XML Modules
| XML (eXtensible Markup Language) is becoming increasingly important in the Oracle world. The language most associated with XML is Java, but there's plenty of XML- related Perl functionality as well, and we'll explore that in the context of data munging in this section. Perl's XML facilities are surprisingly powerful. Some would even claim they go beyond Java, with more than 300 CPAN modules, SAX2 support, DOM support, and machine facilities allowing the pipelining of XML and XSLT transformations. Good Perl XML resources include:
Many different XML modules are also on ActiveState . Most of those covered in this section also have a complementary ActivePerl package:
We'll concentrate in this chapter on the Unix side of life, because this is where we need the more detailed installation instructions. The actual scripts and XML file outputs should be identical for ActivePerl PPM loads. General Perl XML ParsersThere are two main XML parsers employed by the majority of Perl XML users:
XML::ParserYou can obtain the latest XML::Parser from the following CPAN address:
You may also want to pre-install Gisle Aas's LWP World Wide Web library bundle, libwww-perl , and URI module, to provide XML::Parser 's make test step with extra tests. See Chapter 5, for the required LWP installation details. The expat C program download is also available from:
Follow these steps:
XML::LibXMLThe latest XML::LibXML download is available from CPAN. We also need the XML::SAX module from the same place:
XML::LibXML is based on the libxml2 C library, which is available from:
Follow these steps:
XML:: LibXSLTIf you are interested in XSLT (Extensible Stylesheet Language Transformations), the Gemini twin of XML::LibXML is XML::LibXSLT , and now's a good time to install it, because it relies on XML::LibXML . We'll require Daniel Veillard's libxslt C library. For more information try the following:
To get hold of XML::LibXSLT and libxslt go here:
Follow these steps:
Do you need XML::LibXSLT ? Not really, but if you're a completist as we are, you'll feel that it's nice to be fully loaded with XML::LibXSLT . The ability to transform data with XSLT enables us to cope with XML files that fail to match our exact requirements. This way, we can feed XML through a transformation operation, as in Figure D-5, to make it fit our munging needs. Figure D-5. Transforming data with XSLT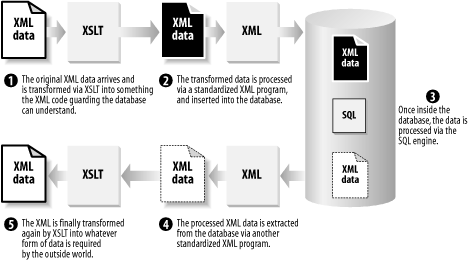 Let's see what's going on here.
XML Database FacilitiesNow that we have our parsers loaded, we can start racking up our XML weapon toolset prior to battle. In the following sections we'll look at the following Perl XML modules:
In addition to these, there are many other Perl XML modules available from CPAN. If you have XML needs that these modules don't satisfy , just visit cpan.org, and type in "XML" via the search page. Prepare to be bombarded by 1001 different XML responses. The same goes for the XML-based PPM packages on ActiveState.com. It seems that all the world has been writing XML modules for Perl. Enjoy! XML::Generator::DBIXML::Generator::DBI , written by Matt Sergeant, transforms database calls to XML SAX events. It is useful for quickly generating XML files directly from SQL statements. It's also the replacement for the earlier DBIx::XML_RDB , another module from the prolific Mr. Sergeant. Check it out at: http://www.cpan.org/authors/id/M/MS/MSERGEANT For testing purposes, and general usage, we also require the services of Michael Koehne's XML::Handler::YAWriter (Yet Another Writer, for Perl SAX): http://www.cpan.org/authors/id/K/KR/KRAEHE This, in turn, requires the talents of Ken MacLeod's XML::Parser::PerlSAX , which comes as part of his libxml-perl package. It consists of a general cornucopia of productivity tools, designed originally for use with XML::Parser :: http://www.cpan.org/authors/id/KMACLEOD Then it's time for that ol' Potomac two-step, with bundle unpacking and Makefile.PL :
