Section 9.2. Toolkit Modules
9.2 Toolkit ModulesThe supporting modules listed in Table 9-6 are described in the following sections. Over the next few chapters we'll work through the scripts supported by these modules. 9.2.1 PDBA::CM (Connection Manager)The PDBA::CM module is the connection manager for the toolkit. This module makes connections to Oracle databases via the Perl DBI and DBD::Oracle modules. PDBA::CM also allows you to predefine Oracle environment variables ; we'll explain how in the installation instructions for this module later in the chapter. Why is CM necessary? To see why, we'll first see how Perl DBI makes the connection to Oracle without CM. Because we're only interested in connecting to Oracle databases, we can safely override or "subclass" the Perl DBI connect method with the PDBA::CM module. This provides our own Oracle-optimized method. Why would we want to do that? If you choose to configure the optional PDBA::CM configuration file, you can let it set up the Oracle environment for you. First let's look at what's involved in setting up the environment on your own. Before running an ordinary standalone Perl script for Oracle, you would usually need to set up the environment as shown in the following example: $ export ORACLE_SID=mydb $ export ORACLE_HOME=/u01/app/oracle/product/8.1.7 $ export ORACLE_BASE=/u01/app/oracle/ $ export TNS_ADMIN=/u01/app/oracle/product/8.1.7/network/admin A regular Perl DBI script then connects to the target database like this: my $db = $ENV{ORACLE_SID} my $username = 'scott'; my $password = 'tiger'; my $dbh = DBI->connect('dbi:Oracle:' . $db, $username, $password, { RaiseError => 1, AutoCommit => 0 }); By using PDBA::CM and setting its configuration file, you avoid this environmental overhead: my $db = 'orcl'; my $username = 'scott'; my $password = 'tiger'; my $dbh = new PDBA::CM (DATABASE=>$db, USERNAME=>$username, PASSWORD=>$password); Here are the main differences between using CM and configuring on your own:
We'll look at a few special cases in the following sections. 9.2.1.1 Special login cases for SYSDBA and SYSOPERAs we describe in Appendix B, if you need to connect via Perl DBI as SYSDBA or SYSOPER, you must explicitly indicate it. Here's how SQL*Plus does it: sqlplus "system/manager as sysdba" To do this in Perl DBI, you alter the login sequence as follows : $dbh = DBI->connect('dbi:Oracle:' . $db, $username, $password, {RaiseError => 1, AutoCommit => 0, ora_session_mode => 2 }); What is happening here?
In our PDBA::CM , you only need to set the MODE attribute to one of two valid values: $dbh = new PDBA::CM (DATABASE=>$db, USERNAME=>$username, PASSWORD=>$password, MODE=>'SYSOPER'); # Or SYSDBA! :-) 9.2.1.2 RaiseError and AutoCommitAll connections to Oracle databases established via the CM module set the class attribute RaiseError to 1, and AutoCommit to 0. This is done for the following reasons:
9.2.2 PDBA::DBA (DBA Methods )The PDBA::DBA module stores methods that can be used by the toolkit to simplify routine Oracle database administration tasks. Although each of these individual tasks might be perfectly straightforward, as such tasks accumulate most DBAs end up spending much too much valuable time writing one-off scripts. PDBA::DBA aims to remedy this situation. 9.2.2.1 Creating user accountsOne good example of a typical one-off DBA task is the creation of a new user account. You may already possess several tools for creating new users. User creation can be a rather cumbersome process. Depending on the target application, there are often numerous privilege sets that need to be assigned to various application roles. To complicate matters, users may need multiple roles assigned in ways that are difficult to predict ahead of time. You'll start developing a particularly bad headache when you're responsible for several applications. Worse still, this labor- intensive work is quite prone to human error. Our PDBA::DBA module can automate all of these complexities and remove the chance for error. Here's an example of how you can use this module's new method to duplicate a user account. $ dup_user.pl -machine turing -database orcl -username scott \ -new_username scott -source_user samantha This example creates user scott in the database orcl . A password is generated for the new scott account, and the account receives the same privileges as the source user ” in this case, samantha . You can also use PDBA::DBA directly within Perl scripts of your own: my $newUser = new PDBA::DBA ( DBH => $dbh, OBJECT_TYPE => 'user', OBJECT => 'alicia', PASSWORD => 'generate', DEFAULT_TABLESPACE => 'users', TEMPORARY_TABLESPACE => 'temp', PRIVS => ['create session', 'resource', 'connect', 'oem_monitor'], QUOTAS => { users => 'unlimited', tools => '10m', indx => 'unlimited'} ); eval { $newUser->create }; if($@) { warn "error creating user: $DBI::errstr\n" } else { print "Password: $newUser->{PASSWORD}\n" } The main PDBA::DBA methods are summarized in Table 9-7. Table 9-7. Main PDBA::DBA module methods
