Managing Memory
One of the major goals of SQL Server 2000 was to scale easily from a laptop installation on Windows 98 to an SMP server running on Windows 2000 DataCenter Server. This ability to scale requires a robust policy for managing memory. By default, SQL Server 2000 adjusts its use of system memory to balance the needs of other applications running on the machine and the needs of its own internal components. These other applications can include other instances of SQL Server running on the same machine.
When determining the optimal amount of memory to dynamically allocate to SQL Server, the memory manager strives to keep at least 4 MB of memory completely free and available for the operating system, but it might try to keep more available. The amount of free space reserved for the operating system is partially determined by the average life expectancy of a page in cache. The memory manager determines a Life Expectancy value that indicates how many seconds, on average, a page stays in cache if it isn't referenced at all. Performance Monitor has a counter that allows you to view the current Life Expectancy value. That value is of course only an estimate, and it's based on the speed at which the lazywriter checks for referenced pages and the total amount of memory available. (I'll talk about the lazywriter later in this section.) If the average Life Expectancy of a page is small, the memory manager tries to keep the reserve memory at about 4 MB to increase the amount of memory available to SQL Server. If the average Life Expectancy increases, the space reserved for the operating system increases to up to 10 MB and the total memory for SQL Server decreases. All instances of SQL Server on a single machine tend to work toward the same reserve value and a similar Life Expectancy value.
As an alternative to dynamically computing the total amount of memory, you can configure SQL Server to use a fixed amount of memory. Whether memory allocation is fixed or dynamically adjusted, the total memory space for each instance is considered one unified cache and is managed as a collection of various pools with their own policies and purposes. Memory can be requested by and granted to any of several internal components.
The Buffer Manager and Memory Pools
The main memory component in SQL Server is the buffer pool; all memory not used by another memory component remains in the buffer pool. The buffer manager manages disk I/O functions for bringing data and index pages into the buffer pool so that data can be shared among users. When other components require memory, they can request a buffer from the buffer pool. A buffer is a page in memory that's the same size as a data or index page. You can think of it as a page frame that can hold one page from a database.
Another memory pool is the operating system itself. Occasionally, SQL Server must request contiguous memory in larger blocks than the 8-KB pages that the buffer pool can provide. Typically, use of large memory blocks is kept to a minimum, so direct calls to the operating system account for a small fraction of SQL Server's memory usage.
You can think of the procedure cache as another memory pool, in which query trees and plans from stored procedures, triggers, user-defined functions or ad hoc queries can be stored. Other pools are used by memory-intensive queries that use sorting or hashing, and by special memory objects that need less than one 8-KB page.
Access to In-Memory Pages
Access to pages in the buffer pool must be fast. Even with real memory, it would be ridiculously inefficient to have to scan the whole cache for a page when you have hundreds of megabytes, or even gigabytes, of data. To avoid this inefficiency, pages in the buffer pool are hashed for fast access. Hashing is a technique that uniformly maps a key via a hash function across a set of hash buckets. A hash bucket is a structure in memory that contains an array of pointers (implemented as a linked list) to the buffer pages. If all the pointers to buffer pages do not fit on a single hash page, a linked list chains to additional hash pages.
Given a dbid-fileno-pageno identifier (a combination of the database ID, file number, and page number), the hash function converts that key to the hash bucket that should be checked; in essence, the hash bucket serves as an index to the specific page needed. By using hashing, even when large amounts of memory are present, SQL Server can find a specific data page in cache with only a few memory reads. Similarly, it takes only a few memory reads for SQL Server to determine that a desired page is not in cache and that it must be read in from disk.
NOTE
Finding a data page might require that multiple hash buckets be accessed via the chain (linked list). The hash function attempts to uniformly distribute the dbid-fileno-pageno values throughout the available hash buckets. The number of hash buckets is set internally by SQL Server and depends on the total size of the buffer pool.
Access to Free Pages (Lazywriter)
You can use a data page or an index page only if it exists in memory. Therefore, a buffer in the buffer pool must be available for the page to be read into. Keeping a supply of buffers available for immediate use is an important performance optimization. If a buffer isn't readily available, many memory pages might have to be searched simply to locate a buffer to free up for use as a workspace.
