10.2 Data Structure
| Data format in objects is generally simple because if it were not, a separate object would be constructed to hold just the data. However, not only must the structure of the data be defined, the valid ranges of data, accuracy, preconditions, and initial values must also be specified during detailed design. This is part of what Bertrand Meyer calls "design by contract" [7]. Detailed data design applies to "simple" numeric data just as much as of user-defined data types. After all, aircraft, spacecraft, and missile systems must perform significant numeric computation without introducing round-off and accuracy errors or bad things are likely to happen.[3] Consider a simple complex number class. Complex numbers may be stored in polar coordinates, but let's stick to rectilinear coordinates for now. Most of the applications using complex numbers require fractional values, so that using ints for the real and imaginary parts wouldn't meet the need. What about using floats, as in
class complex_1 { public: float iPart, rPart; // operations omitted }; That looks like a reasonable start. Is the range sufficient? Most floating-point implementations have a range of 10-40 to 10+40 or more, so that is probably OK. What about round-off error? Because the infinite continuous set of possible values are stored and manipulated as a finite set of machine numbers, just representing a continuous value using floating-point format incurs some error. Numerical analysis identifies two forms of numerical error absolute error and relative error [1]. For example, consider adding two numbers, 123456 and 4.567891, using six-digit-precision floating-point arithmetic:
Because this must be stored in six-digit precision, the value will be stored as 0.123460 x 106, which is an absolute error of 0.567891. Relative error is computed as
where m(x) is the machine number representation of the value x. This gives us a relative error of 4.59977 x 10-8 for this calculation. Although this error is tiny, errors can propagate and build during repeated calculation to the point of making your computations meaningless. Subtraction of two values is a common source of significant error. For example,
But truncating these numbers to six digits of precision yields
which is an absolute error of 0.325 x 10-6 and a relative error of 14%. This means that we may have to change our format to include more significant digits, change our format entirely to use infinite precision arithmetic,[4] or change our algorithms to equivalent forms when a loss of precision is likely, such as computing 1 cos(x) when the angle close to zero can result in the loss of precision. You can use the trigonometric relation
to avoid round-off error.[5]
Data is often constrained beyond its representation limit by the problem domain. Planes shouldn't pull a 7g acceleration curve, array indices shouldn't be negative, ECG patients rarely weigh 500 Kg, and automobiles don't go 300 miles per hour. Attributes have a range of valid values and when they are set unreasonably, these faults must be detected and corrective actions must be taken. Mutator operations (operations that set attribute values) should ensure that the values are within range. These constraints on the data can be specified on class diagrams using the standard UML constraint syntax, such as { range 0..15}. Subclasses may constrain their data ranges differently than their superclasses. Many designers feel that data constraints should be monotonically decreasing with subclass depth, that is, that a subclass might constrain a data range further than its superclass. Although system can be built this way, this violates the Liskov Substitution Principle (LSP):
If a superclass declares a color attribute with a range of { white, yellow, blue, green, red, black} and a subclass restricts it to { white, black} then what happens if the client has a superclass pointer and sets the color to red, as in enum color {white, yellow, blue, green, red, black}; class super { protected: color c; public: virtual void setColor(color temp); // all colors valid }; class sub: public super { public: virtual void setColor(color temp); // only white and black now valid }; Increasing constraints down the superclass hierarchy is a dangerous policy if the subclass will be used in a polymorphic fashion. Aside from normal attributes identified in the analysis model, detailed design may add derived attributes as well. Derived attributes are values that can in principle be reconstructed from other attributes within the