Some Useful Programming Patterns
| Programming patterns include a number of immediately useful solutions, which we will now review one by one. What follows is a listing of popular patterns, with examples taken from typical game development scenarios. SingletonA singleton is a global object for which only one instance exists in the whole application. Most applications, and definitely all games, need global objects that must be visible from many different classes and scopes. A texture manager, the joystick controller object, and even the player class are all singletons. We need to have them visible at all times, and we only want to store one of these in memory. Traditionally, this has been solved in two ways, neither of which is especially elegant. The first one involves passing the said object as a parameter to all calls requiring access to it. This is inefficient, because an extra parameter must be pushed to the stack every time and makes code harder to read and follow. The second alternative is to define these objects in a source file and reference them using the extern mechanism. This way the compiler simply accepts that symbol, and the linker takes care of establishing the binding with the real object that resides in a different source file. This is a somewhat better technique, but as code size grows, our source files get cluttered with lots of extern definitions, degrading readability and elegance. Moreover, this solution is dangerous from a functional standpoint. As anyone familiar with OOP knows, code components need to have maximum cohesion and minimum bindings to other components. Cohesion means a class should encapsulate all functionality regarding a specific problem or data structure. Binding implies that a class should have little or no dependencies on other classes, so it becomes an independent and self-sufficient reusable component. This is rarely possible; many classes use other classes and so on. But externs generate lots of bindings, and in the end, your class diagram will begin to look like a spider web. Code will be impossible to separate from the rest of the application. Thus, the solution to the singleton problem is different from those explained earlier. It starts by declaring a class that has only one public method, which will be used to request an instance of the singleton. All instances actually point at the same structure, so this request call must create the singleton for the first call and just return pointers to it in subsequent calls. Thus, the constructor is a protected member, and all outside accesses to the class are done by the instance request call. Here is the code for a sample singleton: class Singleton { public: static Singleton* Instance(); protected: Singleton(); private: static Singleton* _instance; }; Singleton* Singleton::_instance = 0; Singleton* Singleton::Instance () { if (_instance == 0) { instance = new Singleton; } return _instance; } Any class requiring access to the singleton will just create one singleton variable (which will be different in each case). But all these variables will end up pointing at the same, unique object in memory. Check out the singleton class hierarchy in Figure 4.1. Figure 4.1. Class hierarchy for the singleton design pattern.
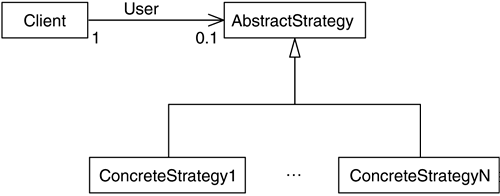
StrategySometimes you will need to create objects whose behavior can be changed dynamically. Take a soldier, for example. He might have an update routine that recalculates all his AI. Imagine that his AI can be one of four types: an AI routine to fight, one to escape, one to stay idle, and one to follow a trajectory with his squad mates. Now, it would be great from a simplicity and elegance standpoint to have a single recalc_AI function that could handle any of these strategies internally. A quick and dirty solution would be to store a state variable and use it to drive a switch construct that selects the proper routine according to the desired behavior. The code would be something like this: void recalc_AI() { switch (state) { case FIGHT: recalc_fight(); break; case ESCAPE: recalc_escape(); break; case IDLE: recalc_idle(); break; case PATROL: recalc_patrol(); break; } } But this is not very elegant, especially if there are a number of strategies to implement. Another solution is to subclass the object, so each one of the derived objects implements one of the algorithms. This solution is simply too complex in practical terms. Here is where the strategy pattern kicks in. Its goal is to separate the class definition from one (or several) of its member algorithms, so these algorithms can be interchanged at runtime. As a result, our soldier would have a single global algorithm (the recalc_AI call), which could be swapped dynamically in an elegant way. The implementation of the strategy pattern involves two classes. First, there is the strategy class, which provides the strategic algorithm. This is a pure abstract class, from which specific strategies are derived as subclasses. Second, there is the context class, which defines where the strategy should be applied and has a member that executes the selected strategy and swaps strategies when needed. Here is the source code for such a system. The soldier class dynamically changes strategies: class soldier { public: soldier(strategy *); void recalc_AI(); void change_strategy(strategy *); private: point pos; float yaw; strategy* _thestrategy; }; soldier::soldier(strategy *stra) { thestrategy=stra; } void soldier::recalc_AI() { thestrategy->recalcstrategy(pos,yaw); } void soldier::changestrategy(strategy *stra) { thestrategy=stra; } And here is the strategy class along with two derived classes: class strategy { public: virtual int recalc_strategy(point,float) = 0; protected: strategy(); }; class fightstrategy : public strategy { public: strategy(); virtual int recalcstrategy(point, float); }; class idlestrategy: public strategy { public: strategy(); virtual int recalcstrategy(point, float); }; Here is a usage example: soldier* soldier1= new soldier(new idlestrategy); soldier1.recalc_AI(); soldier1.changestrategy(new fightstrategy); soldier1.recalc_AI(); Notice how we have increased both the readability and performance of the system by following this DP. Interfaces are much simpler, and the switch/subclassing has been avoided. Figure 4.2 details what a class structure for this pattern might look like. Figure 4.2. Class hierarchy for a strategy design pattern.