The buffer pool is managed by a process called the lazywriter that uses a clock algorithm to sweep through the buffer pool. Basically, a lazywriter thread maintains a pointer into the buffer pool that "sweeps" sequentially through it (like the hand on a clock). As the lazywriter visits each buffer, it determines whether that buffer has been referenced since the last sweep by examining a reference count value in the buffer header. If the reference count is not 0, the buffer stays in the pool and its reference count is adjusted downward in preparation for the next sweep; otherwise, the buffer is made available for reuse: it is written to disk if dirty, removed from the hash lists, and put on a special list of buffers called the free list.
NOTE
The set of buffers that the lazywriter sweeps through is sometimes called the LRU (for least recently used list). However, it doesn't function as a traditional LRU because the buffers do not move within the list according to their use or lack of use; the lazywriter clock hand does all the moving. Also note that the set of buffers that the lazywriter inspects actually includes more than pages in the buffer pool. The buffers also include pages from compiled plans for procedures, triggers, or ad hoc queries.
The reference count of a buffer is incremented each time the buffer's contents are accessed by any process. For data or index pages, this is a simple increment by one. But objects that are expensive to create, such as stored procedure plans, get a higher reference count that reflects their "replacement cost." When the lazywriter clock hand sweeps through and checks which pages have been referenced, it does not use a simple decrement. It divides the reference count by 4. This means that frequently referenced pages (those with a high reference count) and those with a high replacement cost are "favored" and their count will not reach 0 any time soon, keeping them in the pool for further use. The lazywriter hand sweeps through the buffer pool when the number of pages on the free list falls below its minimum size. The minimum size is computed as a percentage of the overall buffer pool size but is always between 128 KB and 4 MB. SQL Server 2000 estimates the need for free pages based on the load on the system and the number of stalls occurring. A stall occurs when a process needs a free page and none is available; the process goes to sleep and waits for the lazywriter to free some pages. If a lot of stalls occur—say, more than three or four per second—SQL Server increases the minimum size of the free list. If the load on the system is light and few stalls occur, the minimum free list size is reduced and the excess pages can be used for hashing additional data and index pages or query plans. The Performance Monitor has counters that let you examine not only the number of free pages but also the number of stalls occurring.
User threads also perform the same function of searching for pages that can be placed on a free list. This happens when a user process needs to read a page from disk into a buffer. Once the read has been initiated, the user thread checks to see whether the free list is too small. (Note that this process consumes one page of the list for its own read.) If so, the user thread performs the same function as the lazywriter: it advances the clock hand and searches for buffers to free. Currently, it advances the clock hand through 16 buffers, regardless of how many it actually finds to free in that group of 16. The reason for having user threads share in the work of the lazywriter is to distribute the cost across all of the CPUs in an SMP environment. In fact, SQL Server 2000 actually has a separate free list for each CPU to help further distribute the cost and improve scalability. A user thread that needs a free page first checks the free list for the CPU it is running on; only if no pages are available will the user thread check the free lists for other CPUs.
Keeping pages in the cache permanently
You can specially mark tables so that their pages are never put on the free list and are therefore kept in memory indefinitely. This process is called pinning a table. Any page (data, index, or text) belonging to a pinned table is never marked as free and never reused unless it is unpinned. Pinning and unpinning is accomplished using the pintable option of the sp_tableoption stored procedure. Setting this option to TRUE for a table doesn't cause the table to be brought into cache, nor does it mark pages of the table as "favored" in any way; instead, it avoids the unnecessary overhead and simply doesn't allow any pages belonging to that table to be put on the free list for possible replacement.
Because mechanisms such as write-ahead logging and checkpointing are completely unaffected, such an operation in no way impairs recovery. Still, pinning too many tables can result in few or even no pages being available when a new buffer is needed. In general, you should pin tables only if you've carefully tuned your system, plenty of memory is available, and you have a good feel for which tables constitute hot spots.
Pages that are "very hot" (accessed repeatedly) are never placed on the free list. A page in the buffer pool that has a nonzero use count, such as a newly read or newly created page, is not added to the free list until its use count falls to 0. Before that point, the page is clearly hot and isn't a good candidate for reuse. Very hot pages might never get on the free list, even if their objects aren't pinned—which is as it should be.
Checkpoints
Checkpoint operations minimize the amount of work that SQL Server must do when databases are recovered during system startup. Checkpoints are run on a database-by-database basis. They flush dirty pages from the current database out to disk so that those changes don't have to be redone during database recovery. A dirty page is one that has been modified since it was brought from disk into the buffer pool. When a checkpoint occurs, SQL Server writes a checkpoint record to the transaction log, which lists all the transactions that are active. This allows the recovery process to build a table containing a list of all the potentially dirty pages.
