Fundamental Components
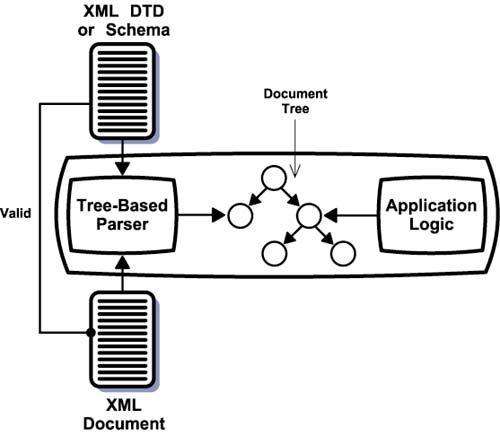
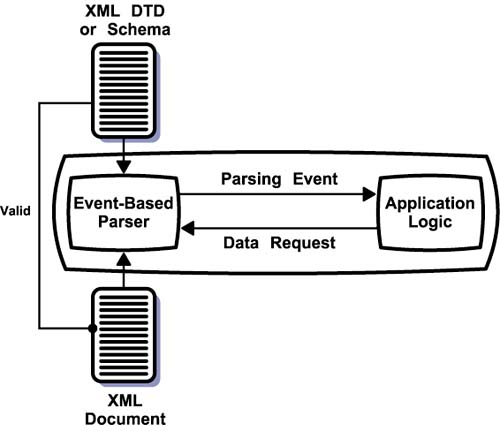
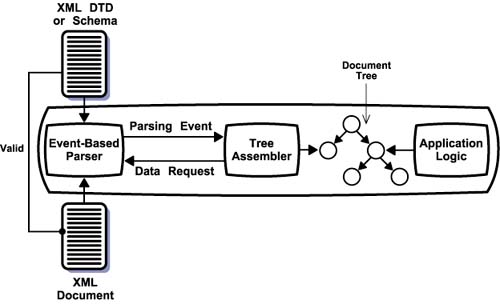
Fundamental ComponentsXML defines a standard for encoding documents to facilitate seamless information exchange. Obviously, for such exchanges actually to take place, all parties must be able to process XML documents. If they use related feature standards, such as XSLT or Schema, they must be able to handle those formats. Applications need these basic processing capabilities to realize the benefits of the XML paradigm. The software engines that perform this essential work are the fundamental components. The biggest workhorse in the XML paradigm is, of course, the XML processor. This piece of software can read an XML-formatted file and provide the encoded data to other software components. Most XML processors also understand DTDs, Schema, and Namespaces. Many can process XPath statements. Other fundamental components, such as those for processing XSLT and XLink, rely on the XML processor because the standards they implement use XML syntax. Therefore, a basic understanding of XML processors is essential to understanding the architecture of XML-based applications. An XML processor is typically embedded in an application. It reads the physical files associated with a document and converts the document text into programming constructs accessible to the application logic. There are two basic types of processors: tree-based and event-based . Figure 5-2 shows the operation of a tree-based processor. It accepts an XML document as input and then parses the document to create a hierarchical data structure that is an in-memory representation of the data contained in the document. Optionally, it may also accept an XML DTD or Schema, in which case it verifies that the document follows the specified rules. Figure 5-2. Tree-based XML Processor Application logic accesses the hierarchical data structure through an application programming interface ( API ) provided by the processor. The Document Object Model ( DOM ) is another W3C Recommendation that defines the characteristics of the document tree and the API for manipulating it. A tree-based processor does not have to support DOM to support XML; it may have a proprietary type of data tree and API. However, DOM support is a good idea because it ensures that developers can learn this one API and use any compliant processor. DOM and proprietary APIs allow developers to write application logic that moves through the document's tree of data, extracting and evaluating the information required to execute application functions. In addition to DOM or other tree API, many tree-based processors also support the use of XPath expression to access nodes within the data hierarchy as described in Chapter 3. This process can also work in reverse. An application can use the processor's API to create a new tree, add nodes to the tree, and fill them with data. The processor uses this newly created tree of data to create a corresponding XML document. In this case, the application logic and processor work together as a document generator. Optionally, it can check to make sure that the generated document conforms to a specified DTD or Schema. Tree-based processors are highly effective for applications that need random access to document elements. The application can use the API to navigate the path to any piece of data. However, building a complete tree for every document can consume a substantial amount of memory. Event-based processors avoid this cost because they do not create an in-memory data structure for the entire document. Instead of creating a data structure and letting the application logic access it, event-based processors send just event descriptions to the application logic. These events include the beginning and end of each element but not its attributes or text content. If the application logic is interested in that particular element, it requests additional data from the processor. This approach is highly effective when an application accesses each element sequentially or needs access only to a known subset of elements. Figure 5-3 shows how this process works. As with tree-based processors, event-based processors can also take an optional XML DTD or Schema against which it validates the input document. Figure 5-3. Event-based XML Processor The Simple API