Operational Profile of a Use Case Package
| To this point, we've looked at how to describe and use an operational profile for the scenarios that make up a single use case. Of course, few projects deal with just a single use case, so next we turn to the question of how to describe and use an operational profile for a package of use cases. Operational profiles are a part of Binder's Extended Use Case Test Design Pattern (2003), and he offers the following simple example of a system with two use cases, search and update. If you have a product in which, on average, 90,000 searches and 10,000 updates are done daily, the relative frequency of the search and update use cases are .90 and .10, respectively (see Table 3.2).
Notice that this technique does not require a decision graph. It simply estimates the number of times a use case is used per unit time and then calculates the relative frequency, or probability, from that. This is as about as straightforward and simple a way as there is to construct an operational profile for a package of use cases. Sanity Check Before ProceedingUML provides for the modeling of generalizations of, and extensions and addition of behavior to, base use cases. In the next section, we are going to look at how to build operational profiles for use cases that utilize these relationships.[1] If you don't use these relationships, what was covered in the previous section will be plenty to get you started building operational profiles for a package of use cases. So, if you do not use these relationships, feel free to skip ahead to examples of using the operational profile in planning (see "Working Smarter: Use Case Packages" section).
Use Case RelationshipsUML provides simple notation to describe the relationships between use cases. With the release of UML version 1.3, these relationships received major revision, adding a new relationshipgeneralizationand redefining others.[2] The list that follows includes definitions for the relationships that can be expressed between use cases as they stand in version 2.0 of UML (Rumbaugh, Jacobson, and Booch 2003).
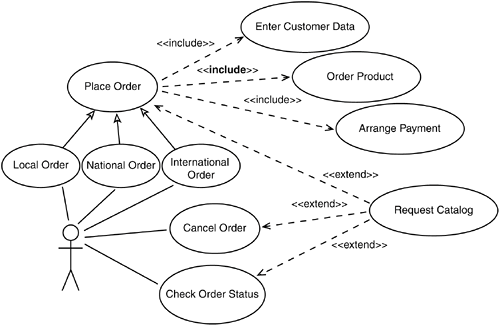
An example will help illustrate these relationships. For the task at hand I'll focus on those aspects of the relationships that are pertinent to building an operational profile. Sales Order ExampleFigure 3.11 presents a typical sales order use case diagram utilizing relationships generalization, include, and extend.[3] In this example, we have six base use cases (i.e. those that are not inclusions or extensions). First is Place Order; this is a generalization that specifies the common behavior of all place order use cases.
Figure 3.11. Use case diagram illustrating relationships between use cases.
The next three use casesPlace Local Order (in state), National Order (out of state), and International Order (out of the country)are children of Place Order and inherit all its properties and behavior, just like inheritance in objects. Each of the children then specialize these properties and behavior to accommodate their respective situations in terms for example of tax, regulations governing shipping across state and international boundaries, tariffs, and so on. The last two base use cases are Cancel Order and Check Order Status, whose functions should be self-evident. In what follows, we are going to build an operational profile for our sales order example. We'll proceed like this:
At that point, our operational profile will be complete. Step 1Start with Base Use CasesWe begin our operational profile with the base use casesthose to which inclusions/extensions are madeand estimate the number of times each is executed in some unit of time; here, daily (see Figure 3.12). This information would come from empirical field data, usability studies, or simply your best educated guess. Notice that in this table Place Order, the parent in the generalization relationship of Figure 3.11, is shown with a zero: it turns out to be an abstract use case (i.e., it is not fully specified to the point it can be instantiated for standalone use and is used solely for defining the common properties and behavior of its children). For an operational profile, this determination needs to be made for all use case generalizations. Figure 3.12. Base use cases and estimate of times per day each is executed. The zero for Place Order (circled) indicates that it is an abstract use case: not fully specified and never instantiated for use standalone.
