Transaction Log Basics
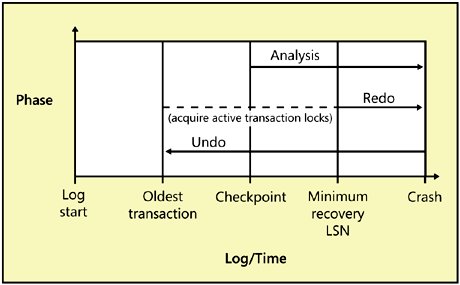
| The transaction log records changes made to the database and stores enough information to allow SQL Server to recover the database. As we'll see later in this chapter, the recovery process takes place every time a SQL Server instance is started, and it can optionally take place every time SQL Server restores a database or a log from backup. Recovery is the processing of reconciling the data files and the log files. Any changes to the data that the log indicates have been committed must appear in the data files, and any changes that are not marked as committed must not appear in the data files. The log also stores information needed to roll back an operation if SQL Server receives a request to roll back a transaction from the client (using the ROLLBACK TRAN command) or if an error, such as a deadlock, generates an internal ROLLBACK. Physically, the transaction log is one or more files associated with a database at the time the database is created or altered. Operations that perform database modifications write records in the transaction log that describe the changes made (including the page numbers of the data pages modified by the operation), the data values that were added or removed, information about the transaction that the modification was part of, and the date and time of the beginning and end of the transaction. SQL Server also writes log records when certain internal events happen, such as checkpoints. Each log record is labeled with a log sequence number (LSN) that is guaranteed to be unique. All log entries that are part of the same transaction are linked together so that all parts of a transaction can be easily located for both undo activities (as with a rollback) and redo activities (during system recovery). The Buffer Manager guarantees that the transaction log will be written before the changes to the database are written. (This is called write-ahead logging.) This guarantee is possible because SQL Server keeps track of its current position in the log by means of the LSN. Every time a page is changed, the LSN corresponding to the log entry for that change is written into the header of the data page. Dirty pages can be written to disk only when the LSN on the page is less than or equal to the LSN for the last page written to the log. The Buffer Manager also guarantees that log pages are written in a specific order, making it clear which log blocks must be processed after a system failure, regardless of when the failure occurred. The log records for a transaction are written to disk before the commit acknowledgement is sent to the client process, but the actual changed data might not have been physically written out to the data pages. Although the writes to the log are asynchronous, at commit time the thread must wait for the writes to complete to the point of writing the commit record in the log for the transaction. (SQL Server must wait for the commit record to be written so that it knows the relevant log records are safely on disk.) Writes to data pages are completely asynchronous. That is, writes to data pages need only be posted to the operating system, and SQL Server can check later to see that they were completed. They don't have to be completed immediately because the log contains all the information needed to redo the work, even in the event of a power failure or system crash before the write completes. The system would be much slower if it had to wait for every I/O request to complete before proceeding. Logging involves demarcating the beginning and end of each transaction (and savepoints, if a transaction uses them). Between the beginning and ending demarcations is information about the changes made to the data. This information can take the form of the actual "before and after" data, or it can refer to the operation that was performed so that those values can be derived. The end of a typical transaction is marked with a Commit record, which indicates that the transaction must be reflected in the database's data files or redone if necessary. A transaction aborted during normal runtime (not system restart) due to an explicit rollback or something like a resource error (for example, an out-of-memory error) actually undoes the operation by applying changes that undo the original data modifications. The records of these changes are written to the log and marked as "compensation log records." As mentioned earlier, there are two types of recovery, and both have the goal of making sure the log and the data are in agreement. A restart recovery runs every time SQL Server is started. The process runs on each database because each database has its own transaction log. Your SQL Server error log will report the progress of restart recovery, and for each database the log will tell you how many transactions were rolled forward and how many were rolled back. This type of recovery is sometimes referred to as "crash" recovery because a crash, or unexpected stopping of the SQL Server service, requires the recovery process to be run when the service is restarted. If the service was shut down cleanly with no open transactions in any database, only minimal recovery is necessary upon system restart. In SQL Server 2005, restart recovery can be run on multiple databases in parallel, each handled by a different thread. The other type of recovery, restore recovery (or media recovery), is run by request when a restore operation is executed. This process makes sure that all the committed transactions in the backup of the transaction log are reflected in the data and that any transactions that did not complete do not show up in the data. I'll talk more about restore recovery later in the chapter. Both types of recovery must deal with two situations: when there are transactions recorded as committed in the log but not yet written to the data files and when there are changes to the data files that don't correspond to committed transactions. These two situations can occur because committed log records are written to the log files on disk every time a transaction commits. Changed data pages are written to the data files on disk completely asynchronously, every time a checkpoint occurs in a database. As I mentioned in Chapter 2, data pages can also be written to disk at other times, but the regularly occurring checkpoint operations give SQL Server a point at which all