6.3. Evaluating Test Environments At a minimum, a test environment should allow you to: Run a number of tests. Decide whether the tests ran properly and whether any tests hung. A hung test should not prevent other tests from being run. Determine what the result of each test waserror (in the test), failure, or successand also explain why. Summarize the results of the tests in a report.
It is my opinion that a good test environment keeps its tests separate from the mechanism used to run them. To see why, imagine that you want to use a different way of running your tests. You really don't want to have to actually change how any of your tests are written, since the tests are still testing the same parts of your product. A good analogy here is that if you change your build tool from make to SCons, you shouldn't have to change the source code for your product, just the build files. Just like build tools and their build files, test environments benefit from having a good scripting language, one that has full support for familiar programming constructs. If you have to write your scripts and tests using a language that is supported by only one test environment, then changing test environments in the future will be more effort than it needs to be. And frankly, vendor-specific scripting languages are rarely as good as other, better-known scripting languages. Beware vendor lock-in! 6.3.1. Preparing to Test Before you run a single test, make sure that you have a test plan that clearly describes the different parts of the product that will be testedand how, on which platforms, and what the expected results are for each test. Make a list of the required machines and applications for each test, so that you can decide which groups of tests can be run in parallel. When the inevitable time crunch comes for your project, a clear and comprehensive test plan will help you in discussions about which parts of the product perhaps don't need as much testing as other parts. Performance tests should be written with clear expectations of what their approximate results should be. Numbers by themselves are rarely meaningful, so the usefulness of performance tests is often more about how the results change as the values of different dimensions of the product are changed. You should at least be able to predict whether changing a parameter will make a particular result increase or decrease. You should also run performance tests for different durations until you can see the results tending toward a final value or range of valuesfor a short time, a man can outrun a horse, but I wouldn't call it a particularly useful test result. It's also important to make sure that you've identified all the different dimensions that will be considered during testing. For example, for an application that runs on a single machine, you will need values for the operating system and version, disk size, and available memory. Once these dimensions are known, specific combinations of them can be chosen and used during testing. Getting the dimensions wrong is very frustrating for testers; it's annoying enough to have to repeat tests because the product changes, but it's infuriating to have to rerun tests because insufficient data was collected the first time that they were run. Preparing to run the tests should now be a matter of deciding which tests to run, specifying the expected results, checking for the necessary resources, and, most importantly, deciding who will be told about any test failures and who will own any broken (failed) tests. If test results are never used, then the time spent testing is wasted. This sounds obvious, but if developers are not made aware of test results, then it's as though the tests had never been run. A good test environment can help with the following before any tests are run:
Checking resources -
If an external resource (such as a database or a web site) is a prerequisite for running a group of tests, then it often makes sense to check that the resource is available just once, not before every one of the tests.
Defining expected results -
Defining the expected results is part of defining a test. Some tests may be expected to fail. This is true when a bug has been found and a test has been written to demonstrate this failure, but the bug has not yet been fixed. Other failing tests may be tests that are themselves waiting to be fixed.
Tracking primary owners -
Test environments can make it easy to change who owns each test, ideally by using a UI or a simple text search and replace. It should always be easy to identify who will be asked to make a broken test work again. With bugs, even if it's not clear until the bug has been investigated more thoroughly who really owns the faulty code, at least there's a name to start from. If the same test keeps failing due to changes in an unrelated area, then the owner of the test can offer to let the owner of the other area own the test, without having to change who owns the source code.
Tracking secondary owners -
Providing a secondary owner of a test in case the primary owner leaves the project is another useful idea. That way, email messages about failed tests should always reach someone, who may well feel motivated to reassign the tests to a new primary owner, if only to stop the email.
Generating test data -
Some edge cases or boundary conditions can be tested for automatically. For instance, if a method accepts an integer as an argument, then values of 0, -1, and 1 are probably worth using in a unit test. Similarly, very short and very long strings, strings with spaces and punctuation, and non-ASCII strings are all good candidates for testing APIs that have string parameters. If your product uses text files, try passing an executable file to it as an input test.