9.2.3 PDBA::ConfigFile (Configuration File Handler)The PDBA::ConfigFile module plays a very important part in the PDBA Toolkit. It facilitiates the creation of powerful and robust scripts that are driven by a configuration file. If you need to change a script's purpose, all you need do is change the configuration file. 9.2.3.1 Simplifying configurationFirst let's look at a script that uses a configuration file, on execution, without PDBA::ConfigFile : $ myscript1.pl -conf $HOME/pdba/myconfig.conf The bare bones myscript1.pl script is shown in Example 9-1. Example 9-1. myscript1.pl ” Opening a configuration file with standard Perl #!/usr/bin/perl use Getopt::Long; my %optctl=( ); GetOptions(\%optctl, "conf=s"); my $configFile=''; my $fh; if ( exists $optctl{conf} ) { $configFile = exists $optctl{conf}; # Exit, if you can't read the file. unless( -r $configFile ){ die "cannot read the config file, $configFile - $!\n"; }; $fh = new IO::File; $fh->open($configFile) die "Cannot open $configFile - $!\n" } else { die "please specify a configuration file!\n"; } There are a number of drawbacks to this approach:
Here's an example of doing much the same thing with PDBA::ConfigFile : $ myscript2.pl -conf myconfig.conf This executes myscript2.pl in Example 9-2. Notice that there is a lot less script code. Example 9-2. myscript2.pl ” Opening a configuration file with PDBA::ConfigFile#!/usr/bin/perl use PDBA::ConfigFile; use Getopt::Long; my %optctl=( ); GetOptions(\%optctl, "conf=s"); my$configFile='mytest.conf'; my $fh; unless ( $fh = new PDBA::ConfigFile( FILE => $configFile ) ){ die "failed to open $configFile\n"; } 9.2.3.2 Automatic file searchingIn cases where you don't specify a full OS path, PDBA::ConfigFile checks in several places for your config file:
9.2.4 PDBA::ConfigLoad (Configuration File Loader)The PDBA::ConfigLoad module finds your configuration file and loads it for you. In doing this, it assumes that the configuration information is structured as Perl code. This provides several advantages:
Let's consider the example of an old-fashioned configuration file:
Let's examine what these requirements entail in a typical configuration file in Example 9-3. Example 9-3. Old-fashioned colon -separated configuration file# tables: object type:database:tablespace:pctfree:pctused:initial:next table:default:users:60:10:128k:128k table:dw:dwload:10:5:128m:128m # indexes: object type:database:tablespace:pctfree:initial:next index:default:indx:5:128k:128k index:dw:load_idx:5:4m:4m # users: object type:database:tablespace:temp tablespace:privs:quotas # privs must be separated by commas # quotas must be in tablespace/space usage pairs, all comma separated user:default:users:temp:connect,resource:users,10m,indx,5m user:dw:dw_users:dw_temp:create session,dw_user:dw_users,200m,dw_indx,100m As Morpheus might have said to Neo in The Matrix , "Do you think that's easy to read, or modify?" If you were to use this configuration file, you'd also need to write some complex code to parse it. Contrast this to the Perl configuration script in Example 9-4. Each component is clearly labeled, as in a tnsnames.ora file structure, and when you need to add to this configuration file, it's a simple matter of pasting in appropriate values. Example 9-4. New-fangled Perl script configuration file package dbparms; use vars qw(%defaults); %defaults = ( table => { default => { tablespace => 'users', pctfree => 60, pctused => 10, initial => '128k', next => '128k' }, dw => { tablespace => 'dw_load', pctfree => 10, pctused => 5, initial => '128m', next => '128m' }, }, index => { default => { tablespace => 'index', pctfree => 5, initial => '128k', next => '128k' }, dw=> { tablespace => 'load_idx', pctfree => 5, initial => '4m', next => '4m' }, }, user => { default => { default_tablespace => 'users', temporary_tablespace => 'temp', privs => ['connect', 'resource'], quotas => { users => '10m', indx => '5m' } }, dw=> { default_tablespace => 'dw_users', temporary_tablespace => 'dw_temp', privs => ['create session', 'dw_user'], quotas => { dw_users => '200m', dw_indx => '100m' } }, }, ); 9.2.4.1 Loading a Perl configuration scriptCoincidentally, it's also easier to load into a Perl script using PDBA::ConfigLoad : use