We're now ready to run our XML script to produce ducksoup.xml in Example D-10. First attempt linking XML to DBI ” xmlGenDBI.pl #!perl -w use XML::Generator::DBI; use XML::Handler::YAWriter; use DBI; my $writer = XML::Handler::YAWriter->new(AsFile => " ducksoup.xml "); my $dbh = DBI->connect("dbi:Oracle:ORCL.WORLD", "scott", "tiger"); my $xml_generator = XML::Generator::DBI->new( Handler => $writer, dbh => $dbh ); $xml_generator->execute( 'select * from emp where empno < 2000' ); $dbh->disconnect; What Example D-10 should do, in a mere handful of lines, is to take a SELECT statement, and turn it into an XML file. You might recall the data we added to the EMP table earlier in this chapter: SQL> select * from EMP where empno < 2000; EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO ---------- ---------- --------- ------ --------- ------ ------- ------ 1001 Groucho Professor 1 01-JAN-01 100 10 10 1002 Chico Minister 2 02-JAN-01 200 20 20 1003 Harpo Stowaway 3 03-JAN-01 300 30 30 Let's run the script and see what happens: $ perl xmlGenDBI.pl We've taken just the first <row> output from our generated ducksoup.xml file: <?xml version="1.0" encoding="UTF-8"?><database> <select query="select * from emp where empno < 2000"> <row> <EMPNO>1001</EMPNO> <ENAME> Groucho </ENAME> <JOB>Professor</JOB> <MGR>1</MGR> <HIREDATE>01-JAN-01</HIREDATE> <SAL>100</SAL> <COMM>10</COMM> <DEPTNO>10</DEPTNO> </row> ... </select> </database> We can now munge data out of an Oracle database, into XML format, but what about going the other way? This is where XML::XPath comes in. XML::XPathThe XML::Xpath module follows all of the XPath standards you may have seen with other XML toolsets. This XML package is also from:
You can learn more about XPath at:
We're going to use XML::XPath to read XML file data and then pump it into the database to reverse the munge direction from XML::Generator::DBI . There are other ways of doing this ” with XLST transformations for example ” but we'll use XML::XPath because of its flexibility, its appropriateness for munge-style operations, and its simplicity. Follow these steps:
You may recall that there were two other Marx brothers in addition to the main three: Zeppo, who appeared in most of the earlier films , and Gummo, who quit the act while it was still on Broadway. However, we do rather coincidentally have their information stored in an XML file, in Example D-11, nightopera.xml . We'll show how we feed XML into Oracle here. Feeding XML into Oracle ” nightopera.xml<?xml version="1.0" encoding="UTF-8"?> <database> <select> <row> <EMPNO> 1004 </EMPNO> <ENAME> Zeppo </ENAME> <JOB> President </JOB> <MGR> 1 </MGR> <HIREDATE> 04-JAN-01 </HIREDATE> <SAL> 400 </SAL> <COMM> 40 </COMM> <DEPTNO> 20 </DEPTNO> </row> <row> <EMPNO> 1005 </EMPNO> <ENAME> Gummo </ENAME> <JOB> Tenor </JOB> <MGR> 1 </MGR> <HIREDATE> 05-JAN-01 </HIREDATE> <SAL> 500 </SAL> <COMM> 50 </COMM> <DEPTNO> 10 </DEPTNO> </row> </select> </database> We uploaded it to EMP with the XML::XPath script in Example D-12. We've worked through this script immediately following the example: Feeding XML into Oracle ” dbiXPATH.pl #!perl -w use strict; use DBI; use XML::XPath; # Step 1: Connect up to the sink database. my $dbh = DBI->connect( 'dbi:Oracle:ORCL.WORLD', 'scott', 'tiger' ) die $DBI::errstr; # Step 2: Locate the source XML data. my $xpath = XML::XPath->new(filename => 'nightopera.xml' ); # Step 3: Prepare the insertion DML. my $insert_dml = qq{ INSERT INTO emp ( empno, ename, job, mgr, hiredate, sal, comm, deptno ) VALUES ( to_number( ? ), ?, ?, to_number ( ? ), to_date( ? , 'DD-MON-YY'), to_number ( ? ), to_number ( ? ), to_number ( ? ) ) }; my $sth = $dbh->prepare( $insert_dml ); # Step 4: Extract the XML records one by one, through the loop, # and insert into database. my $mgr = $row->find('MGR')->string_value; my $hiredate = $row->find('HIREDATE')->string_value; my $sal = $row->find('SAL')->string_value; my $comm = $row->find('COMM')->string_value; my $deptno = $row->find('DEPTNO')->string_value; # Line inserted into the sink. $sth->execute( $empno, $ename, $job, $mgr, $hiredate, $sal, $comm, $deptno ) die $DBI::errstr; } # Step 5: Clean up, and disconnect. $dbh->disconnect; Let's see what's going on here.