for XML ( SAX ) is a commonly used event API for XML processors. Example 5-1 illustrates the types of events a SAX-based processor would generate when processing the order document in Example 2-6. As you can see, the processor does not include any element content or attribute information. When the application logic receives an event signifying the beginning of an element whose content it wants to access, it must specifically request information about that element. Example 5-1Start document Start element: Addresses Start element: Address Start element: FirstName End element: FirstName Start element: LastName End element: LastName ... End element: Address Start element: Address ... End element: Address End element: Addresses Start element: LineItems Start element: LineItem Start element: Product End element: Product Start element: Quantity End element: Quantity ... End element: LineItem Start element: LineItem ... End element: LineItem End element: LineItems ... End Document In practice, many XML processors support both tree-based and event-based APIs. This support stems from the fact that it's easy to build a tree-based processor on top of an event-based processor. To build the in-memory data tree, the tree-based processor acts like any other application from the perspective of the event-based processor. The only difference is that it always requests all the information about an element. It then takes this information and puts it in the data tree. Figure 5-4 shows how this process works. Developers that want a tree-based API enable the tree assembly functions of the processor, while developers that want an event-based API suppress them. The advantage of this dual architecture is that both types of developers can use the same component. Figure 5-4. Dual Mode XMl Parser Figures 5-2, 5-3, and 5-4 show processors accepting a DTD or Schema as input along with the XML document. In such cases, the processor validates the document against the rules specified in the DTD or Schema. Such processors are called validating processors . Most of the major validating processors now support Schema as well as DTDs. However, applications do not have to use the validating features of such processors. There are also nonvalidating processors designed for applications that require only well- formed documents. Both open source projects and software vendors provide XML processors. The Apache Software Foundation provides the popular Xerces open source processor for both Java and C++, although the Java version is usually somewhat ahead of the C++ version in terms of features. Microsoft provides an XML processor as part of its operating systems and makes this component easily accessible from its development tools. Oracle has C, C++, and PL/SQL processors for use with its database and middleware products. There are open source processors for many other languages, including JavaScript, Perl, and Python. After XML processors, the next most important fundamental component is the XSLT processor. XSLT has rapidly achieved widespread acceptance and is an important technology for many data- and content-oriented applications. The Apache Software Foundation provides an XSLT processor called Xalan in both Java and C++ flavors. Microsoft and Oracle also provide XSLT companions to their XML processors. There are other less-known open source and commercial XSLT processors, but the complexity of XSLT has limited their proliferation . The availability of XSLFO formatters and XLink processors is not as great. These feature standards are just beginning to see substantial use, and their areas of application lend themselves less well to distribution as components. XSLFO is relevant primarily as part of publishing systems, while XLink is primarily relevant as part of hypertext systems. This is not to say that corresponding fundamental components are not available, only that their number and quality are less than for XML and XSLT. At the time of this writing, there were a few open source XSLFO formatters, notably FOP from the Apache Software Foundation and PassiveTeX from the Text Encoding Initiative. Commercially, Antenna House's XSL Formatter and RenderX's XEP Rendering Engine were available. All tend to focus on PDF output. For XLink, empolis's X2X and Fujitsu XLink Processor (XLiP) both handle extended links but require fees for commercial use. |
EAN: 2147483647
Pages: 75