PDBA::ConfigFile; my $nf = new PDBA::ConfigLoad( FILE => 'nf.conf' ); unless ( $nf ) { die "failed to load\n " } That's all there is to it. Three lines of Perl makes your configuration file loaded and ready to use. The data structure for your configuration files is defined and documented, and there's an added silver- lining benefit as well; it's also now a simple matter to check your configuration file for syntactical correctness. Here's how: perl -cw myconfig.conf # -c, checks syntax, -w, looks for warnings Because this is a Perl script, Perl will throw an error if the file fails to compile. So how do you access all of these configuration parameters? It's easier than you might think. The following script will print some of the values loaded in the previous example: $dwprivs = join(', ', @{ $dbparms ::defaults{user}->{dw}{privs}}); %dwquotas = %{ $dbparms ::defaults{user}->{dw}{quotas}}; print qq { user defaults for dw: default tablespace : $dbparms ::defaults{user}->{dw}{default_tablespace} temporary tablespace: $dbparms ::defaults{user}->{dw}{temporary_tablespace} }; print "privs: $dwprivs\n"; print "\ntablespace quotas\n"; for my $tbs ( keys %dwquotas ) { print "\ttbs: $tbs quota: $dwquotas{$tbs}\n"; } Here's the output from the preceding script, using the configuration file in Example 9-4: user defaults for dw: default tablespace : dw_users temporary tablespace: dw_temp privs: create session, dw_user tablespace quotas tbs: dw_users quota: 200m tbs: dw_indx quota: 100m (Appendix A, walks through the concepts that underly the discussion in this section; see particularly its discussions of anonymous arrays and references.) 9.2.4.2 Referring to configuration variables by package nameTake another look at our first line in Example 9-4: package dbparms; By packaging the configuration variables in this way, we also remove the possibility of overwriting variables in the main script, because they're in a different namespace. In Perl's use strict mode, every variable has to be referred to by its package name, dbparms , and its variable name. For example, the %defaults hash is accessed by %dbparms::defaults . (Again, refer to Appendix A if you are confused by all this.) 9.2.5 PDBA::Daemon and Win32::Daemon (Background Programs)The PDBA::Daemon module (and its Win32 partner, Win32::Daemon ) create background, server-like programs. These are programs that you start once; they then continue to run in the background without any necessary user interaction, and they continue to run until you explicitly tell them to stop. These background programs differ for Unix and Win32:
We'll look first at creating a daemon process in Unix and later turn our attention to Win32. 9.2.5.1 PDBA::Daemon: Creating a Unix daemon process in PerlThere are a few basic rules you will need to follow when creating simple daemon processes on Unix:
This is all done easily, within a few lines of Perl: if ($pid = fork ) { exit 0 } # exit parent if (defined($pid )) { close STDOUT; close STDIN; chdir('/'); croak "Cannot detach from terminal" unless $sess_id = POSIX::setsid( ); return $pid; } if (++$tries>5 ) { die "fork failed after $tries attempts: $!\n" } else { sleep 3; redo; } } Let's see what's going on here:
Let's demonstrate a short daemon script in Example 9-5. Example 9-5. daemon_test.pl ” Example Perl daemon #!/usr/bin/perl use warnings; use PDBA::Daemon; use IO::File; my $logFile = '/tmp/daemon_test.log'; my $lh = new IO::File; $lh->open("+> $logFile" ) die "unable to create log file $logFile - $!\n"; &PDBA::Daemon::daemonize; for ( my $i = 0; $i < 5; $i++ ) { my ($sec,$min,$hour) = localtime(time); my $output = sprintf("%02d:%02d:%02d\n", $hour,$min,$sec); $lh->printflush($output); sleep 5; } $lh->close; You can check this background daemon's progress, once it has been started, by tailing its log file as follows: $ ./daemon_test.pl $ tail -f /tmp/daemon_test.log 21:43:39 21:43:44 ... A little code, and one call to PDBA::Daemon::daemonize , and you have an independent Perl daemon up and running. This is an extremely useful feature, as we'll see later. 9.2.5.2 Win32::Daemon: Creating a Win32 daemon in PerlWin32 also has background processes, better known as services . Win32 services are implemented differently than Unix daemons. Therefore, our standard daemon creation operation via PDBA::Daemon needs adjustment. Enter the Win32::Daemon module, a brilliant piece of software created by Win32 Perl guru Dave Roth of Roth Consulting. This module creates system services written entirely in Perl and is available from http://www.roth.net. We'll show you how to install it later in this chapter.