We can see the results here, from the SCOTT.EMP table. SQL> select * from emp where empno in (1004, 1005); EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO --------- ---------- --------- ------ --------- ------ -------- ------ 1004 Zeppo President 1 04-JAN-32 400 40 20 1005 Gummo Tenor 1 05-JAN-33 500 50 10 A combination of XML::Generator::DBI and XML::XPath may be all you require to carry out whatever munging operations you require, both to and from the Oracle database, especially if you want access to all the other Perl modules at the same time. However, as with all things in Perl, there is another way to do it. XML::XMLtoDBMSLet's suppose that we want to extract data from our database into an XML file. We'd like to then beam this across the galaxy to Betelgeuse, via the local StarGate at Vega, and load it there into a Betelgeusian database. We'd like to do all this with a single Perl module. Step forward XML::XMLtoDBMS , a module specially blended with DBI to provide an all-purpose alternative. This module springs directly from its XML-DBMS middleware parent project, which also provides a Java-based alternative. Assuming that we've loaded every XML module discussed so far, except the optional XML::LibXSLT , we have everything we need except for one last module, Graham Barr's TimeDate bundle:
Once installed, we also have Date::Format and Date::Parse on board; these came with TimeDate . We're now ready for the green light. The parent project, XML-DBMS, is Ronald Bourret's Java-based middleware for transferring data between XML documents and relational databases. It deals with many of the coding inconveniences in-between and is ideal for data munging purposes. Check it out at:
From here you'll be directed to the Perl download of XML::XMLtoDBMS , by Nick Semenov. This is ported directly from Ronald Bourret's XML-DBMS software, which is itself written in Java. Before we install XML::XMLtoDBMS , however, let's run through a quick checklist of everything we need:
Once you have these modules and the XML::XMLtoDBMS tarball, it's time for that new dance, the Chesapeake bay whirl: $ gzip -d perl-xml-dbms-1.03.tgz $ tar xvf perl-xml-dbms-1.03.tar $ cd XML-DBMS $ vi README We really ought to read the README file this time, as XML::XMLtoDBMS can be challenging to understand. But once we've got our head round it, the actual installation is straightforward. However, we do need one small adjustment. To cope with the standard Oracle date format, DD-MON-YY , we're going to introduce a one-line adjustment to the XMLtoDBMS.pm module for the 1.03 version, which is an open source product under constant development. (This may very well have been amended in later versions.) Add the marked line to the convertFormat subroutine. We need this line because it will be difficult to re-insert XML date information back into Oracle, via XML::XMLtoDBMS , if the data is not in DD-MON-YY format: sub convertFormat { my $formatString = shift; $formatString =~ s/YYYY/%Y/g; $formatString =~ s/YY/%y/g; $formatString =~ s/MM/%m/g; $formatString =~ s/MON/%b/g; # Typical Oracle month format . $formatString =~ s/DD/%d/g; $formatString =~ s/hh/%H/g; $formatString =~ s/mm/%M/g; $formatString =~ s/ss/%S/g; return $formatString; } A small aside, for those who may think that the fact that this module expects a different date format points out a conceptual weakness of open source software. We disagree . This, we believe, is its greatest strength. If you find that something fails to work exactly the way you expect, you can fix the source code directly, to make it do what you want. Once we've made this small adjustment, installation is routine: $ perl Makefile.PL $ make $ make test $ make install Take a look at the eventual results in Figure D-7. Figure D-7. One Perl XML module to munge them all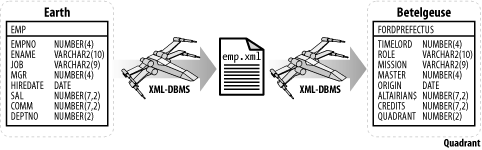 The target data-sink table, on Betelgeuse, was created many centuries ago with the following statement: SQL> create table FordPrefectus 2 ( TimeLord number(4) not null, 3 Role varchar2(10), 4 Mission varchar2(9), 5 Master number(4), 6 Origin date, 7 Altairian$ number(7,2), 8 Credits number(7,2), 9 Quadrant number(2) ); Table created. OK, it is rather remarkable that they have Oracle-type databases on Betelgeuse, but Professor Hawking tells us it's something to do with the infinite pathway effect of those quantum-type particles which make black holes evaporate. The eagle-eyed among you may have also noted that the FORDPREFECTUS table on Betelgeuse is remarkably similar to SCOTT's EMP table back here on Earth. This too is mere quantum coincidence . Even more fortuitously, the most popular entertainment stars on Betelgeuse are the Marx Brothers, as televised transmissions of their films have only started reaching the Betelgeusian quadrant in the last five years . They would therefore like more information on these black-and-white magicians of the silver screen. As a consequence, we recently received an XML-encoded 3-D message cube, asking us to send the requisite details. Source mappingWe have agreed upon an XML mapping with the Betelgeusians to facilitate the requested information transfer. At our end, we need a mapping file to construct the XML output. We'll work through this following Example D-13.
