Solaris 2
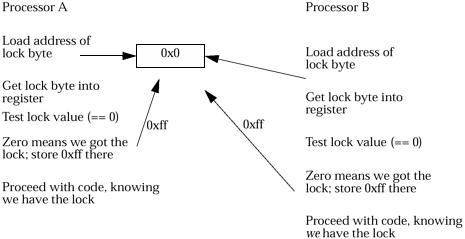
| For the new Solaris 2 kernel, a major rewrite of the internal code was done to provide true symmetric multiprocessing. A different approach to protecting the kernel data had to be taken since the spl() method was effectively useless. Instead of putting a lock around a section of code that accessed critical data structures, the locks were put in the data structures themselves . Before accessing or modifying a piece of data, the code was made responsible for obtaining the correct lock. This would enable multiple processors not only to be running in the kernel simultaneously , but also to be running the same code. For example, if a piece of code modifies a thread structure, as long as multiple processors are not trying to access the same structure, multiple versions of the structure could be accessed or updated at the same time without any problems. This does mean that each major data structure must be protected with a lock. There is a bit of a tradeoff here. If you have very few locks, it is very likely that a processor will need that lock to do its work. If you have a great number of locks, there will be fewer conflicts when the same lock is needed, but all the processors will spend a lot of their cycles grabbing and releasing locks. Solaris 2 has about 150 different types of structures protected with locks. Atomic instructionsFor a multiprocessor system to realistically implement some sort of locking and synchronization between the CPUs, some support in hardware is required. On a SPARC processor, there are a couple of atomic instructions, or operations guaranteed by the hardware to be uninterruptible. This allows any given processor to examine and possibly modify a lock in memory without fear of another processor getting in there in the middle. If this were to be done with normal instructions, it would be a fairly long process: it would take several operations to pull the lock out of memory, examine it, and put a new value back to mark the lock as "taken." Picture, if you will, two processors executing the same code within one instruction of each other, as illustrated in the next figure. Figure 29-1. Two processors executing the same code within one instruction of each other As you can see, this lock was a waste of time. There has to be a better way to implement a lock access in order to make the lock work reliably. Atomic instructions will allow a processor to test and set a lock in one instruction cycle, preventing any other processor from looking at the lock at the same time. The instruction used in Solaris 2 is ldstub (load/store unsigned byte), which will take a byte from memory and replace it with 0xff in one clock cycle. The processor can then look at the value and see what it got. If the byte in the register is zero, then the lock was not previously set, it is now 0xff by virtue of the instruction we just executed, and we have set the lock. If the value is 0xff, that means we replaced 0xff in the lock with 0xff, and somebody else got there first. All locking in Solaris 2 is done at some point by using this ldstub instruction. The basic lock that utilizes this is called a mutex lock, for mutual exclusion . There are other types of locks in the kernel, but they depend on this type for synchronization at some point. Note There is another atomic instruction in the official SPARC instruction set, swap . This will replace a 32-bit word in memory with one in a register. It's not used. Some very early implementations of the SPARC processor did not include the swap instruction in hardware: it was emulated by the system. With no guarantee that this is a real atomic operation for all CPUs, it can't be depended upon for locking. Mutex structureThe mutex lock structure is defined in the header file mutex.h . It contains several different definitions for varieties of mutex locks. The most commonly used is the adaptive mutex. Example 29-1 The default adaptive mutex structure as defined in /usr/include/sys/mutex.h /* * Default adaptive mutex (without stats). */ struct adaptive_mutex { uint_t m_owner : 24; /* 0-2 24 bits of owner thread_id */ lock_t m_lock; /* 3 lock */ uchar_t m_type; /* 4 type (zero) */ disp_lock_t m_wlock; /* 5 waiters field lock */ turnstile_id_t m_waiters; /* 6-7 cookie for the turnstile */ } m_adaptive; Note that this lock has the owner of the lock and the lock byte itself encoded into the first word of the structure. The owner field is in reality a mangled pointer to a thread structure describing the thread that obtained (and owns) the lock. This pointer compaction (32 bits into 24 bits) can be done by pulling a few tricks. First, the SPARC Application Binary Interface specification (the ABI) defines explicitly the lowest possible starting address of the kernel (which is also the highest available address in user space): 0xe0000000. Kernel addresses will only be larger than this, which means that the top three bits of any thread structure pointer are going to be all 1's, guaranteed. They get stripped off. Next, structures are