Win32 service scripts look substantially different from daemonized Unix scripts, as Example 9-6 shows. Example 9-6. Win32 service script use Win32; use Win32::Daemon; # http://www.roth.net! :-) use IO::File; my $attempts; Win32::Daemon::StartService( ); sleep( 1 ); my $lh = new IO::File; my $logFile = "c:/temp/daemon_test.log"; $lh->open($logFile) die; LOG($lh, "Service Starting - State is: " . $State); while( SERVICE_START_PENDING != Win32::Daemon::State( ) ) LOG($lh, "Waiting for service - state is: " . $State . "..." ); sleep( 1 ); if ( $attempts++ > 15 ) { LOG("Failed to start service in " . $attempts . " attempts"); Win32::Daemon::State(SERVICE_STOPPED); Win32::Daemon::StopService( ); exit 2; } $State = Win32::Daemon::State( ); } Win32::Daemon::State(SERVICE_RUNNING); $State = Win32::Daemon::State( ); LOG($lh, "Service Started - State is: " . $State); while (1) { # Main loop! 8-) # check for Win32 Service state my $PrevState = SERVICE_RUNNING; while( SERVICE_STOPPED != ( $State = Win32::Daemon::State( ) ) ) { if( SERVICE_RUNNING == $State ) { LOG($lh, "Service running"); last; } elsif( SERVICE_PAUSE_PENDING == $State ) { # "Pausing..."; LOG($lh, "Pausing Service"); Win32::Daemon::State( SERVICE_PAUSED ); $PrevState = SERVICE_PAUSED; next; } elsif( SERVICE_CONTINUE_PENDING == $State ) { # "Resuming..."; LOG($lh, "Resuming Service"); Win32::Daemon::State( SERVICE_RUNNING ); $PrevState = SERVICE_RUNNING; last; } elsif( SERVICE_STOP_PENDING == $State or SERVICE_CONTROL_SHUTDOWN == $State ) { # "Stopping..."; LOG($lh, "Stopping Service"); # Tell the OS that the service is terminating... Win32::Daemon::State(SERVICE_STOPPED); Win32::Daemon::StopService( ); exit 8; last; } else { # We have some unknown state... # reset it back to what we last knew the state to be... LOG($lh, "Unknown State of : " . $State . " - exiting..."); Win32::Daemon::State(SERVICE_STOPPED); Win32::Daemon::StopService( ); exit 8; last; } sleep 1; } LOG($lh, "Main Loop"); sleep 1; } ######################## sub LOG { my($lh) = shift; my @msg = @_; my( $sec, $min, $hour, $mday, $mon, $year, $wday, $yday, $isdst ); # mon = 0..11 and wday = 0..6 ($sec, $min, $hour, $mday, $mon, $year, $wday, $yday, $isdst) = localtime(time); # change $mon to 1-12 and $wday to 1-7; $mon++; # to get it to agree with the cron syntax $day++; $year += 1900; # Y2K fix $lh->printflush("%04d/%02d/%02d %02d:%02d:%02d: %s\n", $year,$mon,$mday,$hour,$min,$sec,@msg); } As you can see, setting up Win32 services is an involved process ” and remember that Win32::Daemon has sheltered you from the really gory internals! 9.2.5.3 Using Unix Daemons and Win32 services in PerlNow that you have some grasp of Unix daemons and Win32 services, let's consider why you would want to use them in the first place. In this chapter, we'll focus on how they can help to automate as many Oracle DBA tasks as possible:
Running Unix daemons and Win32 services also helps us maintain those two commandments tattooed in deep purple on a DBA's soul:
Unless it's an acceptable plan to manually check alert.log for each database, you'll want to automate these processes. To do this, many shops run cron or at scripts, with names like every10 or LifeSaver . These run every few minutes, attempting database connections, and they notify the DBA if problems occur. In Chapter 11 we'll present a better method of checking the alert logs, using Perl of course. It's a better method because it allows you to determine which errors are of importance to you, paging the DBA only when necessary. It will be flexible, will be easy to set up, and will avoid the straitjacket of a rigidly bound cron schedule. 9.2.6 PDBA::GQ (Generic Query)DBAs often open cursors to single tables (such as DBA_TABLES), read in some rows from it, get the column values, and then process the data in some way. If you do this routine often enough, you'll soon tire of its repetitive nature, even if you're just cutting and pasting queries from prestored SQL scripts. The PDBA::GQ module is designed to streamline this task. The module's main methods are listed in Table 9-8. Table 9-8. PDBA::GQ module methods
