Section 9.2. Before the Release
9.2. Before the ReleaseBefore the first release is even begun, you can make some decisions about how the product will appear to customers. It's well worth writing these decisions down and making sure that everyone in the project knows where to find the information. One key decision is how to decide when to ship a release. Is the date to be driven by features, by accumulated bug fixes for customers, by the elapsed time since the last release, by an approaching trade fair, or at the whim of someone in the project with a strong opinion? A mixture of all of these is not unusual, but it's good to be clear about it from early on, since many other decisions are driven by release dates. Releasing a product is also where the differences between open and closed software become more apparent. For instance, license keys make sense only for closed software, and older releases of open source products are only ever maintained if there are sufficient people interested in doing so, since there are usually no legal contracts involved. 9.2.1. System RequirementsWhat is needed by customers must be very carefully documented. For instance, what platforms should the project's developers expect to support? Which browsers? Which versions of additional libraries and infrastructure code? If this sort of information is not readily available, then the environment used by each developer tends to diverge over time, and obscure bugs related to unsupported platforms can creep into the product. These requirements need to be unambiguous and easily available from within the project. Customers need to be able to see this information before they begin to install your software; requirements are usually also put on a web page somewhere. The list of requirements for installing a product should include:
For all these requirements, it is very helpful if you include links to where the files can be downloaded from or where to find more information about each requirement. If you can distribute any extra required software with your product, this makes the whole process of using your product easier for everyone (except maybe the release team). 9.2.2. Build NumbersBuild numbers are for internal use within a project, and a particular release number can have had many build numbers as the release was developed. The next section looks at release numbers, which are how customers distinguish between different released versions of your product. The concept of build numbers is that each build that is used by people other than individual developers should have its own unique identifying number. The build number should increase over time, usually without gaps. There is no real need for customer releases to have build numbers (or at least to show them) since that's what release numbers are for. If SCM branches are used for development, then the build number should follow the branch, as shown in Figure 9-1. This means that the build number on the main line always tells you the number of builds since the last major branch. Do record when the builds started using the branch, so that someone doesn't assume later on that all the builds for a particular release used that release's branch. Figure 9-1. Build numbers following a branch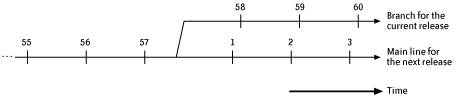 9.2.3. Release NumberingThe release number of a product is really part of marketing different versions of your product to customers. People want to be able to tell different versions apart, so each release number should be unique for all time, or at least for as long as the product is marketed under the same name. There's a general expectation that the release numbers should increase over time and that some release numbers are more significant than others. For instance, the first release of a product is usually suspected of having more bugs than it should. Developers should treat release numbers like project names (see Section 3.6.1) and expect them to change for nontechnical reasons at any time. Within these guidelines, there are actually a number of widely used numbering schemes for releases. A release number of the form major.minor.patch uses three separate integers; the major, minor, and patch release numbers. This scheme communicates something about the degree of change and maturity of each release. Version 1.0.0 is usually the first public release and bears the stigma of being a "dot zero" release. Note that 1.0.9 can be followed by a 1.0.10 release or a 1.1.0 release. Generally, the patch number is changed for bug-fix releases, the minor number is changed for releases with new features, and the major number is changed for releases that break compatibility with prior releases in some significant manner. With this scheme, the question is what to call the releases prior to 2.0.0? One solution is to use 1.x.y and then a build number to distinguish between builds. However, sometimes it's important to know that this is going to be a 2.0 build for testing the upgrade process. In this case, the internal builds can all be named 2.0.0 and the first customer release can be named 2.0.1. Build numbers should always increase by one for simplicity, so try to avoid schemes such as starting customer releases at build 1000. One drawback of this scheme is that the only information about the order of releases is for the patch releases; that is, you can assume that 1.1.2 was released after 1.1.1. We don't know from the release number whether 1.1.2 was released before or after 2.0, since the 1.1 release could be a very long-lived release. Figure 9-2 shows that a release number (1.1.0 in this case) can appear both on the main line if it is built from there, and then later on a release branch, which can sometimes seem counterintuitive. The build numbers and information about when the 1.1 release branch was created can help avoid any confusion. Figure 9-2. Release numbers and branches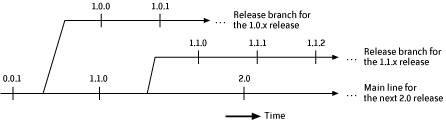 Another scheme extends the major.minor.patch scheme by using even minor numbers to indicate which releases are considered stable and odd minor numbers to indicate which releases are still in development. GNU/Linux is the best known example of this scheme, where kernel Versions 2.3.x and 2.5.x are unstable, development versions and Versions 2.4 and 2.6 are the stable releases used by most GNU/Linux distributions. Linux is currently ensuring stability by allowing changes for only a one-week period after each release. Another scheme uses numbers that asymptotically approach the intended release number. So after customer release 1.2 comes customer 1.3, but the releases leading closely up to 1.3 are numbered 1.2.99.1 to 1.2.99.999. This approach has logic to support it but seems confusing in practice to some people. Yet another