Why Duplicate Tuples Are Prohibited
| There are numerous practical arguments in support of the position that duplicate tuples ("duplicates" for short) should be prohibited. Here I have room for just one but I think it's a powerful one. However, it does rely on certain notions I haven't discussed yet in this book, so I need to make a couple of preliminary assumptions:
Now I can present my argument. The fundamental point I want to make is that certain expression transformations, and hence certain optimizations, that are valid in a relational context are not valid in the presence of duplicates. By way of example, consider the (nonrelational) database shown in Figure 3-1. Figure 3-1. A nonrelational database, with duplicates Before going any further, perhaps I should ask the question: what does it mean to have three <P1,Screw> rows in table P and not two, or four, or seventeen?[
So I have to assume there's some meaning attached to the duplication, even though that meaning, whatever it is, is hardly very explicit. (I note in passing, therefore, that duplicates contravene one of the original objectives of the relational model: explicitness. The meaning of the data should be as obvious and explicit as possible, since we're supposed to be talking about a shared database. The presence of duplicates implies that part of the meaning is hidden.) In other words, given that duplicates do have some meaning, there are presumably going to be business decisions made on the basis of the fact that, for example, there are three <P1,Screw> rows in table P and not two or four or seventeen. If not, then why are the duplicates there in the first place? Now consider the following query: "Get part numbers for parts that either are screws or are supplied by supplier S1, or both." Here are some candidate SQL formulations for this query, together with the output produced in each case: 1 SELECT P.PNO FROM P WHERE P.PNAME = NAME('Screw') OR P.PNO IN ( SELECT SP.PNO FROM SP WHERE SP.SNO = SNO('S1') ) Result: P1 * 3, P2 * 1. 2 SELECT SP.PNO FROM SP WHERE SP.SNO = SNO('S1') OR SP.PNO IN ( SELECT P.PNO FROM P WHERE P.PNAME = NAME('Screw') ) Result: P1 * 2, P2 * 1. 3 SELECT P.PNO FROM P, SP WHERE ( SP.SNO = SNO('S1') AND SP.PNO = P.PNO ) OR P.PNAME = NAME('Screw') Result: P1 * 9, P2 * 3. 4 SELECT SP.PNO FROM P, SP WHERE ( SP.SNO = SNO('S1') AND SP.PNO = P.PNO ) OR P.PNAME = NAME('Screw') Result: P1 * 8, P2 * 4. 5 SELECT P.PNO FROM P WHERE P.PNAME = NAME('Screw') UNION ALL SELECT SP.PNO FROM SP WHERE SP.SNO = SNO('S1') Result: P1 * 5, P2 * 2. 6 SELECT DISTINCT P.PNO FROM P WHERE P.PNAME = NAME('Screw') UNION ALL SELECT SP.PNO FROM SP WHERE SP.SNO = SNO('S1') Result: P1 * 3, P2 * 2. 7 SELECT P.PNO FROM P WHERE P.PNAME = NAME('Screw') UNION ALL SELECT DISTINCT SP.PNO FROM SP WHERE SP.SNO = SNO('S1') Result: P1 * 4, P2 * 2. 8 SELECT DISTINCT P.PNO FROM P WHERE P.PNAME = NAME('Screw') OR P.PNO IN ( SELECT SP.PNO FROM SP WHERE SP.SNO = SNO('S1') ) Result: P1 * 1, P2 * 1. 9 SELECT DISTINCT SP.PNO FROM SP WHERE SP.SNO = SNO('S1') OR SP.PNO IN ( SELECT P.PNO FROM P WHERE P.PNAME = NAME('Screw') ) Result: P1 * 1, P2 * 1. 10 SELECT P.PNO FROM P GROUP BY P.PNO, P.PNAME HAVING P.PNAME = NAME('Screw') OR P.PNO IN ( SELECT SP.PNO FROM SP WHERE SP.SNO = SNO('S1') ) Result: P1 * 1, P2 * 1. 11 SELECT P.PNO FROM P, SP GROUP BY P.PNO, P.PNAME, SP.SNO, SP.PNO HAVING ( SP.SNO = SNO('S1') AND SP.PNO = P.PNO ) OR P.PNAME = NAME('Screw') Result: P1 * 2, P2 * 2. 12 SELECT P.PNO FROM P WHERE P.PNAME = NAME('Screw') UNION SELECT SP.PNO FROM SP WHERE SP.SNO = SNO('S1') Result: P1 * 1, P2 * 1.NOTE Actually, certain of the foregoing formulations which? are a little suspect, because they assume that every screw is supplied by at least one supplier. But this fact has no material effect on the argument that follows. The obvious first point is that the twelve different formulations produce nine different results different, that is, with respect to their degree of duplication. (I make no claim, incidentally, that the twelve different formulations and the nine different results are the only ones possible; indeed, they aren't, in general.) Thus, if the user really cares about duplicates, he or she needs to be extremely careful in formulating the query in such a way as to obtain exactly the desired result. Furthermore, of course, analogous remarks apply to the system itself: because different formulations can produce different results, the optimizer too has to be extremely careful in its task of expression transformation. For example, the optimizer isn't free to transform, say, formulation 1 into formulation 3 or the other way around, even if it would like to. In other words, duplicate rows act as a significant optimization inhibitor. Here are some implications of this fact:
The fact that duplicates serve as an optimization inhibitor is particularly frustrating in view of the fact that, in most cases, users probably don't care how many duplicates appear in the result. In other words:
On the basis of examples like the foregoing, I'm tempted to conclude among other things that you should always ensure that query results contain no duplicates for example, by always specifying DISTINCT in your SQL queries and thus simply forget about the whole problem. And if you follow this advice, of course, then there's no good reason for allowing duplicates in the first place . . . . There's much more that could be said on this issue, but I have room for just four more points. First, the alternative to SELECT DISTINCT in SQL is SELECT ALL and SELECT ALL is unfortunately the default. The trouble is, however, SELECT DISTINCT might take longer to execute than SELECT ALL, even if the DISTINCT is effectively a "no op." I don't want to discuss this one any further, except to note that the reason SQL systems are typically unable to optimize properly over duplicate elimination is their lack of knowledge of key inheritance (that is, their inability to figure out the keys for the result of an arbitrary relational expression). Second, you might object, not unreasonably, that base tables in practice never do include duplicates, and my example therefore intuitively fails. True enough; but the trouble is, SQL can generate duplicates in query results. Indeed, different formulations of the same query can produce results with different degrees of duplication, as we've already seen, even if the input tables themselves have no duplicates at all. For example, consider the following formulations of the query "Get supplier numbers for suppliers who supply at least one part" on the usual suppliers-and-parts database: SELECT S.SNO | SELECT S.SNO FROM S | FROM S, SP WHERE S.SNO IN | WHERE S.SNO = SP.SNO ( SELECT SP.SNO FROM SP ) (Given our usual sample data values, what results do these two expressions produce?) So if you don't want to think of the tables in Figure 3-1 as base tables specifically, that's fine: just take them to be the output from previous queries, and the rest of the analysis goes through unchanged. Third, there's another at least psychological argument against duplicates that I think is quite persuasive (thanks to Jonathan Gennick for this one): if, in accordance with the n-dimensional perspective on relations introduced in the previous section, you think of a table as a plot of points in some n-dimensional space, then duplicate rows clearly don't add anything; they simply amount to plotting the same point twice. My last point is this. Suppose table T does permit duplicates. Then we can't tell the difference between "genuine" duplicates in T and duplicates that arise from errors in data entry on T! For example, what happens if the person responsible for data entry unintentionally that is, by mistake enters the very same row into T twice? (Easily done, by the way.) Is there a way to delete just the "second" row and not the "first"? Note that we presumably do want to delete that "second" row, since it shouldn't have been entered in the first place. |
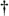 ] It must mean something, for if it means nothing, then why are the duplicates there in the first place? As I once heard Ted Codd say, "If something is true, saying it twice doesnt make it any more true."
] It must mean something, for if it means nothing, then why are the duplicates there in the first place? As I once heard Ted Codd say, "If something is true, saying it twice doesnt make it any more true."EAN: 2147483647
Pages: 127