Step 2Include and Extend Use Cases Used StandaloneNext, we turn our attention to the four include/extend use cases; these are use cases that are used to extend base use cases (Request Catalog in Figure 3.11) or be included in base use cases (Enter Customer Data, Order Product, Arrange Payment in Figure 3.11). But a pertinent aspect of these use cases with regards to operational profiles is that per the UML, they may possibly be used as standalone use cases. Given they are fully specified (i.e., are not "fragments") they can be instantiated and used as regular use cases (Rumbaugh, Jacobson, and Booch 2005). Another way to look at this, which might make more sense: the UML provides for the use of otherwise "regular" use cases to be used as extensions and inclusions to other "regular" use cases. In such a case, the operational profile needs to take into account such usage. Figure 3.13 reflects this new information and shows the number of times a day we estimate these use cases will be used standalone: instantiated and executed as regular use cases by themselves, rather than in the role of an extension or inclusion to another base use case. Figure 3.13. Times per day include and extend use cases are executed standalone. Zeroes (circled) indicate that these use cases are never used standalone.
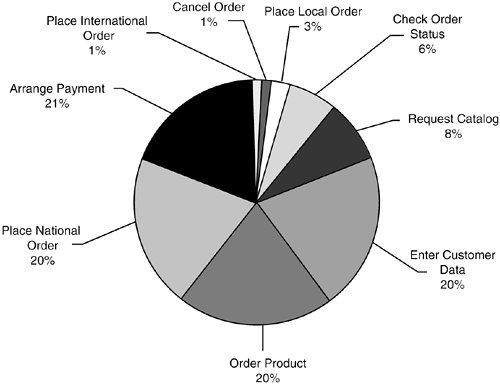
In Figure 3.13, notice that use cases Enter Customer Data and Order Product are shown with zeroes (circled). This indicates that these particular use cases are never expected to be used standalone; they are only used as inclusions to base uses cases. Both Enter Customer Data and Order Product, while necessary, are not sufficient to be standalone in and of themselves (they are use case fragments, i.e., not fully specified, and can't be instantiated). Arrange Payment and Request Catalog, on the other hand, are fully specified, able to be instantiated, and expected to be used daily at the specified rates. Taking Request Catalog, for example, we expect that about forty times a day a customer will phone a salesperson for the sole purpose of requesting a new catalog. Step 3Include and Extend Use Cases Used with Base Use CasesThe last step in our operational profile is to account for the number of times that include and extend use cases are executed as a result of being inclusions and extensions of base use cases. In Figure 3.14, notice that the operational profile now includes a matrix titled Probability of Use by Base Use Case that describes the include and extend relationships shown in Figure 3.11. Rows of the matrix correspond to base use cases, and columns correspond to include or extend use cases. Figure 3.14. Operational profile with matrix describing probability that a base use case will invoke an inclusion or extension. The circle indicates that Request Catalog extends base use case Check Order Status with probability .20, or 20% of the time.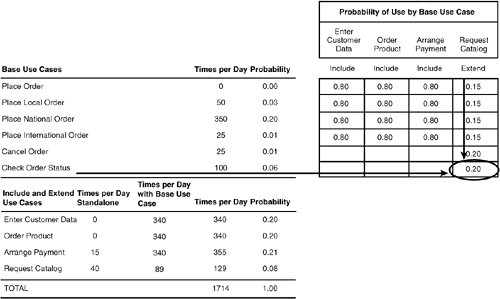 A cell in the matrix provides the probability with which we expect the base use case to actually invoke the inclusion or extension. For example, the cell marked by a circle in Figure 3.14 indicates that with a probability of .20think 20 times in every 100 times some customer calls a salesperson to check on their orderwe expect the customer to additionally request a catalog. Given that we expect the Check Order Status use case to execute 100 times a day, we would then expect the Request Catalog to be used 20 times a day as an extension to Check Order Status. This same principle is used for each include and extend use case; the number of times the base use case is executed daily is multiplied times the probability of invocation of the include/extend use case to come up with an estimate of the number of times the include/extend use case is used. In Excel, this is easily done with the SUMPRODUCT function; Figure 3.15 shows the formula for calculating the number of times a day Request Catalog is used as an extension by the base use cases. Figure 3.15. Use of SUMPRODUCT function to calculate estimate of number of times Request Catalog is invoked as an extension daily.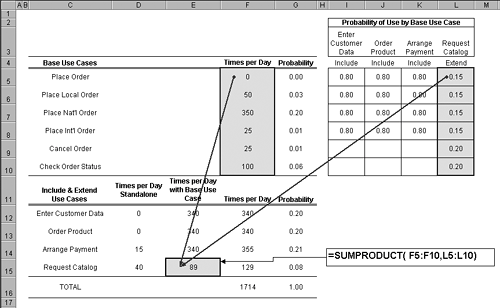 The grand total number of times an include/extend use case is used daily is the sum of the times it is used standalone plus the number of times it is used as an inclusion or extension. After the total number of daily executions of both base use cases and include/extend use cases is available, the overall probability of each use case relative to the rest can be calculated; see spreadsheet columns F and G in Figure 3.15. A pie chart of the operational profile is shown in Figure 3.16. Figure 3.16. Operational profile of sales order example shown as pie chart.