The standard DBI query method often uses bind variables in the following way: my $sql = q{ select object_name, created, last_ddl_time from dba_objects where owner = ? and object_type = ? }; my @bindparms = qw(SCOTT TABLE); my $sth = $dbh->prepare($sql); mu $rv = $sth->execute( @bindparms ); while ( my $hashRef = $sth->fetchrow_hashref ) { print "Object: $hashRef->{OBJECT_NAME}\n"; print "Created on : $hashRef->{CREATED}\n"; print "Last DDL Time : $hashRef->{LAST_DDL_TIME}\n"; } PDBA::GQ can help simplify that approach as follows: my @bindparms = qw(SCOTT TABLE); my $dbaObj = new PDBA::GQ { $dbh, "dba_objects", { WHERE => "owner = ? and object_type = ?", BINDPARMS => \@bindparms } }; while ( my $row = $dbaObj->next ) { print "Object: $row->{OBJECT_NAME}\n"; print "Created on : $row->{CREATED}\n"; print "Last DDL Time : $row->{LAST_DDL_TIME}\n"; } Note how the PDBA::GQ module saves us several steps from the previous code snippet:
PDBA::GQ uses several Perl DBI methods for returning data from Oracle (all of these are fully described in Appendix B).
The default return value for PDBA::GQ 's all method is a reference to an array of hash references. Example 9-7 uses this approach. The memory structure is displayed in Figure 9-1. Example 9-7. GQ::all ” Returning a reference to array of hashrefs my $vobj = new PDBA::GQ( $dbh, 'v$parameter', { WHERE => q{name like 'job%'} } ); # Default is reference to an array of hash references. my $arrayref = $vobj->all; # Print it out. for my $row ( @$arrayref ) { print "PARM: $row->{NAME} VALUE: $row->{VALUE}\n"; } Figure 9-1. An array reference to a list of hashes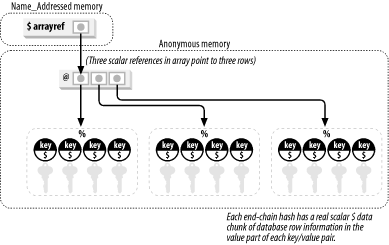 We can change this default memory structure by using the [ ] anonymous array notation. Example 9-8 shows the same query, this time with data returned as a reference to an array of array references. (Again, for more about this and other Perl DBI topics, see Appendix B.) Example 9-8. GQ::all ” returning a ref to array of array refs my $vobj = new PDBA::GQ( $dbh, 'v$parameter', { WHERE => q{name like 'job%'} } ); # Send an empty array reference, as an argument to indicate # the requested return type of data. my $arrayRowRef = $vobj->all([]); my $colNames = $vobj->getColumns; # Print it out. for my $row ( @$arrayRowRef ) { print "PARM: $row->[$colNames->{NAME}] VALUE: $row->[$colNames->{VALUE}]\n"; } With the array-to-array method, you generally refer to the exact position of an element within an array. However, the getColumns method loads up a hash array, with the column names as keys and the array elements as values. This allows you to refer to the column names, even though your data is stored in an array. It's a kind of magic! 9.2.7 PDBA::LogFile (Logfile Handler)Many of our toolkit utilities log their actions by means of the PDBA::LogFile module. For example, we have a script called dbup.pl that periodically tests connections to all configured databases. Every attempted connection gets logged, successes and failures are recorded, and the failures are emailed to the DBA. The PDBA::LogFile module's purpose in life is to facilitate logging by PDBA scripts; its methods are introduced in Table 9-9. Table 9-9. PDBA::LogFile methods
