Synchronization Problems
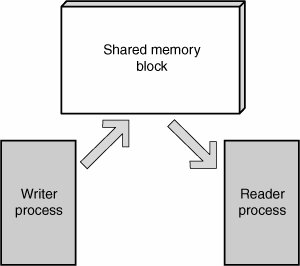
| Certain types of operations require atomicitythat is, they must happen in an uninterruptible sequence. Errors can occur when applications fail to enforce atomicity requirements between concurrent instances of execution. To understand this issue, imagine two processes sharing a memory segmentone process writing to it and one reading from it, as shown in Figure 13-1. Figure 13-1. Shared memory between two processes The reader process could be interrupted while copying data out of the memory segment by the writer process, which places alternative data at the location being read from. Likewise, the writer process could be interrupted by the reader when it's only half finished writing data into the shared memory segment. In both situations, the shared memory segment is said to be in an inconsistent state because it's halfway through an operation that should have been atomic between the two processes. OSs provide synchronization primitives that address concurrent programming requirements. Atomic access to resources is often controlled through a mutual exclusion (mutex) primitive. When a thread attempts to access the shared resource, it must first acquire the mutex. Acquiring a mutex means that other processes or threads attempting to acquire the same mutex are blocked (waiting) until the owner releases the mutex. Acquiring ownership of a mutex may also be referred to as locking or holding; releasing ownership of a mutex may be referred to as unlocking or signaling. Unfortunately, complex locking requirements can make it difficult to use synchronization APIs correctly. Additionally, code with concurrency issues exhibits symptoms infrequently, with error conditions that often appear random and non-repeatable. This combination of factors makes concurrency issues extremely difficult to identify and trace. As a result, it's easy for errors of this nature to go undiagnosed for a long time, simply because the bug can't be reproduced with what appears to be identical input. The following sections cover the basic problems that concurrent programming introduces so that you can relate this material to more concrete vulnerabilities later in the chapter. Reentrancy and Asynchronous-Safe CodeThe first step in understanding concurrency issues involves familiarizing yourself with the concept of reentrancy. Reentrancy refers to a function's capability to work correctly, even when it's interrupted by another running thread that calls the same function. That is, a function is reentrant if multiple instances of the same function can run in the same address space concurrently without creating the potential for inconsistent states. Take a look at an example of a non-reentrant function: struct list *global_list; int global_list_count; int list_add(struct list *element) { struct list *tmp; if(global_list_count > MAX_ENTRIES) return -1; for(list = global_list; list->next; list = list->next); list->next = element; element->next = NULL; global_list_count++; return 0; }For this example, assume that there is a list_init() function that initializes the list with a single member, so that a NULL pointer dereference doesn't occur in the list_add() function. This function adds an element to the list as it should, but it's not a reentrant function. If it's interrupted by another running thread that calls list_add() as well, both instances of the function simultaneously modify the global_list and global_list_count variables, which produces unpredictable results. For a function to be reentrant, it must not modify any global variables or shared resources without adequate locking mechanisms in place. Here's another example of a function that handles global data in a non-reentrant manner: struct CONNECTION { int sock; unsigned char *buffer; size_t bytes_available, bytes_allocated; } client; size_t bytes_available(void) { return client->bytes_available; } int retrieve_data(char *buffer, size_t length) { if(length < bytes_available()) memcpy(buffer, client->buffer, length); else memcpy(buffer, client->buffer, bytes_available()); return 0; }The retrieve_data() function reads some data from a global structure into a destination buffer. To make sure it doesn't overflow the destination buffer, the length parameter is validated against how many bytes are available in the data buffer received from a client. The code is fine in a single uninterruptible context, but what happens if you interrupt this function with another thread that changes the state of the client CONNECTION structure? Specifically, you could make it so that bytes_available() returned a value less than length initially, and then interrupt it before the memcpy() operation with a function that changes client->bytes_available to be larger than length. Therefore, when program execution returned to retrieve_data(), it would copy an incorrect number of bytes into the buffer, resulting in an overflow. As you can see, synchronization issues can be quite subtle, and even code that appears safe at a glance can suddenly become unsafe when it's placed in an interruptible environment such as a multithreaded application. This chapter covers several vulnerability types that are a direct result of using non-reentrant functions when reentrancy is required. Race ConditionsA program is said to contain a race condition if the outcome of an operation is successful only if certain resources are acted on in an expected order. If the resources aren't used in this specific order, program behavior is altered and the result becomes undefined. To understand this problem, consider a program that contains several threadsa producer thread that adds objects to a queue and multiple consumers that take objects from the queue and process them, as shown in the following code: struct element *queue; int queueThread(void) { struct element *new_obj, *tmp; for(;;) { wait_for_request(); new_obj = get_request(); if(queue == NULL) { queue = new_obj; continue; } for(tmp = queue; tmp->next; tmp = tmp->next) ; tmp->next = new_obj; } } int dequeueThread(void) { for(;;) { struct element *elem; if(queue == NULL) continue; elem = queue; queue = queue->next; .. process element .. } }The problem with this code is it modifies a shared structure without any locking to ensure that other threads don't also modify or access the same structure simultaneously. Imagine, for example, that dequeueThread() is running in one thread, and executes the following instruction: elem = queue; The structure is in an inconsistent state if the thread is interrupted after this code runs but before updating the queue variable to point to the next element. This state results in two threads de-queuing the same element and simultaneously attempting to operate on it. Starvation and DeadlocksStarvation can happen when a thread or set of threads never receives ownership of a synchronization object for some reason, so the threads are prevented from doing the work they're supposed to do. Starvation can be the result of a thread waiting to acquire ownership of too many objects or other threads with a higher priority constantly hogging the CPU, thus not allowing the lower priority thread to ever be scheduled for execution. Deadlocks are another problem encountered frequently in concurrent programming. They occur when two or more threads are using multiple synchronization objects at once but in a different order. In this situation, a lock is used to avoid a race condition, but the locks are acquired in an unexpected order, such that two threads of execution are waiting for locks that can never be released because it's owned by the other thread. The following code shows a simple example: Int thread1(void) { lock(mutex1); .. code .. lock(mutex2); .. more code .. unlock(mutex2); unlock(mutex1); return 0; } int thread2(void) { lock(mutex2); .. code .. lock(mutex1); .. more code .. unlock(mutex2); unlock(mutex1); return 0; }This example has two threads that use mutex1 and mutex2 but in a different order, and both threads lock them simultaneously. This is a recipe for disaster! The problem can be best understood by playing out a sample scenario:
Both threads are now unable to continue because they are waiting on a condition that can never be satisfied. For a deadlock to be possible, four conditions need to exist:
If all four conditions exist in a program, there's the possibility for deadlock. Deadlock might also occur if a thread or process neglects to release a resource when it's supposed to because of a programming error. |
EAN: 2147483647
Pages: 194