Index Organization
Think of the indexes that you see in your everyday life—those in books and other documents. Suppose you're trying to write a SELECT statement in SQL Server using the CASE expression, and you're using two SQL Server documents to find out how to write the statement. One document is the Microsoft SQL Server 2000 Transact-SQL Language Reference Manual. The other is this book, Inside Microsoft SQL Server 2000. You can quickly find information in either book about CASE, even though the two books are organized differently.
In the T-SQL language reference, all the information is organized alphabetically. You know that CASE will be near the front, so you can just ignore the last 80 percent of the book. Keywords are shown at the top of each page to tell you what topics are on that page. So you can quickly flip through just a few pages and end up at a page that has BREAK as the first keyword and CEILING as the last keyword, and you know that CASE will be on this page. If CASE is not on this page, it's not in the book. And once you find the entry for CASE, right between BULK INSERT and CAST, you'll find all the information you need, including lots of helpful examples.
Next, you try to find CASE in this book. There are no helpful key words at the top of each page, but there's an index at the back of the book and all the index entries are organized alphabetically. So again, you can make use of the fact that CASE is near the front of the alphabet and quickly find it between "cascading updates" and "case-insensitive searches." However, unlike in the reference manual, once you find the word CASE, there are no nice neat examples right in front of you. Instead, the index gives you pointers. It tells you what pages to look at—it might list two or three pages that point you to various places in the book. If you look up SELECT in the back of the book, however, there might be dozens of pages listed, and if you look up SQL Server, there might be hundreds.
These searches through the two books are analogous to using clustered and nonclustered indexes. In a clustered index, the data is actually stored in order, just as the reference manual has all the main topics in order. Once you find the data you're looking for, you're done with the search. In a nonclustered index, the index is a completely separate structure from the data itself. Once you find what you're looking for in the index, you have to follow pointers to the actual data. A nonclustered index in SQL Server is very much like the index in the back of this book. If there is only one page reference listed in the index, you can quickly find the information. If a dozen pages are listed, it's quite a bit slower. If hundreds of pages are listed, you might think there's no point in using the index at all. Unless you can narrow down your topic of interest to something more specific, the index might not be of much help.
In Chapter 3, I explained that both clustered and nonclustered indexes in SQL Server store their information using standard B-trees, as shown in Figure 8-1. A B-tree provides fast access to data by searching on a key value of the index. B-trees cluster records with similar keys. The B stands for balanced, and balancing the tree is a core feature of a B-tree's usefulness. The trees are managed, and branches are grafted as necessary, so that navigating down the tree to find a value and locate a specific record takes only a few page accesses. Because the trees are balanced, finding any record requires about the same amount of resources, and retrieval speed is consistent because the index has the same depth throughout.
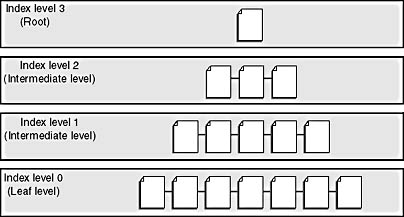
Figure 8-1. A B-tree for a SQL Server index.
An index consists of a tree with a root from which the navigation begins, possible intermediate index levels, and bottom-level leaf pages. You use the index to find the correct leaf page. The number of levels in an index will vary depending on the number of rows in the table and the size of the key column or columns for the index. If you create an index using a large key, fewer entries will fit on a page, so more pages (and possibly more levels) will be needed for the index. On a qualified select, update, or delete, the correct leaf page will be the lowest page of the tree in which one or more rows with the specified key or keys reside. A qualified operation is one that affects only specific rows that satisfy the conditions of a WHERE clause, as opposed to accessing the whole table. In any index, whether clustered or nonclustered, the leaf level contains every key value, in key sequence.
Clustered Indexes
The leaf level of a clustered index contains the data pages, not just the index keys. Another way to say this is that the data itself is part of the clustered index. A clustered index keeps the data in a table ordered around the key. The data pages in the table are kept in a doubly linked list called the page chain. The order of pages in the page chain, and the order of rows on the data pages, is the order of the index key or keys. Deciding which key to cluster on is an important performance consideration. When the index is traversed to the leaf level, the data itself has been retrieved, not simply pointed to.