Logfiles are often locked, so if another instance of a utility is run, it avoids writing over the logfile in use. Therefore, if you are planning several utility instances, it's often best if each gets its own logfile. To open and lock a logfile, here's what you need to do: use PDBA; use PDBA::LogFile; my $logFile = PDBA::pdbaHome . '/logs/test.log'; my $logFh = new PDBA::LogFile($logFile); if( ! $logFh ) { die "failed to open log file for writing - $!\n" } It's a lot simpler than you may have imagined. Here's part of what was going on behind the scenes in PDBA::LogFile , when the logfile was created: if ( -r $logFile and -w $logFile ) { # This should never happen, but we'll check anyway. $self->open($logFile) return undef; $self->close; # Try to open existing log file. # file must be opened with intent to write $self->open("+<$logFile" ) return undef; # Lock file, recreate and relock, and print PID to file. if ( flock $self, LOCK_EXLOCK_NB ) { $self->open("+>>$logFile" ) return undef; print "LogFile 4 : $logFile\n" if $debug; if ( flock $self, LOCK_EXLOCK_NB ) { $self->autoflush; return 1; } else { return undef } } else { $self->close; return undef } } else { # Lock file does not exist. $self->open("+>>$logFile" ) return undef; # Get an exclusive lock on the file. if ( flock $self, LOCK_EXLOCK_NB ) { print "LogFile 7 : $logFile\n" if $debug; return 1 } else { return undef } } Setting up logfiles is one of those necessary but code-intensive tasks that most of us don't care to spend a lot of time on: we'll take the modular use of PDBA::LogFile every time! PDBA::LogFile also avoids assuming anything about logfile location. This means we can do OS-portable log creation using the built-in File::Spec and File::Path modules: use PDBA; use PDBA::LogFile; use File::Spec; use File::Path; my $logFile = PDBA::pdbaHome . '/logs/test.log'; my ($volume, $directories, $file) = File::Spec->splitpath($logFile); my $path = $volume . $directories; # Create the path . File::Path::mkpath($path, 0, 0750); # Make sure it's there . -d -w -r -x $path die "dir $path not usable\n"; my $logFh = new PDBA::LogFile($logFile); if( ! $logFh ) { die "could not open log file for writing - $!\n" } for ( my $i = 1; $i<10; $i++ ) { $logFh->printflush("test line # $i\n"); sleep 5; } Path creation is made even simpler by adding a makepath method to PDBA::LogFile as shown in Example 9-9. Example 9-9. Simplified logfile creation use PDBA::LogFile; my $logFile = PDBA::pdbaHome . '/logs/test.log'; PDBA::LogFile->makepath($logFile); my $logFh = new PDBA::LogFile($logFile); if( ! $logFh ) { die "could not open log file for writing - $!\n" } for ( my $i = 1; $i<10; $i++ ) { $logFh->printflush("test line # $i\n"); sleep 2; } On Unix, makepath creates directories with default file permissions of read, write, and execute for the owner; read and execute for the group, and nothing for others. On Win32, makepath also tries to set permissions, but doing so depends on the file system security setup. 9.2.7.1 PERMS attributeTo set permissions to other values, use the PERMS attribute with an octal permissions value. The following example will prevent anyone other than the system administrator and the file owner from viewing the contents of the log directories: my $logFile = PDBA::pdbaHome . '/logs/test.log'; PDBA::LogFile->makepath($logFile, PERMS => 0700 ); The two print methods, print and printflush , both create a timestamp, which is prefixed on each printed line. Both methods print by calling methods in the IO::File superclass. The output from Example 9-9 would look like this: 20011021233514:test line # 1 20011021233516:test line # 2 ... 20011021233530:test line # 9
9.2.8 PDBA::OPT (Option Handler)The PDBA::OPT module is used in conjunction with the password-control modules ( PDBA::PWC , PDBA::PWD , and PDBA::PWDNT ) described in the following sections. The role of PDBA::OPT is to scan the command line for options that may be intended for the password server, rather than for Oracle itself. PDBA::OPT then feeds the security information found on the command line to the PDBA::PWC module to retrieve a password. The following sections describe the basics of how the various password modules work. See Chapter 11 for an extended example of how PDBA::OPT supports the alert log monitoring scripts provided in the toolkit. 9.2.9 PDBA::PidFile (Program Id Handler)A popular mechanism for preventing programs from being run concurrently is to create a baton file that is then immediately locked. Subsequent attempts to run the same program try to lock the baton file as well. If a program is unable to lock the file, that program exits gracefully with an appropriate message. If the program is able to lock its baton file, processing continues as in the following code snippet, which uses the PDBA::PidFile module to control script execution: use PDBA::PidFile; my $lockFile = '/tmp/myapp_pid.lock'; my $fh = new PDBA::PidFile( $lockfile, $$ ); if ( ! $fh ) { die "could not lock PID file\n"; } One approach might be a daemon for monitoring alert.log . Let's look at the requirements:
Example 9-10 shows how PDBA::PidFile accomplishes these goals. Example 9-10. Locking portion of PDBA::PidFile module sub lockFile { my $self=shift; my ( %options ) = @_; my $lockFile = $options{file}; croak "lockFile requires a file name\n" unless $lockFile; my $pid = $options{pid}; croak "lockFile requires a PID\n" unless $pid; if ( -r $lockFile and -w $lockFile ) { $self->open($lockFile) return undef; ($lockPid) = <$self>; $self->close; # try to open existing lock file # file must be opened with intent to write $self->open("+<$lockFile" ) return undef; # lock file, recreate and relock # print PID to file if ( flock $self, LOCK_EXLOCK_NB ) { $self->open(">$lockFile" ) return undef; # return pid from file if you can't lock if ( flock $self, LOCK_EXLOCK_NB ) { $self->printflush($pid) ; return $pid; } else { return undef } } else { return $lockPid } } else { # lock file does not exist $self->open(">$lockFile" ) return undef; $self->printflush($pid); # get an exclusive lock on the file if ( flock $self, LOCK_EXLOCK_NB ) { return $pid } else { return undef } } } 9.2.10 PDBA::PWD (Password Daemon)The PDBA::PWD module provides the core functionality in the pwd.pl script that we use to centralize password management in the toolkit. Password management is a recurrent issue for DBAs. There is a trend today in many large Oracle sites towards OS authentication, in which the Oracle database allows all authentication to be enforced by the operating system. But this type of authentication may not be feasible in some environments. Many corporate security policies may prohibit the use of OPS$ Oracle accounts, and many DBAs dislike OS authentication, preferring the forced use of passwords because that approach gives DBAs greater control over database security. Despite the recent advent of single sign-on systems, Public Key Infrastructures (PKI), [2] and other advanced security schemes, database accounts protected by passwords are likely to be with us for some time to come. Unfortunately, there are some inherent problems with the use of passwords ” for example:
9.2.10.1 Batch job password problemsEven totally secure password systems may encounter difficult management situations. Batch table loads, index rebuilds, billing statement runs, and a host of other long-running jobs are usually run at night. Unless someone is going to run these jobs manually and input all the passwords as necessary, these jobs need an automated method for inputting correct passwords. To deal with this situation, some DBAs create protected files that contain passwords accessible to scripts requiring passwords. Unfortunately, this solution produces its own problems:
The PDBA::PWD module lessens these problems. It's a TCP socket server, written in Perl, and modeled after the non-forking server found in the excellent Perl Cookbook , by Tom Christiansen and Nathan Torkington (O'Reilly & Associates, 1998). Account passwords remain stored in a single Fort Knox file, and passwords are encrypted over the network. 9.2.11 PDBA::PWC (Password Client)We've also provided a client module, PDBA::PWC , used to communicate with the password server. The pwc.pl script can retrieve passwords on the command line or, even better, Perl scripts can import the PWC module and in this way avoid making passwords visible to operating systems. 9.2.12 PDBA::PWDNT (Password Client for NT)The PDBA::PWDNT module is the Win32 version of PDBA::PWC . It makes use of the Win32::Daemon module that allows it to be installed as a Win32 service. 9.2.13 PDBA (PDBA Utilities)The PDBA module is a collection of utilities. These are used throughout the other modules, as well as in the individual scripts included in the toolkit. PDBA simplifies the process of writing portable scripts ” or at least minimizes the changes necessary when porting scripts across platforms. Table 9-10 lists the methods provided in PDBA. The following sections describe their use. Table 9-10. PDBA methods