scheme you may see used is adding a suffix of "rcn" for "release candidate n." For example, 4.0rc3 is the third candidate for the intended 4.0 release. When the final release candidate is promoted to be the actual release, it is repackaged with no changes. This scheme seems a little harder to parse algorithmically within an application, but its intent is clear. Other, more creative release-numbering schemes include the one used by Donald Knuth for TEX, which has successive releases numbered as 3.1, 3.14, and 3.141, with each release adding the next digit from . Another idea to minimize disagreements over what the next version number should be is to use complex numbers, with the real part assigned by one group (say, engineering), and the imaginary part assigned by another group (say, marketing). This is what has effectively happened in the past with large products such as Java and Windows. This is actually quite sensible: the real part can be a build label such as the project name and the build number, and the imaginary part can be the release number (or release numbers, for products on different platforms). Whatever numbering scheme is chosen, the values must always be unique. For instance, periods are what makes 1.11.2 different from 1.1.12. An alternative approach is to add leading zeros to the numbersfor example, 01011002 instead of 1.11.2. Ideally, the release numbers should sort in a predictable manner, so they can be compared conveniently within the product and can easily be found in lists of releases in a bug tracking tool. Treating some version numbers purely as strings will lead to ASCII sorting and lists such as release_1, . . . , release_101, release 2. Maintaining major, minor, and patch numbers as integers accessible within a product's source code and other development environment tools can make the sorting order more useful. All these numbers can become confusing, especially when spoken aloud: was that "three one two, build three" or "three one three, build two"? The numbers also begin to acquire deeper significance if APIs are allowed to change only in minor releases and not in patch releases, or when support for a release cannot be dropped until the major version number changes. The internal engineering project name for the project is usually more useful than release numbers in SCM tags and bug tracking tools. The actual release number can be chosen later on, closer to the release date (Debian Linux does this). Some honesty should be encouraged here, thougha release shouldn't be declared a patch release just to reassure a customer that not too much changed, especially if it's really a barely tested rewrite of a core part of the product. 9.2.4. Release InformationOnce you have decided on a build-numbering scheme and a release-numbering scheme, there is the question of what other information is needed about each build. Here are some suggestions for what to record with each official build:
Once you have decided what information to record with a build (be generous here), you also need an easy way to find that information. A simple text or XML file that is created with each build is one way. If the information is embedded in the product, there should be some way to display the information (for example, an About box for a UI, or a -version argument for a CLI). Note that this is entirely separate from information gathered at runtime about a customer's environment. However the information is accessed, it needs to be easy to use from a wide variety of tools. Another useful idea is to create and document a standard way of referring to releases in the SCM tool, in the bug tracking tool, and for other purposes such as coverage and profiling reports. When you're trying to rebuild a release from source, it's irritating to have to wonder whether the tag was 1-2-3, 1.2.3, or 1_2_3. Yes, you can probably look it up somewhere, but a common way of doing things avoids even this effort. Some tools will have restrictions on the format of names. For instance, CVS tags cannot start with a digit or have periods in them. Section 3.5 discusses this idea of build labels in more detail. 9.2.5. UpgradingDeciding how customers will upgrade to a newer release of your product is something you should do before the first release. There are two aspects to upgrading: the political and the practical. The political side is how to convince your customers to upgrade, whether it is for features, bug fixes, or because you no longer want to provide support for an older release. Upgrades are extra work for customers and always carry a risk. The risk for them is that the upgrade may not work; the risk for you is that they may choose to use someone else's product instead of yours. Some customers and some products can never be upgradedthink of the software in a household appliance such as a toaster. Setting expectations early on about how long a release will be supported can prevent some nasty arguments years later. If the customer is a large company, its influence may be enough to force a release to live forever, a sort of "living dead" horror film for those who have to maintain it. One common way to write the expectations into a contract is to declare that a release will be supported for one calendar year after the next major release (that is, any release where the major release number changes). Another question is whether patch releases are independent of each other, or whether they are cumulative. That is, does release 2.0.8 also include all the bug fixes in releases 2.0.1 to 2.0.7? Most customers assume that patch releases are cumulative, but if this is not the case, then a separate numbering scheme for patches is necessary. The advantage of independent patches is that there is less risk of destabilizing a large product when applying a patch. However, keeping track of which patches have been applied can become very tedious for the customer and for your support team. On the practical side of upgrades, there is the question of how to deprecate public APIs if they are part of your product.[1] Deprecating part of an API tells customers not to use that piece of the API, but that it should still work. If it doesn't work properly anymore, then you shouldn't continue to make it available. Many compilers can generate warnings about using deprecated code, which is a great way to make sure that customers using the API are aware of the changes, so long as the warnings can be suppressed when not wanted. API changes should be marked as deprecated in one release and then removed in a later release, giving customers time to update their code. Within the source code, the old, deprecated methods should call the new methods to avoid code duplication. Old classes should inherit from new classes, if possible.