Checkpoints are triggered when:
- A database owner explicitly issues a checkpoint command to perform a checkpoint in that database.
- The log is getting full (more than 70 percent of capacity) and the database is in SIMPLE recovery mode, or the option trunc. log on chkpt. is set. (I'll tell you about recovery modes in Chapter 5.) A checkpoint is triggered to truncate the transaction log and free up space. However, if no space can be freed up, perhaps because of a long running transaction, no checkpoint occurs.
- A long recovery time is estimated. When recovery time is predicted to be longer than the recovery interval configuration option, a checkpoint is triggered. SQL Server 2000 uses a simple metric to predict recovery time because it can recover, or redo, in less time than it took the original operations to run. Thus, if checkpoints are taken at least as often as the recovery interval frequency, recovery completes within the interval. A recovery interval setting of 1 means that checkpoints occur at least every minute as long as transactions are being processed in the database. A minimum amount of work must be done for the automatic checkpoint to fire; this is currently 10 MB of log per minute. In this way, SQL Server doesn't waste time taking checkpoints on idle databases. A default recovery interval of 0 means that SQL Server chooses an appropriate value automatically; for the current version, this is one minute.
In a system with a large amount of memory, checkpoints can potentially generate lots of write operations to force all the dirty pages out to disk. To limit the amount of resources checkpoints can consume, SQL Server limits checkpoint operations to a maximum of 100 concurrent write operations. That might seem like a large number of writes, but on a huge system, even 100 concurrent writes can take a long time to write out all the dirty pages. To optimize checkpoints and to make sure that checkpoints don't need to do any more work than necessary, the checkpoint algorithm keeps track of a generation number for each buffer in the cache. Without this number to help keep track of the work that's been done, checkpoint operations could potentially write the same pages to disk multiple times.
Checkpoints and Performance Issues
A checkpoint is issued as part of an orderly shutdown, so a typical recovery upon restart takes only seconds. (An orderly shutdown occurs when you explicitly shut down SQL Server, unless you do so via the SHUTDOWN WITH NOWAIT command. An orderly shutdown also occurs when the SQL Server service is stopped through Service Control Manager or the net stop command from an operating system prompt.) Although a checkpoint speeds up recovery, it does slightly degrade run-time performance.Unless your system is being pushed with high transactional activity, the run-time impact of a checkpoint probably won't be noticeable. You can also use the sp_configure recovery interval option to influence checkpointing frequency, balancing the time to recover vs. any impact on run-time performance. If you're interested in tracing how often checkpoints actually occur, you can start your SQL Server with trace flag 3502, which writes information to SQL Server's error log every time a checkpoint occurs.
The checkpoint process goes through the buffer pool, scanning the pages in buffer number order, and when it finds a dirty page, it looks to see whether any physically contiguous (on the disk) pages are also dirty so that it can do a large block write. But this means that it might, for example, write pages 14, 200, 260, and 1000 at the time that it sees page 14 is dirty. (Those pages might have contiguous physical locations even though they're far apart in the buffer pool. In this case, the noncontiguous pages in the buffer pool can be written as a single operation called a gather-write. I'll define gather-writes in more detail later in this chapter.) As the process continues to scan the buffer pool, it then gets to page 1000. Potentially, this page could be dirty again, and it might be written out a second time. The larger the buffer pool, the greater the chance that a buffer that's already been written will get dirty again before the checkpoint is done. To avoid this, each buffer has an associated bit called a generation number. At the beginning of a checkpoint, all the bits are toggled to the same value, either all 0's or all 1's. As a checkpoint checks a page, it toggles the generation bit to the opposite value. When the checkpoint comes across a page whose bit has already been toggled, it doesn't write that page. Also, any new pages brought into cache during the checkpoint get the new generation number, so they won't be written during that checkpoint cycle. Any pages already written because they're in proximity to other pages (and are written together in a gather write) aren't written a second time.
Accessing Pages Using the Buffer Manager
The buffer manager handles the in-memory version of each physical disk page and provides all other modules access to it (with appropriate safety measures). The memory image in the buffer pool, if one exists, takes precedence over the disk image. If the page is dirty, the copy of the data page in memory includes updates that have not yet been written to disk. When a page is needed for a process, it must exist in memory in the buffer pool. If the page isn't there, a physical I/O is performed to get it. Obviously, because physical I/Os are expensive, the fewer physical I/Os you have to perform the better. The more memory there is (the bigger the buffer pool), the more pages can reside there and the more likely a page can be found there.