placed on word boundaries, so the starting address will always be an even multiple of 4, which means the last two bits of the address are zero. This gives 5 bits, whose value we already know, but in order to fit this pointer into 24 we need an additional 3 bits taken off. To do this, the kernel will enforce a boundary condition for thread structures such that they always begin on an even 8-word address. This forces 3 more bits of zeroes at the bottom of the address and gives us 8 total whose value we know. The remaining 24 are put into the mutex structure. Why go through all these contortions? Consider what happens when you release a lock. If another processor is currently examining that lock, there are a couple of things that might happen. If you clear out the owner field first, then release the lock byte, anybody looking at the lock will find it set and see a null pointer as the owner. Not good. If you clear the lock byte, and then the owner, the lock will be open for a period, which may allow somebody to grab the lock, set their thread pointer in the owner field, and proceed ” only to have your processor zero out the owner field as the last act of releasing it. Also not good. It is mandatory to release the lock byte and clear the owner field in one blow, so they both have to fit in one full word that can be zeroed by one instruction. There are two main types of mutex locks: the spin lock and the adaptive mutex . Spin locks are the simplest (they are essentially what was implemented for the SunOS 4.x MP kernel). Any processor that wants the lock will simply sit in a loop watching for it to be released. This waiting can obviously tie up a CPU and will only be done when the system can do nothing else, for instance, when in a high-level interrupt service routine. There is no way the processor can block the interrupt handler, so it has to wait in a loop. The more common type of mutex is the adaptive mutex. This starts out as a potential spin lock; if the status of the thread that owns the lock is currently ONPROC (executing on a CPU at this instant), then the processor will spin. The idea is that locks are generally held for a short period of time, and it is likely that the lock will be released soon. This avoids the overhead of putting the current thread to sleep and performing a context switch. If, however, the thread that owns the lock either is sleeping or goes to sleep, there could be a long wait for this one to be freed, so the waiting thread blocks, goes to sleep on that lock, and does a context switch until the lock is released. Other locks: semaphores, reader/writers, condition variablesThere are other types of locks for other purposes, although most of them use the same basic lock (the mutex) as an underlying control mechanism. Semaphores are used to control resources where a finite number of items, all the same, are available. If you need a buffer, for example, you can get one from a pool. If no more are available, then you sleep. This allocation mechanism needs a counter, which is implemented with a semaphore lock. Internal kernel functions to manipulate and set up semaphores are defined in the DDI/DKI kernel functions list, under semaphore(9F) . Reader/writer locks allow many threads to access data in read-only form (to scan a list, for example). As soon as another thread needs to update that list, everything else must wait until the modification has been performed before looking at it again. Thus, we need a control mechanism to allow multiple readers or one and only one writer. The functions associated with these locks are defined in rwlock (9F) . Condition variables are used, like mutex locks, when checking conditions or the availability of resources and for blocking if the conditions are not right. These are generally always used with an associated mutex lock: the lock is intended to make sure that the condition check is done atomically. If the check indicates that it is time to go to sleep, the thread can block on a condition variable (which contains the information on how to find this thread and wake it up again). Use of condition variables is controlled by condvar(9F) functions. The associated mutex routines are defined in mutex(9F). Condition variables are not really a lock in themselves, but they are used to help with the synchronization of threads. Blocking & sleepingNormally, a processor that needs a lock of any type will try to grab it, and sleep (block) if it fails. What exactly is "sleeping"? In BSD-based kernels , with one processor, a process inside the kernel (performing a system request) could encounter a situation where it could not proceed any further: it was blocked. Obviously it couldn't just sit there and spin, since that would lock up the processor and prevent anybody else from getting any useful work done. This means it had to stop, save its current state, and allow another process to pick up where it left off and continue running for a while. This was done with a sleep() function call, which effectively blocked the caller and did a context switch to another