Handling input data -
If you are using fixed data, make sure it is stored in such a way that it is easy to change, such as in a file that's used for input by the test, rather than being compiled into the test executable. This also implies that test environments should be able to read from datafiles.
Generating random numbers -
A test environment should have a good random number generator for generating data and for making choices in tests. Good ones are hard to find, and they're easy to use in ways that make the results decidedly nonrandom, so guidelines about using them properly are helpful. Somewhat paradoxically, if you do need a random number generator, you should make sure that its output can be precisely repeated, so that you can debug your tests. This is usually done by passing in a "seed value" to the function that initializes the random number generator. Using the same seed value will produce the same sequence of random numbersit's where you start in the sequence that isn't random.
6.3.2. Running the Tests Some aspects of a test environment that help when running tests are:
Single tests -
The ability to run just one test quickly dramatically improves the turnaround time for retesting small parts of a product.
Groups of tests -
Being able to refer to tests in groups and to have the same test be part of multiple groups means that you can run test groups such as "the ones that failed last time" or "just the tests for Windows."
Independent, idempotent tests -
Ideally, tests should have no side effects and should leave the environment in a known state. This means that you should be able to run the same test over and over again, or run the tests in any order. Test environments that help you get this right will save you hours of time trying to debug tests that failed only because the test that was run just before them failed. Running the tests in a different order also simulates more closely how customers may use the product.
Parallel processes -
Tests that have to be run at the same time and be synchronized with each other are hard to run in most test environments. Most testers simply try to avoid these tests or design the product so that it can be put into states where it will wait for certain inputs for synchronization. The useful software clock resolution on many machines without real-time operating systems is only tens of milliseconds, so microsecond synchronization of software is most unlikely to be supported by test environments.
Background processes -
Even if parallel processes don't have to be synchronized with each other, some tests will need processes to run in the background, and output logging and deadlock detection should work for these processes just as they do for other tests. A test environment should also provide a clean way to check for orphaned background processes before the next test starts.
Multiple machines -
The use of multiple machines for a test means that the test environment has to provide a way of executing commands on remote machines, and also a way to collect the results of the commands for processing as part of creating a report. The test itself may have to be written so that it can be started and then wait for a signal to proceed.
Multiple platforms -
Tests that run on many different platforms (for example, both Unix and Windows) benefit greatly from a test environment that hides the differences between the platforms from the person writing tests.
Capturing output -
Good test environments can make capturing both the output and any errors from each test much easier. Keeping textual output and errors in the same place makes it easier to see when errors occurred relative to other output. If they have to remain separate, then timestamps are required, with as much resolution as the platform will provide. It's also helpful to be able to tee the output from each test to be able to monitor the progress of each test.
Scanning output -
When the output of a test has been captured, usually into a file, the result of a test is often determined by searching for certain strings in the output. A good test environment can help by making the common cases simple to implement, while also supporting complex regular expressions or even state machines driven by the content of the output file. If there is some part of the output (such as the starting time or memory addresses) that changes every time a test is run, make sure that this output either is separate from other output or can be filtered by the comparison tools that are being used. Note that the Unix tool grep does not support matches over multiple lines, so you can't use it to search for Number of failures:\n1, where \n is the newline character. However, both Perl and Python do support this.
6.3.3. After the Tests Some features of a test environment that are helpful after tests have been executed include:
Distinguishing between failures and test errors -
Tests can fail; this is expected when a product isn't behaving as expected. Tests can also have errorsthat is, when the tests themselves fail to run correctly. Test environments that make a clear distinction in their test definitions and test reports between these two cases help reduce confusion. Test reports also have to make it clear when a test failure was expected. Of course, tests that fail intermittently without a clear explanation eventually tend to not get run.
Tracking which files were tested -
Since tests may have names like test019 that are unrelated to the source code that they are testing, all other clues about which files, classes, methods, and functions a particular test was exercising are helpful. For instance, you could look at the definition of a test to see which methods it called; or your test environment could provide you with that information and maybe add links to those methods to the detailed parts of test reports.