Source mapping for XML::XMLtoDBMS ” emp.map<?xml version="1.0" ?> <XMLToDBMS Version="1.0"> <Options> <DateTimeFormats><Patterns Date="DD-MON-YY"/> </DateTimeFormats> </Options> <Maps> <IgnoreRoot> <ElementType Name="employees"/> <PseudoRoot> <ElementType Name="emp"/> <CandidateKey Generate="No"><Column Name="empno"/> </CandidateKey> </PseudoRoot> </IgnoreRoot> <ClassMap> <ElementType Name="emp"/> <ToClassTable><Table Name="emp"/> </ToClassTable> <PropertyMap> <ElementType Name="empno"/> <ToColumn><Column Name="empno"/> </ToColumn> </PropertyMap> <PropertyMap> <ElementType Name="ename"/> <ToColumn><Column Name="ename"/> </ToColumn> </PropertyMap> <PropertyMap> <ElementType Name="job"/> <ToColumn><Column Name="job"/> </ToColumn> </PropertyMap> <PropertyMap> <ElementType Name="mgr"/> <ToColumn><Column Name="mgr"/> </ToColumn> </PropertyMap> <PropertyMap> <ElementType Name="hiredate"/> <ToColumn><Column Name="hiredate"/> </ToColumn> </PropertyMap> <PropertyMap> <ElementType Name="sal"/> <ToColumn><Column Name="sal"/> </ToColumn> </PropertyMap> <PropertyMap> <ElementType Name="comm"/> <ToColumn><Column Name="comm"/> </ToColumn> </PropertyMap> <PropertyMap> <ElementType Name="deptno"/> <ToColumn><Column Name="deptno"/> </ToColumn> </PropertyMap> </ClassMap> </Maps> </XMLToDBMS> Let's see what's happening here:
There are far more complex things possible with the mappings available in XML::XMLtoDBMS ” for example, table pairs with different primary and foreign key constraints, varying numbers of columns, date and time format differences, and much more. You name it, it's probably in the mapping language. As you can see from Example D-13, however, even a relatively simple exchange of data can generate a large mapping file. But once you've got the basic structure, the rest is just plugging in the numbers . You might wish to examine the DTD file, xmldbms.dtd, which comes with the download, as well as visit the web pages: Source outputNow that we have the mapping, we can generate the XML in Example D-14. Creating our source data ” outXMLDBMS.pl #!perl -w use strict; use DBI; use XML::XMLtoDBMS; # Step 1: Connect to Oracle, as usual. # Then use the database handle to feed XML::XMLtoDBMS. my $dbh = DBI->connect('dbi:Oracle:ORCL.WORLD', 'scott', 'tiger') die $DBI::errstr; my $xmlToDbms = new XML::XMLtoDBMS($dbh); $xmlToDbms->setMap( 'emp.map' ); # Step 2: Get hold of the data. Use the primary keys of our # required rows, to isolate them. my $xmlOut = $xmlToDbms->retrieveDocument( 'emp', [['1001'],['1002'],['1003'],['1004'],['1005']] ); # Step 3: Output the data to XML. open (XML, ">emp.xml"); # Prettify printing with format 1 line break print XML $xmlOut->toString(1); close XML; # Step 4: It's important to clean up the acquired DOM memory, # as well as disconnecting from the Oracle server. $xmlToDbms->destroy; $dbh->disconnect; Let's work through the code.