A database appears as a simple sequence of numbered pages. The dbid-fileno-pageno identifier uniquely specifies a page for the entire SQL Server environment. When another module (such as the access methods manager, row manager, index manager, or text manager) needs to access a page, it requests access from the buffer manager by specifying the dbid-fileno-pageno identifier.
The buffer manager responds to the calling module with a pointer to the memory buffer holding that page. The response might be immediate if the page is already in the cache, or it might take an instant for a disk I/O to complete and bring the page into memory. Typically, the calling module also requests that the lock manager perform the appropriate level of locking on the page. The calling module notifies the buffer manager if and when it is finished dirtying, or making updates to, the page. The buffer manager is responsible for writing these updates to disk in a way that coordinates with logging and transaction management.
Large Memory Issues
Systems with hundreds of megabytes of RAM are not uncommon. In fact, for benchmark activities, Microsoft runs with a memory configuration of as much as 2 GB of physical RAM. Using the Enterprise Edition of SQL Server allows the use of even more memory. The reason to run with more memory is, of course, to reduce the need for physical I/O by increasing your cache-hit ratio.
Memory: How Much Is Too Much?
Some systems cannot benefit from huge amounts of memory. For example, if you have 2 GB of RAM and your entire database is 1 GB, you won't even be able to fill the available memory, let alone benefit from its size. A pretty small portion of most databases is "hot," so a memory size that's only a small percentage of the entire database size can often yield a high cache-hit ratio. If you find that SQL Server is doing a lot of memory-intensive processing, such as internal sorts and hashing, you can add additional memory. Adding memory beyond what's needed for a high cache-hit ratio and internal sorts and hashes might bring only marginal improvement.
The Enterprise Edition of SQL Server 2000 running on Windows 2000 can use as much memory as Windows 2000 Advanced Server or Windows 2000 DataCenter Server allows by using the Windows 2000 Address Windowing Extensions (AWE) API to support extra large address spaces. You must specifically configure an instance of SQL Server to use the AWE extensions; the instance can then access up to 8 GB of physical memory on Advanced Server and up to 64 GB on DataCenter Server. Although standard 32-bit addressing supports only 4 GB of physical memory, the AWE extensions allow the additional memory to be acquired as nonpaged memory. The memory manager can then dynamically map views of the nonpaged memory to the 32-bit address space.
You must be very careful when using this extension because nonpaged memory cannot be swapped out. Other applications or other instances of SQL Server on the same machine might not be able to get the memory they need. You should consider manually configuring the maximum amount of physical memory that SQL Server can use if you're also going to enable it to use AWE. I'll talk more about configuring memory in Chapter 17.
Read ahead
SQL Server supports a mechanism called read ahead, whereby the need for data and index pages can be anticipated and pages can be brought into the buffer pool before they're actually read. This performance optimization allows large amounts of data to be processed effectively. Read ahead is managed completely internally, and no configuration adjustments are necessary. In addition, read ahead doesn't use separate operating system threads. This ensures that read ahead stays far enough—but not too far—ahead of the scan of the actual data.
There are two kinds of read ahead: one for table scans on heaps and one for index ranges. For table scans, the table's allocation structures are consulted to read the table in disk order. Up to 32 extents (32 * 8 pages/extent * 8192 bytes/page = 2 MB) of read ahead are outstanding at a time. Four extents (32 pages) at a time are read with a single 256-KB scatter read. (Scatter-gather I/O was introduced in Windows NT 4, Service Pack 2, with the Win32 functions ReadFileScatter and WriteFileGather.) If the table is spread across multiple files in a file group, SQL Server has one read ahead thread per file. In SQL Server Standard Edition, each thread can still read up to 4 extents at a time from a file, and up to 32 files can be processed concurrently. This means that the read ahead threads can process up to 128 pages of data. In SQL Server Enterprise Edition, more extents can be read from each file, and more files can be processed concurrently. In fact there is no set upper limit to number of extents or number of files; SQL Server Enterprise Edition can read ahead enough data to fill 1 percent of the buffer pool.