Another question is the file format of upgrade packages. Generally, using the same package format as the original release makes things seem simpler to the customer. Some installation programs are written to require you to uninstall the product first before you upgrade, which always seems heavy-handed to me. Of course, a customer's data and configuration information should never be lost due to an upgrade. Upgrades can fail after they have been installed, for a number of reasons. The converted customer data for the new version may be larger than the installer estimated, causing a lack of disk space to halt the product. The licensing scheme may have changed, and the upgrade was installed without this having been noted. The previous version of the product may have been modified in ways that the installer program knew nothing about, and those changes were lost in the upgrade. These are all problems to consider carefully when designing an upgrade for a product. Products that can have multiple versions of themselves running side by side can make testing upgrades much easier for everyone. This is particularly important for large applications that take a long time to move from evaluation to production. For instance, certifying upgrades of software products in large telecommunication networks often takes many months. Downgrading to a previous version is rarely supported well by most products. Database schemas or configuration file formats may have changed, and there always is the question of what to do with data that doesn't make sense in the older version. Unless the ability to downgrade is noted explicitly in a product, it is wise to assume that only upgrades are supported. 9.2.6. Legal LicensesSection 1.2 covers some of the different legal approaches to distributing both types of software. Deciding on the legal ownership of your product before it is ever released has many advantages. First, changing legal text can affect a large number of source code files, though the source code can usually be updated by a straightforward automated search and replace of copyright notices. Second, installation programs often display license agreements; these too can be changed in their source form. The largest problem with changing the license of your product is the unwanted publicity that can arise. Changing a commercial End User License Agreement (EULA)for instance, to stop competitors from using your product to improve their own productmay go unnoticed. Converting an open source product to a closed license will usually draw some ire and lead to a few forked versions of the code. Oddly enough, even changing a license from closed to open source seems to generate lots of speculation about the business reasons behind the decision. Some informed discussion before your product is released, together with clear and documented decisions about why a particular license was chosen, will help make your legal status clear to customers. 9.2.7. License KeysThis section is about how you allow people to use your productin the practical sense, not just in the legal sense of the previous section. The kind of issues here are how to enable and disable different parts of your product, usually according to how much someone has paid you. Creating software that requires licenses is often frustrating for developers and customers. Developers want to use it without generating licenses, so workarounds and back doors get built into the source code. Customers are frustrated when a license server fails and stops them from using the product they have paid for. So the first thing to consider is whether your product needs license keys at all. If you want people to pay to use it, it probably does, though revenues can also come from installation, configuration, and support consultancy on many open source products. If your product can be decompiled or even run in a debugger, then whatever license scheme you use can be broken eventually, given enough time and effort. If licenses are required, then you need to decide whether they are per user, per machine, per OS, or sitewide. Per-user licenses require some local administration; per-machine licenses will often break if the IP address, network card, or other parts of the machine are changed. If the licenses are time based (maybe because they are evaluation licenses), it's hard to guarantee that the clock on a machine will always be accurate. Some licenses contact a central license server within the customer's network or out on the Internet. Given time, such exchanges can be reverse engineered using network sniffers, as Microsoft has found with Windows XP. However you decide to restrict usage of the program, be careful about how the product operates without the license. Make sure that any transaction or feature is atomic, so that it either works fully or stops working entirely, but nothing in between. Menu choices may be grayed out or, more usefully, they could bring up windows with text about what license is needed, how to obtain the required license, and how to install it to make the software work. The same applies to command-line tools. Hiding license information away in logfiles makes it harder for the customer to understand why your software seems to be broken. A better mechanism to inform customers about when licenses will expire and how to renew them is vital. For cheaper products, allowing the user to purchase a license over the Internet with a credit card and to receive the license by email is one solution that can get the product working quickly. One of the hardest things to decide about products that do use license keys is which features a customer needs to evaluate the product and which features a customer will pay for. It's even harder if there are different levels of licenses. Changing these