Because the actual page chain for the data pages can be ordered in only one way, a table can have only one clustered index. The query optimizer strongly favors a clustered index because such an index allows the data to be found directly at the leaf level. Because it defines the actual order of the data, a clustered index allows especially fast access for queries looking for a range of values. The query optimizer detects that only a certain range of data pages must be scanned.
Most tables should have a clustered index. If your table will have only one index, it generally should be clustered. Many documents describing SQL Server indexes will tell you that the clustered index physically stores the data in sorted order. This can be misleading if you think of physical storage as the disk itself. If a clustered index had to keep the data on the actual disk in a particular order, it could be prohibitively expensive to make changes. If a page got too full and had to be split in two, all the data on all the succeeding pages would have to be moved down. Sorted order in a clustered index simply means that the data page chain is in order. If SQL Server follows the page chain, it can access each row in clustered index order, but new pages can be added by simply adjusting the links in the page chain. I'll tell you more about page splitting and moving rows in Chapter 9 when I discuss data modification.
In SQL Server 2000, all clustered indexes are unique. If you build a clustered index without specifying the unique keyword, SQL Server forces uniqueness by adding a uniqueifier to the rows when necessary. This uniqueifier is a 4-byte value added as an additional sort key to only the rows that have duplicates of their primary sort key. You'll be able to see this extra value when we look at the actual structure of index rows later in this chapter.
Nonclustered Indexes
In a nonclustered index, the lowest level of the tree (the leaf level) contains a bookmark that tells SQL Server where to find the data row corresponding to the key in the index. As you saw in Chapter 3, a bookmark can take one of two forms. If the table has a clustered index, the bookmark is the clustered index key for the corresponding data row. If the table is a heap (in other words, it has no clustered index), the bookmark is a RID, which is an actual row locator in the form File#:Page#:Slot#. (In contrast, in a clustered index, the leaf page is the data page.)
The presence or absence of a nonclustered index doesn't affect how the data pages are organized, so you're not restricted to having only one nonclustered index per table, as is the case with clustered indexes. Each table can include as many as 249 nonclustered indexes, but you'll usually want to have far fewer than that.
When you search for data using a nonclustered index, the index is traversed and then SQL Server retrieves the record or records pointed to by the leaf-level indexes. For example, if you're looking for a data page using an index with a depth of three—a root page, one intermediate page, and the leaf page—all three index pages must be traversed. If the leaf level contains a clustered index key, all the levels of the clustered index then have to be traversed to locate the specific row. The clustered index will probably also have three levels, but in this case remember that the leaf level is the data itself. There are two additional index levels separate from the data, typically one less than the number of levels needed for a nonclustered index. The data page still must be retrieved, but because it has been exactly identified there's no need to scan the entire table. Still, it takes six logical I/O operations to get one data page. You can see that a nonclustered index is a win only if it's highly selective.
Figure 8-2 illustrates this process without showing you the individual levels of the B-trees. I want to find the first name for the employee named Anson, and I have a nonclustered index on the last name and a clustered index on the employee ID. The nonclustered index uses the clustered keys as its bookmarks. Searching the index for Anson, SQL Server finds that the associated clustered index key is 7. It then traverses the clustered index looking for the row with a key of 7, and it finds Kim as the first name in the row I'm looking for.
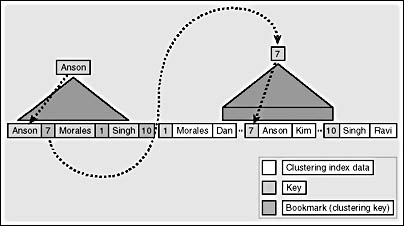
Figure 8-2. SQL Server traverses both the clustered and nonclustered indexes to find the first name for the employee named Anson.
EAN: 2147483647
Pages: 179