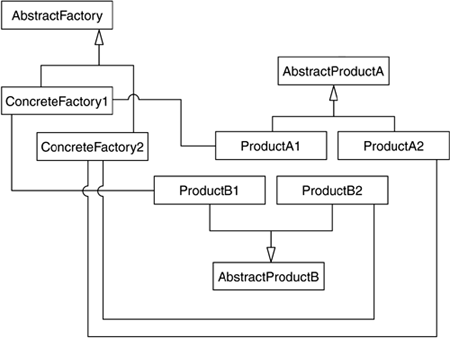
FactoryModern applications need to create and dispose of objects continually. Whether objects are text blocks in a word processor or enemies in a hack-and-slash game, a significant portion of your program is surely devoted to creating them on demand and destroying them at the end of their life cycle. As many programmers work on the same code and applications grow, this creation-destruction code spreads through many files, often causing problems due to inconsistencies in the protocol. The factory pattern centralizes the object creation and destruction, thus providing a universal, rock-solid method for handling objects. Factories usually come in two flavors: abstract and regular factories. Abstract factories are used whenever we need the product to be an abstract class, and hence we must derive specific products by means of inheritance. This is useful, because we only have a single call, which returns the abstract product. By creating product derivatives, our class can accommodate a variety of situations. Regular factories, on the other hand, need one method per type of product they want to build, because there is no inheritance. For the abstract factory type, the best example would be a central object creator for a game engine one object that centralizes the creation of texture maps, meshes, and so on. Here is the source code for such an example: class Product {}; class Texture : public Product {}; class Mesh : public Product {}; class Item : public Product {}; typedef int ProductId; #define TEXTURE 0 #define MESH 1 #define ITEM 2 class AbstractFactory { public: Product*Create(ProductId); }; Product* AbstractFactory::Create (ProductId id) { switch (id) { case TEXTURE return new Texture; break; case MESH return new Mesh; break; case ITEM return new Item; break; } } And a simple calling example would be AbstractFactory AF; Texture *t=AF.Create(TEXTURE); Now, here is a variant without using the abstract class. We somehow lose the elegance of the single create method but avoid using virtual classes: class Texture {}; class Mesh {}; class Item {}; class Factory { public: Texture *CreateTexture(); Mesh *CreateMesh(); Item *CreateItem(); }; Texture* Factory::CreateTexture () { return new texture; } Mesh* Factory::CreateMesh() { return new Mesh; } Item* Factory::CreateItem() { return new item; } In this case, an example using the factory would look something like this: Factory F; Texture *t=F.CreateTexture(); Figure 4.3 illustrates abstract and concrete factories and their products. Figure 4.3. Abstract and concrete factories and their products.
Spatial IndexAs games grow in complexity, the need for fast 3D tests increases as well. Gone are the days of simple objects with few triangles. Today we are processing several million triangles per second, and too often even the simplest test can become a bottleneck if applied to the complete data set. Thus, a spatial index is defined as a DP that allows the application programmer to perform queries on large 3D environments, such as game levels, efficiently. Some of the queries handled by a spatial index are
Using a naïve approach, we can easily derive algorithms with 0 (number of primitives) cost to solve the preceding problems. The spatial index, however, offers almost constant cost, meaning that tests like the previous ones require an amount of computation that is independent of the input data set. That is the main characteristic of a spatial index: It indexes space so that we can perform queries without examining the whole set. Spatial indexes can be implemented using different data structures, from the very simple to the very complex. Some solutions will be faster, often taking a higher memory toll in return. Depending on the specifics of your program, you will need to choose the implementation that best suits your needs. But from an API standpoint, a spatial index can be seen as a black box that speeds up geometric tests regardless of how it is implemented internally. Spatial Index as a ListThe simplest (and slowest) spatial index is a regular linked list. In order to compute any of the queries, we must scan the complete list, thus having 0 (number of elements) access time. But lists are a decent option in some circumstances. For example, a list could be an option in those applications that work with small (less than 20, for example) data sets. A classic example would be to store enemies in one game level (as long as there are not many enemies). In this case, more involved solutions simply do not pay off, because the performance will be more or less similar (see Figure 4.4). Figure 4.4. Traversal cost makes list-based spatial indexes suited only for small data sets.