Remember that a base use case combined with an include/extend use case results in a new use case composed of the two. But keep in mind that the frequency of use information in the operational profile addresses the base use case and include/extend use cases separately: any reference to the base use case in the operational profile refers to just the base use case, not the use case formed by inclusion/extension. With the operational profile in hand, we now have a quantitative way to allocate effort and resources to these use cases in a way that matches their expected frequency of use by the customer. But before we look at examples of how to work smartly with this operational profile, some discussion is in order about establishing the probabilities with which base use cases actually use include/extend use cases. Probability that Include/Extend Use Cases Are Actually UsedThe matrix of Figure 3.14 titled Probability of Use by Base Use Case describes the include/extend relationships shown in Figure 3.11. Each cell in the matrix provides the probability with which we expect the base use case (row) to actually invoke the include/extend use case (column). But where do we get those probabilities? How do we know what reasonable values would be? In what follows, let's look at the detailed way to approach this question and then conclude with a quick, low-tech way. By understanding the detailed way first, you'll have a little better feeling about applying the low-tech way. The Detailed ApproachInclusions and extensions in UML both have the property that flow of control returns to the base use case at the same point where the inclusion/extension took place (i.e., the inclusion point or extension point, respectively).[4] Inclusion/extension points are like discrete points on a use case path that are either expanded in-line like a macro (my mental model for include) or act like a subroutine call which leaves and returns to the same point (my mental model for extend).
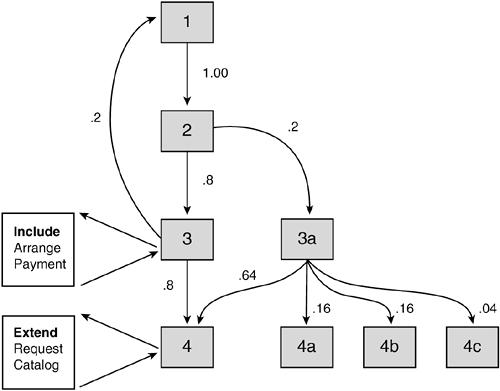
Given this, let's return to the decision graph of our stylized use case of Figure 3.2 and imagine that it is the decision graph of base use case Place Order of the use case diagram of Figure 3.11 and the operational profile of Figure 3.14. Then let's say that steps 3 and 4 of the decision graph of Place Order are in fact the inclusion and extension points for Arrange Payment and Request Catalog use cases, respectively, as illustrated in Figure 3.17. Figure 3.17. Decision graph of base use case Place Order with arrange Payment as an inclusion point (step 3) and Request Catalog as an extension point (step 4).
Working from Figure 3.17, let's now ask the question again: What is the probability that Place Order will actually invoke the Arrange Payment inclusion or the Request Catalog extension? Let's start with Arrange Payment. Table 3.3 provides the probability of each of the scenarios of Figure 3.17. (This is simply a reprint of Table 3.1, so look there if you are unsure how it was built.)