9.2.13.1 pathsepBack in the IBM PC dark ages, someone decided that PATH entries in MS-DOS would be separated by semicolons (;). This presented a problem to folks used to the colon character (:) employed by Unix. Today, PATH variables are seldom used in Perl scripts, but when they are, the pathsep method comes in really handy. By using pathsep rather than literal characters , we make the path separator transparent, and we always end up getting the right one: use PDBA; my @pathDirs = split(PDBA->pathsep( ),$ENV{PATH}); my $fullPath=''; my $file='test.conf'; for my $dir ( @pathDirs ) { $fullPath = $dir . PDBA->pathsep( ) . $file; # if file exists and is readable, we're done last if -r $fullPath; $fullPath = ''; } # raise an error if not found unless( $fullPath ) { die "could not find config file $file\n" } This code snippet works on either Win32 or Unix without hard-coding. 9.2.13.2 osnameWe sometimes need to let our code know which platform it's being executed on. In such cases, you will find the osname method very helpful. For example: use PDBA; my $pathsep = ';'; if ( 'Unix' eq PDBA->osname( ) ) { $pathsep = ':' } return $pathsep; 9.2.13.3 pdbaHomeThe pdbaHome method determines the location of PDBA_HOME . On Win32, PDBA_HOME is stored in the Windows Registry. On Unix, it simply needs to be set as an ordinary environment variable. The following code snippet illustrates the use of pdbaHome: use PDBA; my @searchPaths = ( './', '../', PDBA->pdbaHome( ) ); There's a lot going on internally here to determine the correct value for PDBA_HOME : sub pdbaHome { if ( 'Unix' eq PDBA->osname( ) ) { if (exists $ENV{PDBA_HOME}) {return $ENV{PDBA_HOME}} else{return $ENV{HOME} } } else { eval q{use Win32::TieRegistry ( Delimiter=>q{/}, ArrayValues => 0 )}; if ($@) { die "could not load Win32::TieRegistry in PDBA\n"; } else { no warnings; $pdbaKey= $Registry->{"LMachine/Software/PDBA/"}; # :-) use warnings; $ENV{PDBA_HOME} = $pdbaKey->{'/PDBA_HOME'}; unless ( $ENV{PDBA_HOME} ) { die "PDBA_HOME not set in registry\n" } return $ENV{PDBA_HOME}; } } } There is a default for PDBA_HOME on Unix, but not on Win32:
By wrapping the use Win32::TieRegistry portion inside an eval{} block, Perl avoids compiling this code unless it is being executed on a Win32 platform. This feature allows us to write a script that can be executed on both Unix and Win32 platforms. 9.2.13.4 emailWe've centralized a simple-to-use email method in the PDBA module. There are several reasons why you'll find this method helpful:
The email method shown here in use is based on the Mail::Sendmail module developed by Milivoj Ivkovic: [4]
use PDBA; my @addresses = ('scott.tiger@oracle.com','tony.tiger@oracle.com'); my $message = "yes, we're almost there"; my $subject = "are we there yet?"; if ( PDBA->email(\@addresses, $message, $subject) ) { print "Mail sent\n"; } else { print "Mail unsent\n"; } To conclude, the PDBA module is our workhorse module, the spider module in the center of the toolkit's web. Therefore, in addition to the methods described in this section, it contains additional private methods designed only for internal use by other modules in the PDBA Toolkit. This module is the one we're most likely to update as we continue the development of this toolkit. If you wish to explore it further, check out the comprehensive documentation available via the perldoc PDBA command. |

EAN: 2147483647
Pages: 137