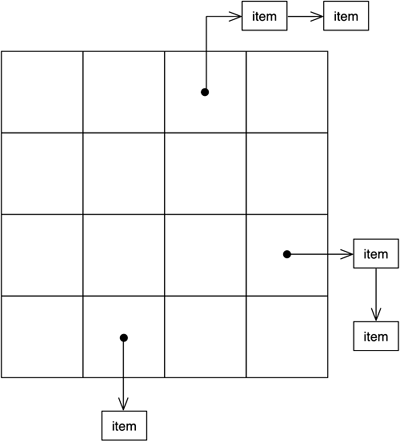
Spatial Index as a Regular GridThe second implementation of the spatial index pattern involves using a regular grid (explained in the previous chapter) that divides the space into buckets of the same size. Then, each bucket holds a linked list of the elements located there. Bucket size can be determined at load time to ensure a good balance between performance (the smaller the bucket, the better) and memory (the smaller the bucket, the higher the memory footprint). Take a look at Figure 4.5 for a visual representation of such a grid. Figure 4.5. A diagram showing the grid spatial index with lists of items in each cell.
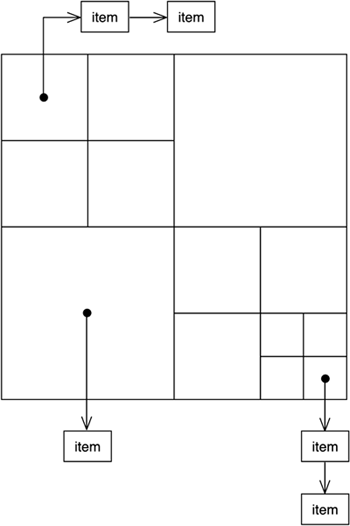
Spatial indexing with regular grids really makes a difference in all geometric tests: We only need to find out the position we will be scanning from (the location of the player, for example). Then, we transform that 3D position into cell coordinates and scan the associated list (and maybe those of the neighboring buckets). All in all, in dense scenarios, this can be orders of magnitude faster than using just a list. Imagine for example a spatial index that holds 1000 primitives (for example, trees), which are evenly spaced in a map that is 1x1 Km. We can store them in a regular grid 100 meters in size. We will thus create a 10x10 grid. To test for a collision with one of the primitives, we will just convert the player position into cell position (this can be easily done using integer divides). Then, once the cell is located, we simply scan the list of that cell and the nine neighboring cells to make sure we haven't hit anyone. Because there are 1000 primitives and 100 buckets, we can assume each bucket holds a 10-element list on average. Thus, scanning 10 buckets (the one we are standing in and the nine neighbors) involves 100 tests in a worst-case scenario. Now compare that to the 1000 tests we would need if we weren't using the spatial index. Even better, the index can be adjusted. Now imagine that we have refined our scale, and each bucket is now 50 meters across. We would have a 20x20 grid, for a grand total of 400 buckets. In this case, each bucket would hold 2.5 primitives on average, and the collision test would just need 25 tests in total. Obviously, there is a downside to all this magic. This new version takes up four times more memory than the previous version. The more important downside to all this is that many cells will be useless. The structure is regular, and thus it does not adapt well to the irregularities in the distribution. Spatial Index as a Quadtree/OctreeSpatial indexes can also be implemented using quadtrees (or octrees if you need to handle real 3D data). In this case, we would split the quadtree until the current node is not holding data beyond a fixed threshold. We can say, for example, that no leaf node should have more than 10 items, and propagate the subdivision of the tree until we reach that goal. The construction of the data structure is adaptive at the core, adjusting to the layout of the data. Then, for the specific tests, we would traverse the tree using the distance criteria to prune as we advance. For example, here is the pseudocode for a collision detection test with a threshold distance of five meters. I assume the node data structure has four pointers to the four descendant nodes, labeled respectively topleft, topright, bottomleft, and bottomright: checkcollision (point p) if (topleft node is not empty) if (closest point from topleft node is closer than 5 meters to p) checkcollision in that node if (topright node is not empty) if (closest point from topright node is closer than 5 meters to p) checkcollision in that node if (bottomleft node is not empty) if (closest point from bottomleft node is closer than 5 meters to p) checkcollision in that node if (bottomright node is not empty) if (closest point from bottomright node is closer than 5 meters to p) checkcollision in that node if (all child nodes are empty) // we are in a leaf scan the list of objects corresponding to this leaf Quadtrees (depicted in Figure 4.6) will usually be slower than grids, because they need to traverse the data structure more thoroughly. On the other hand, memory use is much lower, making them an interesting choice under some circumstances. Keep in mind, however, that quadtrees built this way are not very suitable for dynamic geometry. If we are storing moving objects, they might change the quadtree cell they are stored in, and rebuilding a quadtree on the fly to accommodate this kind of change is not trivial. We need to remove the object that has left the node, or maybe collapse that node completely, and finally insert it in its new location (maybe resplitting as we do so). Figure 4.6. Quadtrees/octrees provide better memory management than grids at higher coding complexity.