Let's run the script: $ perl outXMLDBMS.pl A snippet of the resultant output file, emp.xml , is displayed here, with one of the <emp> records: <?xml version="1.0" encoding="UTF-8"?> <employees> <emp> <mgr>1</mgr> <sal>100</sal> <ename> Groucho </ename> <job>Professor</job> <empno>1001</empno> <deptno>10</deptno> <comm>10</comm> <hiredate>01-Jan-01</hiredate> </emp> ... </employees> Notice that we have Groucho embedded, like a nugget of gold, within the XML. Sink mappingOnce emp.xml is beamed across to Betelgeuse by hyperwave-relay, we're going to need another mapping file. This one will cope with the different column names in FORDPREFECTUS. We've detailed this mapping in Example D-15. Mapping the data into the sink ” timelord.map<?xml version="1.0" ?><XMLToDBMS Version="1.0"> <Options> <DateTimeFormats><Patterns Date="DD-MON-YY"/> </DateTimeFormats> </Options> </CandidateKey> </PseudoRoot> </IgnoreRoot> <ClassMap> <ElementType Name="emp"/> <ToClassTable><Table Name="fordprefectus"/> </ToClassTable> <PropertyMap> <ElementType Name="empno"/> <ToColumn><Column Name="timelord"/> </ToColumn> </PropertyMap> <PropertyMap> <ElementType Name=" ename "/> <ToColumn><Column Name=" role "/> </ToColumn> </PropertyMap> <PropertyMap> <ElementType Name=" job "/> <ToColumn><Column Name=" mission "/> </ToColumn> </PropertyMap> <PropertyMap> <ElementType Name=" mgr "/> <ToColumn><Column Name=" master "/> </ToColumn> </PropertyMap> <PropertyMap> <ElementType Name=" hiredate "/> <ToColumn><Column Name=" origin "/> </ToColumn> </PropertyMap> <PropertyMap> <ElementType Name=" sal "/> <ToColumn><Column Name=" altairian$ "/> </ToColumn> </PropertyMap> <PropertyMap> <ElementType Name=" comm "/> <ToColumn><Column Name=" credits "/> </ToColumn> </PropertyMap> <PropertyMap> <ElementType Name=" deptno "/> <ToColumn><Column Name=" quadrant "/> </ToColumn> </PropertyMap> </ClassMap> </Maps> </XMLToDBMS> Let's see what's going on in this example.
Sink inputMeanwhile on Betelgeuse, the XML from Earth has arrived and our friends have the requisite mapping file. All that needs to be done, in Example D-16, is to run a universal Perloid script, operating on the galactic standard Traalix operating system and load it up into the database. Let's go. Inputting into the sink ” inXMLDBMS.pl #!perl -w use strict; use DBI; use XML::XMLtoDBMS; # Step 1: Connect to our remote Oracle database on Betelgeuse :-) # Use the connection acquired to create our XML::XMLtoDBMS object. my $dbh = DBI->connect('dbi:Oracle:BETELGEUSE.WORLD', 'zaphod', 'b33b13br0x') die $DBI::errstr; my $xmlToDbms = new XML::XMLtoDBMS($dbh); $xmlToDbms->setMap( 'timelord.map' ); # Step 2: Acquire the XML file, and then store it in the datasink. my $xmlIn = $xmlToDbms-> storeDocument ( Source => {File => "emp.xml" } ); # Step 3: Disconnect and clean up memory. $xmlToDbms->destroy; $dbh->disconnect; Here's what's happening:
ResultsThe table data folds neatly into FORDPREFECTUS. Mission accomplished: SQL> select * from FordPrefectus ; TIMELORD ROLE MISSION MASTER ORIGIN ALTAIRIAN$ CREDITS QUADRANT -------- ------- --------- ------ --------- ---------- ------- -------- 1001 Groucho Professor 1 01-JAN-01 100 10 10 1002 Chico Minister 2 02-JAN-01 200 20 20 1003 Harpo Stowaway 3 03-JAN-01 300 30 30 1004 Zeppo President 1 04-JAN-01 400 40 20 1005 Gummo Tenor 1 05-JAN-01 500 50 10
|

EAN: 2147483647
Pages: 137