More on Closure
| When I say the output from each algebraic operation is another relation, I hope it's clear that I'm talking from a conceptual point of view. I don't mean the system actually has to materialize that output in its entirety. For example, consider the following expression (a restriction of a join Tutorial D on the left, SQL on the right): ( P JOIN S ) | SELECT P.*, WHERE PNAME > SNAME | S.SNO, S.SNAME, S.STATUS | FROM P, S | WHERE P.CITY = S.CITY | AND P.PNAME > S.SNAME Clearly, as soon as a given tuple of the join is formed, the system can test that tuple right away against the restriction condition PNAME > SNAME (P.PNAME > S.SNAME in the SQL version) to see if it belongs in the final output and discard it if not. Thus, the intermediate result that's the output from the join might never exist as a fully materialized relation in its own right at all. (In fact, of course, the system tries very hard not to materialize intermediate results in their entirety, for obvious performance reasons.) The foregoing example raises another important point, however. Consider the boolean expression PNAME > SNAME in the Tutorial D version. That expression applies, conceptually, to the result of P JOIN S, and the attribute names PNAME and SNAME in that expression therefore refer to attributes of that result not to the attributes of those names in relvars P and S. But how do we know the result includes any such attributes? What is the heading of that result? More generally, how do we know what the heading is for the result of any algebraic operation? Clearly, what we need is a set of inference rules to be more specific, relation type inference rules such that if we know the type(s) of the input relation(s) for any given operation, we can infer the type of the output relation from that operation. In the case of join, for example, those rules say the output from P JOIN S is of this type: RELATION { PNO PNO, PNAME NAME, COLOR COLOR, WEIGHT WEIGHT, CITY CHAR, SNO SNO, SNAME NAME, STATUS INTEGER } In fact, for join, the heading of the output is the union of the headings of the inputs where by union I mean the regular set-theoretic union, not the special relational union I'll be discussing later in this chapter. In other words, the output has all of the attributes of the inputs, except that common attributes just CITY in the example appear once, not twice. Of course, those attributes don't have any left-to-right order, so I could equally well say that (for example) the type of the result of P JOIN S is this: RELATION { SNO SNO, PNO PNO, SNAME NAME, PNAME NAME, CITY CHAR, STATUS INTEGER, WEIGHT WEIGHT, COLOR COLOR } Note that type inference rules of some kind are definitely needed in order to support the closure property fully. Closure says that every result is a relation, and relations have not just a body but also a heading; thus, every result must have a proper relational heading as well as a proper relational body. The RENAME operator mentioned in this chapter's introduction is needed in large part to support the relational model's type inference rules. RENAME takes one relation as input and returns another relation as output; the output relation is identical to the input relation, except that one of its attributes has a different name. For example (Tutorial D on the left and SQL on the right): S RENAME ( CITY AS SCITY ) | SELECT S.SNO, S.SNAME, S.STATUS, | S.CITY AS SCITY | FROM S Given our usual sample values, the result looks like this: 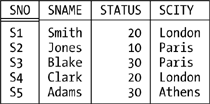 (I won't usually bother to show results explicitly in this chapter unless I think the particular operator I'm talking about might be unfamiliar to you, as in the case at hand.) NOTE Important: The foregoing example does not change relvar S in the database! RENAME isn't like SQL's ALTER TABLE; the RENAME invocation is only an expression (just as, for example, P JOIN S or N+2 are only expressions), and like any expression it simply denotes a certain value. What's more, of course, since it is an expression, not a statement or "command," it can be nested inside other expressions. We'll see plenty of examples later. So how does SQL handle this business of specifying result attribute names (or column names, rather)? The answer is: not very well. First of all, we saw in Chapter 3 that SQL doesn't really have a notion of "relation type" anyway (it has row types instead). Second, it can produce results with columns that effectively have no name at all (for example, consider SELECT DISTINCT P.WEIGHT * 2 FROM P). Third, it can also produce results with duplicate column names (for example, consider SELECT DISTINCT P.CITY, S.CITY FROM P, S). Finally, let's take another look at the example from the beginning of this section: ( P JOIN S ) | SELECT P.*, WHERE PNAME > SNAME | S.SNO, S.SNAME, S.STATUS | FROM P, S | WHERE P.CITY = S.CITY | AND P.PNAME > S.SNAME As you can see, the counterpart to Tutorial D's PNAME > SNAME in the SQL version is P.PNAME > S.SNAME which is curious, because that expression is supposed to apply to the result of the FROM clause, and relvars P and S certainly aren't part of that result! Indeed, it's quite difficult to explain how something like P.PNAME in the WHERE and SELECT clauses (and possibly elsewhere in the overall expression) can make any sense at all in terms of the result of the FROM clause. The SQL standard does explain it, but the machinations it has to go through in order to do so are much more complicated than Tutorial D's rules so much so that I won't even try to explain them here, but will simply rely on the fact that they can be explained if necessary. I justify the omission by appealing to the fact that this book is supposed to be about the relational model, not SQL. Now I'd like to go on to describe some other algebraic operators. Please note that I'm not trying to be exhaustive in what follows; I won't be covering "all known operators," and I won't even define all of the operators I do cover in full generality. In most cases, in fact, I'll just give a careful but somewhat informal definition and show some simple examples. |
EAN: 2147483647
Pages: 127