requirements can result in much tedious development work. One suggestion is to implement licensing in your product in two layers. The lower layer is simply an API for checking whether an operation is permitted. This can be used throughout the code as the product is developed and new features are added. This way, features can be enabled or disabled consistently at design time and can be checked for at many different locations in the software. The higher layer is where a particular licensing scheme is implemented, by checking for different license keys and then enabling or disabling the different pieces of functionality. When a different licensing scheme is decided on, only the higher layer should need to change. Developers using interpreted languages (such as JavaScript or Perl) or languages that use a virtual machine (such as Java) should be particularly careful about decompilation, which will leave the licensing scheme wide open to abuse. There are a number of obfuscation tools that can change the symbols used in your product to make it harder to understand (e.g., by using short variable names and confusing method names). For Java, DashO is one of the better commercial offerings, but the battle between decompilers and obfuscators is a fast-moving one, so you should search for recent evaluation reports before choosing an obfuscator. Other ways to make a licensing scheme more robust are to avoid the string license in any variable that is actually used for licensing; to store any vital secret strings as many smaller strings in different parts of the product; and to check for valid licenses in different ways in many different locations. Creating different releases of the product with the same release number but different ways of checking for licenses means that a crack for one version won't work for every copy of that version. One financial program detected that it was running without the appropriate license but stopped working only about a month before various annual taxes were due, forcing people to purchase legal licenses so that they could submit their paperwork. 9.2.8. Securing Your ReleasesIf your product is distributed over the Internet, then your customers need to have confidence that what they download is the same package that you released. There have been numerous cases of web sites being compromised and modified software being left for customers to download. Once installed, the modified software can be used in turn to compromise even more machines. One common way to increase confidence is to provide customers with checksums of the packages they download, preferably through a separate channel such as an email message. The customer can generate a checksum for the package that she downloaded and compare that checksum with the one that she obtained from you in the email message. An even more secure option is to cryptographically sign the release using a private key and then let customers use the associated public key to decrypt the signature. PGP is a popular way of doing this, and a description of how to confirm releases of the Apache web server can be found at http://httpd.apache.org/dev/verification.html. Another useful resource is the "Strong Distribution HOWTO" article at http://www.cryptnet.net/fdp/crypto/strong_distro.html. Java's JAR files (described in Section 9.4.2, later in this chapter) and Windows executables can also be signed for security. 9.2.9. Quick Fixes and Engineering SpecialsAmong the things that plague software products as they grow are special releases. If they are not carefully controlled, products have ways of getting released that make them practically impossible to support. One way this can happen with closed source products is when you are working with a customer to debug a problem and it's too much overhead to generate a patch release for the customer, so you give the customer the executables from a private build. Once the problem is fixed, the customer may well not want to make any more changes, and so the engineering special becomes a de facto release. Oddly enough, specials happen with open source software too. The usual symptom is someone complaining that something in the product doesn't work as expected, and then you notice some output text included in his bug report that doesn't exist in the product as it was released. It turns out that you are trying to help him debug his modified version of the product, without knowing about the changes he'd made. If such source code changes are necessary to fix a popular piece of functionality, then they should be merged back into the project's source code; otherwise, the project will have effectively forked, and unintentionally at that. The best solution for closed source projects is to track every file given to customers as part of a release and to define a process for unsupported releases. If this process is defined and well known before engineering specials escape to customers, then most developers will be willing to follow it, especially if its turnaround time is quick enough to help with debugging on-site problems. One such minimal procedure for unsupported releases has the following requirements:
There is also the question of what to do when the source code is taken to a customer's site and unsupported releases are created on the spot, perhaps for debugging a problem that can be reproduced only at the customer's site. The same procedure can be followed. Ideally, the SCM tool can work while disconnected from the main server. If not, then a local copy of the affected files can be checked into a local SCM tool on the developer's laptop and then merged back into the original versions back home each night. Having all the benefits of SCM while you are developing on-site is very helpful anyway. |
EAN: 2147483647
Pages: 150