For index ranges, the scan uses level one of the index structure (the level immediately above the leaf) to determine which pages to read ahead. When the index scan starts, read ahead is invoked on the initial descent of the index to minimize the number of reads performed. For instance, for a scan of WHERE state = 'WA', read ahead searches the index for key = 'WA', and it can tell from the level one nodes how many pages have to be examined to satisfy the scan. If the anticipated number of pages is small, all the pages are requested by the initial read ahead; if the pages are contiguous, they're fetched in scatter reads. If the range contains a large number of pages, the initial read ahead is performed and thereafter every time another 16 pages are consumed by the scan, the index is consulted to read in another 16 pages. This has several interesting effects:
- Small ranges can be processed in a single read at the data page level whenever the index is contiguous.
- The scan range (for example, state = 'WA') can be used to prevent reading ahead of pages that won't be used since this information is available in the index.
- Read ahead is not slowed by having to follow page linkages at the data page level. (Read ahead can be done on both clustered indexes and nonclustered indexes.)
NOTE
Scatter-gather I/O and asynchronous I/O are available only to SQL Server running on Windows 2000 or Windows NT. This includes the Personal Edition of SQL Server if it has been installed on Windows 2000 Professional or Windows NT Workstation.
Merry-Go-Round Scans
The Enterprise Edition of SQL Server 2000 includes another optimization to improve the performance of nonordered scans (a scan that isn't requested to be in any particular order), particularly if multiple nonordered scans of the same table are requested simultaneously by different processes. Without this optimization, one process can start scanning and get perhaps 20 percent of the way through the table before another process requests the same data. If the cache is small, or is used by other processes for completely unrelated data, the pages scanned by the original process might have been swapped out, which means that the buffer manager has to go back to disk to get the first pages of this table again. When the original scanning process resumes, any pages that were read in ahead might be gone, and more disk reads have to be done. This can cause some serious disk thrashing. A new optimization called Merry-Go-Round scans allows SQL Server 2000 Enterprise Edition to avoid this thrashing by allowing the second process to start at the same point the original process already reached. Both processes can then read the same data, and each page can be read from disk only once and be used by both scans. When the first process finishes, the second process can read the initial 20 percent of the table. Figure 3-5 illustrates a Merry-Go-Round scan.
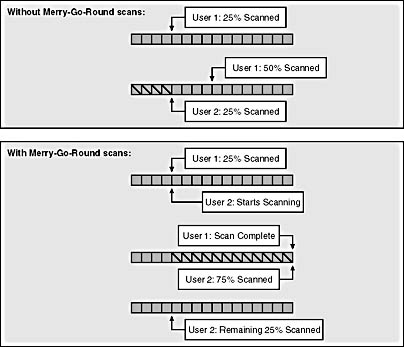
Figure 3-5. SQL Server Enterprise Edition's Merry-Go-Round Scan.
The Log Manager
All changes are "written ahead" by the buffer manager to the transaction log. This means that the log records for a transaction are always written to disk before the changed data pages are written. Write-ahead logging ensures that all databases can be recovered to a consistent state, even in the event of a complete server failure, as long as the physical medium (hard disk) survives. A process never receives acknowledgment that a transaction has been committed unless it is on disk in the transaction log. For this reason, all writes to the transaction log are synchronous—SQL Server must wait for acknowledgment of completion. Writes to data pages can be made asynchronously, without waiting for acknowledgment, because if a failure occurs the transactions can be undone or redone from the information in the transaction log.
The log manager formats transaction log records in memory before writing them to disk. To format these log records, the log manager maintains regions of contiguous memory called log caches. In SQL Server 2000, log records do not share the buffer pool with data and index pages. Log records are maintained only in the log caches.
To achieve maximum throughput, the log manager maintains two or more log caches. One is the current log cache, in which new log records are added. In addition, there are one or more log caches available to be used when the current log cache is filled. The log manager also has two queues of log caches: a flushQueue, which contains filled log caches waiting to be flushed, and a freeQueue, which contains log caches that have no data (because they have been flushed) and can be reused.
When a user process requires that a particular log cache be flushed (for example, when a transaction commits), the log cache is placed into the flushQueue (if it isn't already there). Then the thread (or fiber) is put into the list of connections waiting for the log cache to be flushed. The connection does not do further work until its log records have been flushed.
The log writer is a dedicated thread that goes through the flushQueue in order and flushes the log caches out to disk. The log caches are written one at a time. The log writer first checks to see whether the log cache is the current log cache. If it is, the log writer pads the log cache to sector alignment and updates some header information. It then issues an I/O event for that log cache. When the flush for a particular log cache is completed, any processes waiting on that log cache are woken up and can resume work.
EAN: 2147483647
Pages: 179