In which scenarios do we invoke the inclusion of Arrange Payment (remember, it is step 3)? It is invoked in scenarios 1, 2, 3, 4 and 1, 2, 3, 1. By adding the probability of these two scenarios, we get the probability that Place Order will invoke the Arrange Payment inclusion:
OK, now how about the Request Catalog? In which scenarios do we invoke the Request Catalog extension (remember, it is step 4)? It is invoked in scenarios 1, 2, 3, 4 and 1, 2, 3a, 4. So the probability of invoking the Request Catalog is:
Well, that isn't quite true for Request Catalog; it's an extend use case so it's a tad messier (notice how things never get a tad simpler?). Remember the UML definition of an extend use case: the extension is "subject to specific conditions specified in the extension." If the condition, specified as part of the extend use case, is met, the extension is executed; otherwise, the base use case flow resumes as is (i.e., the extension becomes a "no-op"nothing happens). For our particular example, we would likely need field data to indicate the frequency with which a catalog is requested in conjunction with placing an order; otherwise, we make an educated guess. Let's try the educated guess route and use our Pareto Principle heuristic from earlier in the chapter. First, what is the most likely event from high to low, to request a catalog or not? You decide that no catalog request is probably the most likely of the two. OK, our Pareto heuristic says that 20% of the exit paths from a use case step will account for 80% of the traffic. Because we've only got two possible choicesthey request a catalog or notwe take the probability of no catalog request at .8, which means that the probability for a catalog request is .2. To summarize, the probability that the Place Order use case invokes the Request Catalog extension is the probability of the use case flow taking one of the scenarios on which the request catalog extension lies (scenarios 1, 2, 3, 4 and 1, 2, 3a, 4 of Figure 3.17) times the probability that the customer actually wants a new catalog when asked:
A Quick, Low-Tech Pareto Principle ApproachTo recap what we've just learned, the probability that a base use case will use an include use case is the sum of the probabilities of the scenarios of which it is a part. The probability that a base use case will use an extend use case is the sum of probabilities of scenarios of which it is a part times the probability that the condition for extension is met. Now that we understand how it works, maybe we can take a short cut and make some guesstimates. And, of course, if we don't have operational profiles for the base use cases, we'll have to guesstimate anyway. Let's take what we've learned about include/extend use cases, re-apply some of the Pareto Principle heuristics from the "Pareto Principle and Guesstimates" section, and see if we can get some ballpark probabilities for include/extend use cases as at least a starting guesstimate. Figure 3.18 illustrates a quick and dirty Pareto-based heuristic for guesstimating the probability that a base use case will actually use an include/extend use case; a heuristic like this would be used in the absence of empirical data or in the absence of an operational profile of the base use case. Figure 3.18. Pareto-based heuristic for guesstimating the probability that a base use case will actually use an include/extend use case. First, we guesstimate the probability that the base use case flow takes one of the scenarios on which the inclusion/extension point lies; this is row 1, 2 and 3 of Figure 3.18. If there is just one scenario in the use case (row 1), the probability is, of course, 1.0. If there is more than one scenario in the use case, we ask which is more likely: that the inclusion/extension point lies on one of the high traffic scenario paths (row 2) or not (row 3)? We assign the probabilities of .8 and .2 for each of these events, respectively. Second, we guesstimate the probability that if the inclusion/extension point is reached it will actually be utilized. For include use cases, this is easy: UML tells us that if they are encountered they are always utilized, so probability = 1.0 (column 1). For extension points, we ask which is more likely: that when the extension point is reached it will be used (column 2) or not (column 3). We assign the probabilities of .8 and .2 to each of these events, respectively. That's it. Quick and low tech. But if you don't have any better data, it's probably as safe a guesstimate as you can make. Simply find the cell that matches your need and use that probability as a ballpark starting place; let your instincts take it from there to tweak as you feel is right. Concluding Thoughts About Use Case RelationshipsAs you saw in the previous section, accounting for include and extend relationships can make what started out as a simple approach to operational profiles quite a bit more complicated. It could, however, be worth the effort to identify early in development common parts of the systemrepresented as include and extend use casesthat are shaping up as hot spots of traffic in the system. The same idea is used in the profiling of code where you are looking for components or subroutines that are utilized heavily by other code. Such hot spots are good candidates for making highly performant, easy to use, and reliable. Use case generalizations are more straightforward to address in the operational profile: parents and children of a generalization relationship are treated as regular use cases listing their frequency of use separately for each. The only special issue is when the parent use case is an abstract use case (i.e., one that is not fully specified and cannot be instantiated). Abstract use cases should be excluded from the operational profile or receive a zero for frequency of use as was done in Figure 3.12 for use case Place Order. |

EAN: 2147483647
Pages: 109