2.4 HTTP, Pre-WebDAV
| The Web was always intended to be a read-and-write publishing medium. Tim Berners-Lee explained how users should be able to correct errors in Web pages or add to them simply by clicking in their browser window and beginning to edit. Why didn't the Web fulfill its writability promise for seven Web years (equivalent to 49 regular technology years)? Isn't it reasonable that once browsers became sophisticated enough to support remote editing with secure authentication, HTTP would take off as an authoring protocol as well? To answer these questions, one has to consider HTTP's characteristics in rather specific terms. Chapter 4, Data Model, covers HTTP in enough detail to explain anything that might be confusing in the following section. However, even without being familiar with HTTP or having read Chapter 4, you should find the gist of the arguments clear. 2.4.1 Obvious Missing FeaturesA comparison of HTTP to WebDAV suggests that HTTP lacked important authoring features, because WebDAV added these features. Or is it so clear? The WebDAV Working Group argued at length about some seemingly obvious features, with the intent to keep the protocol as simple as it could be but not too simple. Mercifully, I'll rehash the arguments quickly. How to Create a CollectionThere is no way to create a new collection in HTTP without WebDAV. The Web server administrator has to create a new collection in the underlying file system, probably by logging on to the Web server locally or remotely. Since not all Web authors have administrator privileges, this requirement can present a barrier. Copy OperationHTTP has the GET and PUT methods. By performing a GET on the source resource, then a PUT of the same content to a new location, the client can get the same result as a COPY method. The argument for defining an explicit COPY method lies in conserving both bandwidth and latency. For small files, the GET and the PUT are two roundtrips, or twice as much latency. For larger files, the GET and the PUT can consume vastly more bandwidth than the COPY request.
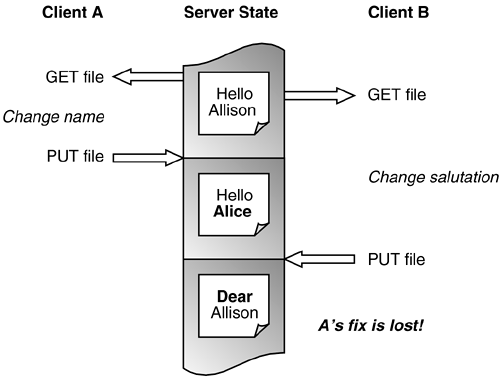
Move and RenameHTTP doesn't have a move or rename method, as most document management systems and file systems do. A client can perform a copy operation and then delete the original resource (assuming the COPY request is added to HTTP). However, this doesn't quite do the same thing a move operation would do. If a client tries to do a move operation without assistance from the server, metadata from the original resource is lost. For example, the creationdate property will be a new value if the resource is created from scratch with GET or COPY. If the server supports a move operation, then the resource can keep the more useful value, the time when the resource was originally created. Standardized Content ListingsThere was no standard way to list collection contents in HTTP. Most Web servers create an HTML content listing when a user tries to download a collection using the GET method. However, each server has a different HTML format for this information, and many even contain different content. Clients do not attempt to parse those formats and thus cannot determine what resources exist in a collection. 2.4.2 ETags and the Lost Update ProblemWhen one user overwrites another user's changes by accident, this is called the lost update problem. The first user's update is the one that is lost (see Figure 2-1). Figure 2-1. Lost update problem.
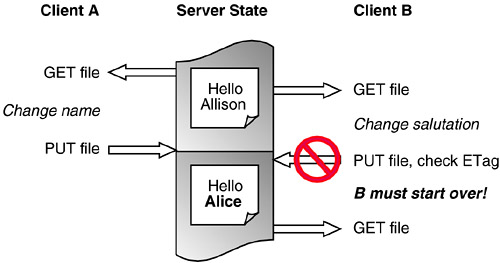
The HTTP Entity Tag, or ETag, feature was thought to have the potential to prevent the lost update problem, but ETags do not solve it satisfactorily. This section explains how ETags work, what the lost update problem is, and where ETags fall short in solving the problem. The designers of HTTP went to a great deal of trouble to design mechanisms to tell when a file is changed. A client need not download a page if it has been downloaded before, saved in a local cache, and hasn't changed since. Avoiding these unnecessary downloads can make Web surfing much faster, and ETags help avoid unnecessary downloads. ETags are used to compare two or more entities from the same resource. If a current ETag matches an earlier ETag from the same resource, then the resource has the same content it did before. For example, clients frequently compare an ETag saved for a cached file to the ETag for the server's latest version of that file. If the ETag is different, then the file must be downloaded again. If the ETag is the same, then the cached resource can be used. It's also possible to use ETags to avoid the worst of the lost update problem. An authoring application that expects to be the only application changing a resource would simply do GET, allow the user to perform edits, and then do a PUT request to change the original resource. However, when there are other authors involved, the authoring application needs to check whether the resource has been changed since the GET operation, using ETags of course. ETags prevent accidental overwrites because they already exist to see if the resource has changed. For details on how HTTP uses ETags, see the explanation of the If-Match header in Chapter 3, HTTP Mechanics. The W3C has a very good note [Nielsen99] on using ETags to detect the lost update problem. However, ETags don't solve the "aggravated user" problem illustrated in Figure 2-2. A user can work for hours editing a Web page, only to find that the file has changed and she may have to start again with the latest content. From a distributed authoring point of view, that's not good enough. There must be a way for the user to block other users making changes for a while. Figure 2-2. ETags prevent lost updates but not wasted time.
|
EAN: N/A
Pages: 146
- Integration Strategies and Tactics for Information Technology Governance
- Measuring and Managing E-Business Initiatives Through the Balanced Scorecard
- A View on Knowledge Management: Utilizing a Balanced Scorecard Methodology for Analyzing Knowledge Metrics
- The Evolution of IT Governance at NB Power
- Governance Structures for IT in the Health Care Industry