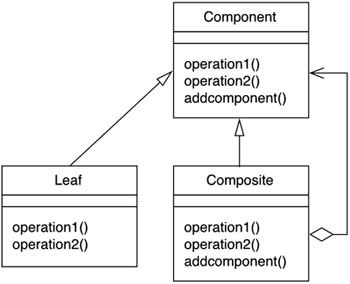
CompositeMany types of applications, and games in particular, need to hold heterogeneous collections of data together for different reasons. A game level can have sublevels (which in turn can have sublevels), potions, enemies (which can be composed, for example, as in a horse and rider approach), objects, and so on. The overall data structure can be best described as a part-whole hierarchy with each element being either a primitive or a composite, quite likely of different types. Having all data in a single structure makes traversal more intuitive, especially when we couple the composite with a spatial index that allows local queries such as "Which potions are in this room?" Thus, it would be great if programming languages offered some constructs that made the implementation of these complex collections easier. But most programming languages only support homogeneous arrays, so a higher-abstraction solution is needed. This is what the composite DP is all about: creating part-whole heterogeneous hierarchies where we can access primitives and composite objects using a standard interface. This way a single interface will make traversal easier, and each object will retain its specific features and internal structure. In terms of implementation, the best way to represent a composite is to write a list of elements. The element class will be defined as pure virtual, which means we cannot create objects of this class directly, but need to derive other classes through inheritance. These derived classes will inherit all the attributes and methods of the pure virtual class but will also use extra attributes to encode class-specific information. As an example, let's take a look at the source code required to implement the level-wide data structure we mentioned earlier: a structure that can hold sublevels, each one with potions and objects. The class Level represents the whole level, and then we use the class LevelItem to describe primitive entities inside that level: potions, objects the user can grab, and so on. class Level { public: virtual ~Level(); const char* Name() { return _name; } virtual float LifePoints(); virtual int NumEnemies(); virtual void Add(LevelItem*); virtual void Remove(LevelItem*); virtual Iterator<LevelItem*>* CreateIterator(); protected: LevelItem(const char*); private: const char* _name; }; class Potion: public LevelItem { public: Potion(const char*); virtual ~Potion (); virtual float LifePoints(); }; class CompositeItem : public LevelItem { public: virtual ~CompositeItem(); virtual float LifePoints(); virtual int NumEnemies(); virtual void Add(LevelItem*); virtual void Remove(LevelItem*); virtual Iterator<LevelItem*>* CreateIterator(); protected: CompositeItem(const char*); private: List<LevelItem*> _items; }; float CompositeItem::LifePoints() { Iterator<LevelItem*>* i = CreateIterator(); float total = 0; for (i->First(); !i->IsDone(); i->Next()) { total += i->CurrentItem()->LifePoints(); } delete i; return total; } int CompositeItem::NumEnemies() { Iterator<LevelItem*>* i = CreateIterator(); int total = 0; for (i->First(); !i->IsDone(); i->Next()) { total += i->CurrentItem()->NumEnemies(); } delete i; return total; } class Enemy : public CompositeItem{ public: Enemy(const char*); virtual ~Enemy(); virtual float LifePoints(); virtual int NumEnemies(); }; class SubLevel: public CompositeItem{ public: SubLevel(const char*); virtual ~SubLevel(); virtual float LifePoints(); virtual int NumEnemies(); }; void LordOfTheRings () { Level* MiddleEarth=new Level("Middle Earth"); SubLevel* TheShire= new SubLevel("TheShire"); SubLevel* Moria= new SubLevel("Mines of Moria"); MiddleEarth->Add(TheShire); MiddleEarth->Add(Moria); Enemy *Nazgul=new Enemy("Nazgul"); Enemy *NazgulRider=new Enemy("NazgulRider"); Enemy *NazgulSteed=new Enemy("NazgulSteed"); Nazgul->Add(NazgulRider); Nazgul->Add(NazgulSteed); TheShire->Add(Nazgul); Enemy *Balrog=new Enemy("Balrog"); Moria->Add(Balrog); Potion *Lembas=new Potion("Lembas"); TheShire->Add(Lembas); cout << "The number of monsters in Middle Earth is " << MiddleEarth->NumEnemies() << endl; cout << "The life points for the monsters are " << MiddleEarth- >LifePoints() << endl; } The preceding code creates a hierarchy based on The Lord of the Rings. As a result, we create two sublevels (Moria and The Shire) and then a host of creatures and potions in each zone, showing how composites can handle nonhomogeneous data structures. Figure 4.7 complements this code with a drawing of the composite pattern data structure. Figure 4.7. The composite design pattern.