Flexible report formats -
A wide variety of ways of communicating results is useful. Generating a set of HTML web pages is one common way to present reports, but text-based email, PDF, Word, or spreadsheet files are sometimes more appropriate. To make generating test reports in a variety of formats easier, it's often useful to store the results in a structured file format such as XML. Some test environments use databases to store their test results.
Storing test information -
Once tests have become stable enough to be run automatically as part of a build, it's a good idea to use an SCM tool to store both the source code for the tests and the test results. The tests and their results should be tagged with the same build label that the build was tagged with (see Section 3.5). That way, you know which tests were run against a particular build, and also which versions of those tests were used.
Historical reports -
Some test environments provide tools to create historical reports about test results. Graphs showing the total number and proportion of tests that pass or fail against time can provide a sense of a product's stability. Like any project statistic, these figures are useful only if you understand how the information was gathered and what kinds of errors exist in the data.
Creating bugs -
Once a test has failed, it should be easy to create a bug about the failure. Creating a bug should always have a human involved to act as a filter for what is added to the bug tracking system. However, once the failure has been identified as a genuine bug, filling in the fields of the bug and attaching logfiles should be handled as automatically as possible.
 | Did your test fail with a cryptic error message? After you've searched the open source code for clues about where the message might have come from, your best bet may be to try the Google Universal Debugger. Simply cut and paste the error into a Google search box, optionally add double quotes (") at the start and end of the phrase to keep it together, and then see whether other people have seen the same error. Don't forget to try searching the Google Groups too. |
|
6.3.4. Good Test Reports What should a good test report contain? The answer depends on whom the reports are intended for and how often the reports appear. A manager of a project may be interested only in the total number of tests, the percentage that failed, and perhaps the changes in these numbers since the last test report. Most importantly, a manager will want to know who's going to fix the broken tests. Developers and testers tend to require more detail in test reports. Such information includes a unique name for the test or group of tests, an error state (maybe more than just "passed" or "failed"), links to the logfiles gathered when the tests were run, the duration of the tests, and possibly the expected duration. Output logs should be available in both raw and preprocessed form to highlight warnings, errors, and any other locally interesting text. Since test reports may well be printed on monochrome printers, highlighting of any text should use fonts and border thicknesses, not just color. Another helpful idea is to add links to reports to allow readers to browse each test definition and the areas of the source code that are being tested. Figure 6-1 shows an example of a crisp and clear test report. The more information that appears in a test report about the environment in which the tests were run, the easier it is to recreate that environment later on, or in a different location. Section 9.2.4 discusses the kind of information to gather for releases, and much of the same information is useful for test reports. A useful guideline for the design of a good test report is to remove everything that doesn't directly provide information to the reader. Every line on every page is a potentially distracting piece of clutter for someone scanning the report in a hurry. A classic book on this subject that I can thoroughly recommend is Edward Tufte's The Visual Display of Quantitative Information (Graphics Press). Examples from all of his excellent books can be found at http://www.edwardtufte.com. Figure 6-1. An example of a clear set of test results 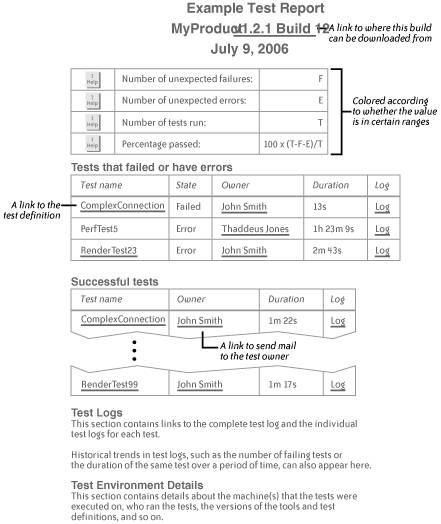
|