process. The sleep() call had two parameters: an address and a priority code. The address was really just a magic number (sometimes referred to as a cookie). It was used as a unique index into a hash table: this process was put in a queue, asleep, until something, somewhere, did a wakeup () with the same magic number as a parameter. This would result in the process being put back on the run queue, since the reason it went to sleep had gone. This magic cookie can be seen in the output of the ps command as the value in the WCHAN or "wait channel" column. The priority on the sleep() call indicated, among other things, whether this sleep was interruptible (e.g., an I-wait or a D-wait state in the ps output). If it was interruptible, or in I state, a signal would result in an "error return" from the sleep, a return back to the user, and usually an error code of EINTR being placed in the global errno variable. Solaris 2 waitersWith Solaris 2, this method was revised somewhat. The new method involves creation of something called a turnstile (a first-in, first-out queue) with a unique ID value. Since there are so many locks and condition variables, it's impossible to have a separate queue for each one to hold waiting threads, so a pool of queues was defined. This pool is known as a set of turnstiles, which are more or less general-purpose queues for sleeping. When some thread needs to wait and there is no current set of sleepers, it will grab the next queue available from the list of turnstiles , put itself on that queue, and insert the information about which queue it used into the condition variable itself. Later threads that hit the same lock will add themselves to the end of the queue. Eventually, the lock is released, or the condition goes away, and the first sleeping thread on the queue gets to run. The functions that do this are cv_wait() and cv_wait_sig() , to sleep and await a wakeup call, and cv_signal() , to send the wakeup. The latter of the two cv_wait calls will also return if a real signal occurs. The condition variable is a short 16-bit location that is intended to contain a turnstile ID number (essentially a row and column number for the array of turnstile pointers). This was the only method of thread synchronization used up through Solaris 2.2. In Solaris 2.3, a variation on the old hash table scheme was put back in. The condition variable address supplied to cv_wait is just used as the magic number in an old-style sleep. The Solaris 2.3 thread structure contains the address of the condition variable that was used to sleep on in the wchan field. If this field is non-zero , it is the address of some condition variable and the thread is blocked. When looking at sleeping threads, then, a Solaris 2.0 through 2.2 thread will have the address of the condition variable as the first parameter of the cv_wait() function on the top of its stack trace. For 4.x and Solaris 2.3 (and greater), systems will use the wchan field to identify the address, or the "reason for sleeping." This value may help you identify threads or processes that are stuck on the same resource or event. If several seem to have the same wchan value (or condition variable address), examine the tracebacks for these to see if the reason for sleeping is innocuous (waiting for input from the keyboard, for instance) or potentially interesting (like sleeping in paging functions that really should be of a very short duration). Turnstiles are defined and documented in the /usr/include/sys/turnstile.h header file. In particular the definitions of row/column sizes and how those are extracted from the 16-bit number in the turnstile are of interest. These will indicate which turnstile is in use, but unfortunately locating the actual list of waiting threads is impossible without digging into the source files. Mutex locksThere are some differences with condition variables in Solaris 2, but mutex locks are all treated the same way. The mutex lock that allows sleeping, an adaptive mutex, contains a field, called m_waiters , in the structure. This field is the ID number of a turnstile, not a condition variable, and the turnstile queue contains the list of threads waiting for this mutex lock. Thus, you can find out if threads are waiting for a particular mutex by examining the waiters field to see if it is non-zero. In general, a thread that is waiting for a mutex should be put on a queue. In a crash dump, stack traces that show one or more threads actually spinning in the mutex_enter() function may be significant. It might be worthwhile finding the owners of these mutex locks and checking to see what they are doing. Remember, a thread will only spin if it thinks the owner of the lock is currently running and should be done soon. If this doesn't happen, you may have run into a deadlock situation with a loop: Each thread is spinning, waiting for the owner of a different lock to finish and release the first one. If you end up in a circle, each thread will spin forever. This can have a rather significant effect on performance. |
EAN: 2147483647
Pages: 289