changed (or dirty) pages are known to have been written to disk. Checkpoint operations also write log records from transactions in progress to disk because the cached log records are also considered to be dirty. If the SQL Server service is stopped after a transaction commits but before the data is written out to the data pages, when SQL Server starts up and runs recovery, the transaction must be rolled forward. SQL Server essentially redoes the transaction by reapplying the changes indicated in the transaction log. All the transactions that need to be redone are processed first (even though some of them might need to be undone later during the next phase). This is called the REDO phase of recovery. If a checkpoint occurs before a transaction is committed, it will write the uncommitted changes out to disk. If the SQL Server service is then stopped before the commit occurs, the recovery process will find the changes for the uncommitted transactions in the data files, and it will have to roll back the transaction by undoing the changes reflected in the transaction log. Rolling back all the incomplete transactions is called the UNDO phase of recovery. I'll continue to refer to recovery as a system startup function, which is its most common role by far. However, remember that recovery is also run during the final step of restoring a database from backup and can also be forced manually. Later in this chapter, I'll cover some special issues related to recovery during a database restore. These include the three recovery modes that you can set using the ALTER DATABASE statement and the ability to place a named marker in the log to indicate a specific point to recover to. The discussion that follows deals with recovery in general, whether it's performed when the SQL Server service is restarted or when a database is being restored from a backup. Phases of RecoveryDuring recovery, only changes that occurred or were in progress since the last checkpoint are redone or undone. Any transactions that completed prior to the last checkpoint, either by being committed or rolled back, will be accurately reflected in the data pages, and no additional work will need to be done for them during recovery. The recovery algorithm has three phases, which center around the last checkpoint record in the transaction log. The three phases are illustrated in Figure 5-1.
Figure 5-1. The three phases of the SQL Server recovery process SQL Server 2005 uses the log to keep track of the data modifications that were made, as well as any locks that were applied to the objects being modified. This allows SQL Server 2005 to support a feature called fast recovery when SQL Server is restarted (in the Enterprise and Developer editions only). With fast recovery, the database is available as soon as the redo phase is finished. The same locks that were acquired during the original modification can be reacquired to keep other processes from accessing the data that needs to have its changes undone; all other data in the database remains available. Fast recovery cannot be done during media recovery. In addition, SQL Server 2005 uses multiple threads to process the recovery operations on the different databases, so databases with higher ID numbers don't have to wait for all databases with lower ID numbers to be completely recovered before their own recovery process starts. Page LSNs and RecoveryEvery database page has an LSN in the page header that reflects the location in the transaction log of the last log entry that modified a row on this page. Each log record for changes to a data page has two LSNs associated with it. In addition to the LSN for the actual log record, it also keeps track of the LSN which was on the data page before the change recorded by this log record. During a redo operation of transactions, the LSNs on each log record are compared to the page LSN of the data page that the log entry modified. If the page LSN is equal to the previous page LSN in the log record, the operation indicated in the log entry is redone. If the LSN on the page is equal to or higher than the actual LSN for this log record, SQL Server will skip the REDO operation. These two possibilities are illustrated in Figure 5-2. The LSN on the page cannot be in between the previous and current value for the log record. Figure 5-2. Comparing LSNs to decide whether to process the log entry during recovery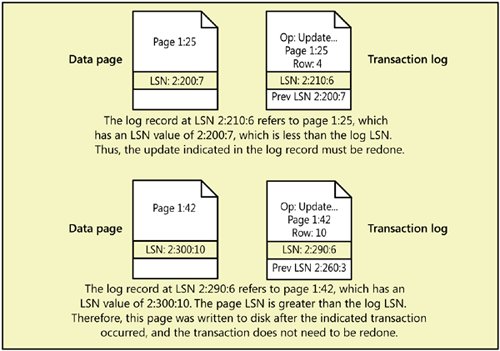 Because recovery finds the last checkpoint record in the log (plus transactions that were still active at the time of the checkpoint) and proceeds from there, recovery time is short, and all changes committed before the checkpoint can be purged from the log or archived. Otherwise, recovery could take a long time and transaction logs could become unreasonably large. A transaction log cannot be truncated prior to the point of the earliest transaction that is still open, no matter how many checkpoints have occurred since the transaction started and no matter how many other transactions have started or completed. If a transaction remains open, the log must be preserved because it's still not clear whether the transaction is done or ever will be done. The transaction might ultimately need to be rolled back or rolled forward. Note
Some SQL Server administrators have noted that the transaction log seems unable to be truncated, even after the log has been backed up. This problem often results from a process opening a transaction and then forgetting about it. For this reason, from an application development standpoint, you should ensure that transactions are kept short. Another possible reason for an inability to truncate the log relates to a table being replicated using transactional replication when the replication log reader hasn't processed all the relevant log records yet. This situation is less common, however, because typically a latency of only a few seconds occurs while the log reader does its work. You can use DBCC OPENTRAN to look for the earliest open transaction or the oldest replicated transaction not yet processed and then take corrective measures (such as killing the offending process or running the sp_repldone stored procedure to allow the replicated transactions to be purged). I'll discuss problems with transaction management and some possible solutions in Chapter 8. I'll discuss shrinking of the log in the next section. |
EAN: 2147483647
Pages: 115