class, but are added to optimize performance. They can be indicated on class diagrams with a «derived» stereotype, and defining the derivation formula within an associated constraint, such as { age = currentDate startDate}. For example, a sensor class may provide a 10-sample history, with a get(index) accessor method. If the clients often want to know the average measurement value, they can compute this from the history, but it is more convenient to add an average( ) operation like so: class sensor { float value[10]; int nMeasurements, currentMeasurment; public: sensor(void): nMeasurements(0), currentMeasurement(0) { for (int j = 0; j<10; j++) value[10] = 0; }; void accept(float tValue) { value[currentMeasurement] = tValue; currentMeasurement = (++currentMeasurement) \ 10; if (nMeasurements < 10) ++nMeasurements; }; float get(int index=0) { int cIndex; if (nMeasurements > index) { cIndex = currentMeasurement-index-1; // last valid one if (cIndex < 0) cIndex += 10; return value[cIndex]; else throw "No valid measurement at that index"; }; float average(void) { float sum = 0.0; if (nMeasurements > 0) { for (int j=0; j < nMeasurements-1; j++) sum += value[j]; return sum / nMeasurements; } else throw "No measurements to average"; }; }; The average() operation only exists to optimize the computational path. If the average value was needed more frequently than the data was monitored, the average could be computed as the data was read: class sensor { float value[10]; float averageValue; int nMeasurements, currentMeasurment; public: sensor(void): averageValue(0), nMeasurements(0), currentMeasurement(0) { for (int j = 0; j<10; j++) value[10] = 0; }; void accept(float tValue) { value[currentMeasurement] = tValue; currentMeasurement = (++currentMeasurement) \ 10; if (nMeasurements < 10) ++nMeasurements; // compute average averageValue = 0; for (int j=0; j < nMeasurements-1; j++) averageValue += value[j]; averageValue /= nMeasurements; }; float get(int index=0) { int cIndex; if (nMeasurements > index) { cIndex = currentMeasurement-index-1; // last valid one if (cIndex < 0) cIndex += 10; return value[cIndex]; else throw "No valid measurement at that index"; }; float average(void) { if (nMeasurements > 0) return averageValue; else throw "No measurements to average"; }; }; In this case, the derived attribute averageValue is added to minimize the required computation when the average value is needed frequently. Collections of primitive data attributes may be structured in myriad ways, including stacks, queues, lists, vectors, and a forest of trees. The layout of data collections is the subject of hundreds of volumes of research and practical applications. The UML provides a role constraint notation to indicate different kinds of collections that may be inherent in the analysis model. Common role constraints for multivalued roles include
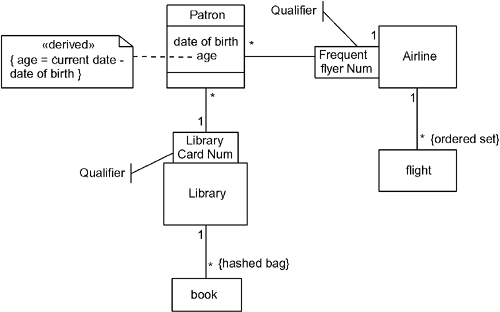
Some constraints may be combined, such as { ordered set} . Another common design scheme is to use a key value to retrieve an item from a collection. This is called a qualified association and the key value is called a qualifier. Figure 10-1 shows examples of constraints and qualified associations. The association between Patron and Airline is qualified with Frequent Flyer Num. This qualifier will be ultimately implemented as an attribute within the Patron class and will be used to identify the patron to the Airline class. Similarly, the Patron has a qualified association with Library using the qualifier Library Card Num. The associations between Airline and Flight and between Library and Book have constrained multivalued roles. The former set must be maintained as an ordered set while the latter is a hashed bag. Note also the use of a text note to constrain the Patron's age attribute. The stereotype indicates that it is a derived attribute and the constraint shows how it is computed. Other constraints can be added as necessary to indicate valid ranges of data and other representational invariants. Figure 10-1. Role Constraints and Qualified Associations
Selection of a collection structure depends on what characteristics should be optimized. Balanced trees, for example, can be searched quickly, but inserting new elements is complex and costly because of the need to rotate the tree to maintain balance. Linked lists are simple to maintain, but searching takes relatively long. |
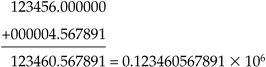
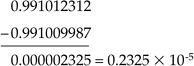
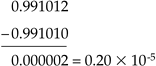
EAN: 2147483647
Pages: 127