonicalization may change because different namespace declarations are inherited from ancestors. A signature over it will then break. A Simple ExampleFor an example of the type of problem that changes in XML context can cause for signatures, consider the following: <n1:elemX xmlns:n1="http://b.example"> content </n1:elemX> It is then wrapped in another element: <n0:pdu xmlns:n0="http://a.example"> <n1:elem1 xmlns:n1="http://b.example"> content </n1:elem1> </n0:pdu> The first XML code appears in canonical form. Assume, however, that the XML is wrapped as in the second case for protocol transmission. The subdocument with elem1 as its apex node can then be extracted with an XPath expression: (//. | //@* | //namespace::*)[ancestor-or-self::n1:elem1] In this expression, the parenthesized part selects every node; the predicate in square brackets filters these nodes to those with the name or with an ancestor with the name "elem1" (Chapter 6). Applying Canonical XML, which is inclusive, to the XPath node-set created in this way gives the following (except for line wrapping to fit this document): <n1:elem1 xmlns:n0="http://a.example" xmlns:n1="http://b.example"> content </n1:elem1> Note that Canonical XML has included the n0 namespace because it includes namespace context. This change would mean that a signature over "elem1" based on the first, unwrapped instance would not be verifiable. General Problems with ReenvelopingAs a more complete example of the changes in the Canonical XML form that can occur when you change the enveloping context of an element, consider the following: <!-- Case one --> <n0:local xmlns:n0="foo:bar" xmlns:n3="ftp://example.org"> <n1:elem2 xmlns:n1="http://example.net" xml:lang="en"> <n3:stuff xmlns:n3="ftp://example.org"/> </n1:elem2> </n0:local> The following case arises when you change the enveloping of elem2: <!-- Case two --> <n2:pdu xmlns:n1="http://example.com" xmlns:n2="http://foo.example" xml:lang="fr" xml:space="retain"> <n1:elem2 xmlns:n1="http://example.net" xml:lang="en"> <n3:stuff xmlns:n3="ftp://example.org"/> </n1:elem2> </n2:pdu> Assume that you produce an XPath node-set from each of these two cases by applying the following XPath expression: (//. | //@* | //namespace::*)[ancestor-or-self::n1:elem2] Applying Canonical XML to the node-set produced from the first XML code yields the following serialization (except for line wrapping to fit in this document): <n1:elem2 xmlns:n0="foo:bar" xmlns:n1="http://example.net" xmlns:n3="ftp://example.org" xml:lang="en"> <ns3:stuff></ns3:stuff> </n1:elem2> Although the identical octet sequence in both pieces of external XML above represents elem2, the Canonical XML version of elem2 from the second case would be (except for line wrapping so it will fit into this document) as follows: <n1:elem2 xmlns:n1="http://example.net" xmlns:n2="http://foo.example" xml:lang="en" xml:space="retain"> <n3:stuff xmlns:n3="ftp://example.org"></n3:stuff> </n1:elem2> The change in context produces many changes in the subdocument as serialized by the inclusive Canonical XML. In the first example, "n0" has been included from the context, and the presence of an identical "n3" namespace declaration in the context has elevated that declaration to the apex of the canonicalized form. In the second example, "n0" has gone away but "n2" has appeared, "n3" is no longer elevated, and an xml:space declaration has appeared, due to changes in context. Not all context changes have an effect, however. In the second example, the presence at ancestor nodes of an xml:lang and "n1" prefix namespace declaration has no effect because of existing declarations at the elem2 element. This sort of change of context is typical of protocols and can easily lead to signatures that can not be validated. To help with this situation, Exclusive XML Canonicalization [Exclusive] is used. The physical form of elem2 as extracted by the XPath expression above and then subjected to Exclusive XML Canonicalization is, in both cases (except for line wrapping so it will fit into this document), as follows: <n1:elem2 xmlns:n1="http://example.net" xml:lang="en"> <n3:stuff xmlns:n3="ftp://example.org"></n3:stuff> </n1:elem2> As you see, a signature using Exclusive XML Canonicalization would not be broken by the change in context and would be verifiable. 9.1.4 Canonicalization Is Required for XML DataXML canonicalization is more complex than the previous discussion has suggested, as will be explained later. When we are concerned with XML dig ital signatures, at least part of the signature itself must be canonicalized, because it is XML, as must the signed data if it is being handled as XML. See Figures 9-2 and 9-3. Even if a binary format signature, such as PKCS#7 [RFC 2315], is calculated over XML data that is being handled as XML, canonicalization remains vital because such XML handling can change the surface form of the XML, as shown in Figure 9-4. Figure 9-3. Canonicalization: XML signature over binary data
Figure 9-4. Canonicalization: binary signature over XML data
|
EAN: 2147483647
Pages: 186