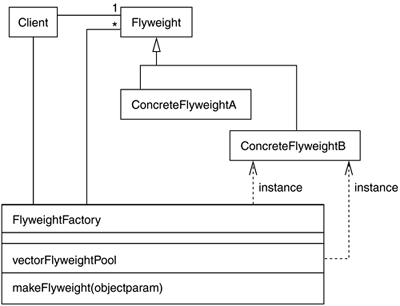
FlyweightThe last pattern we will review is the flyweight, which is extremely useful when we need to have large collections of objects that are fundamentally the same except for a few parameters. In this case, we do not want to overpopulate our memory with lots of objects that are mostly identical, but instead we want to use system resources efficiently while keeping a uniform access interface. A simple and very game-oriented example is the units in a real-time strategy game. All infantry soldiers are virtually the same except for two parameters: the position and the life level. But the AI routines, graphics handling code, texture and geometry data, and most other parameters like movement speed and weapons are the same regardless of the instance you examine. Then, the flyweight pattern suggests dividing the object into two separate classes. First, we need to create the actual flyweight, which is the core object and is shared among all instances. Flyweights are managed through a FlyweightFactory that creates and stores them in a memory pool. The flyweight contains all the intrinsic elements of the object; that is, all information that is independent of the object's context and is thus sharable. Second, we will need external objects that will use the flyweights, passing the extrinsic (thus, state dependent) information as a parameter. These concrete objects contain state information, such as the position and life level of our strategy game soldiers. Let's take a look at how we would code such an example using the flyweight DP: class InfantrySoldier: public AbstractFlyweight { float speed; float turnspeed; (...) public: void Paint(ExtrinsicSoldierInfo *); void RecalcAI(ExtrinsicSoldierInfo *); }; class InfantrySoldierInstance { ExtrinsicSoldierInfo info; public: void Paint(); void RecalcAI(); }; void InfantrySoldierInstance::Paint() { FlyweightFactory *FF=new FlyweightFactory; InfantrySoldier *IS=FF->GetFlyweight(INFANTRY_SOLDIER); IS->Paint(info); } void InfantrySoldierInstance::RecalcAI() { FlyweightFactory *FF=new FlyweightFactory; InfantrySoldier *IS=FF->GetFlyweight(INFANTRY_SOLDIER); IS->Recalc(info); } Notice how the InfantrySoldierInstance class is lightened as all the stateless soldier data structures and algorithms are moved to the InfantrySoldier class. All we would need to add would be a FlyweightFactory object, which would be an object factory and a singleton. The FlyweightFactory class has a method that retrieves a flyweight, passing the name of the flyweight (a symbolic constant) as a parameter. Notice how the returned flyweight will not be created on a case-by-case basis, but reused over many calls by using the following source code: class FlyweightFactory { AbstractFlyweight *flyweight; int NumFlyweights; public: AbstractFlyweight * GetFlyWeight(int); }; AbstractFlyweight *FlyweightFactory::GetFlyWeight(int key) { if (flyweight[key] exists) return flyweight[key]; flyweight[key]=new flyweight; return flyweight[key]; } Thus, we can keep all our infantry soldiers in memory by translating most of their behavior to the flyweight and externalizing all state-dependent functionality to a higher class abstraction level. Flyweights are pictured in Figure 4.8. Figure 4.8. Class hierarchy for the flyweight design pattern.
|

EAN: N/A
Pages: 261