4.1 Comparison of principles
|
| < Day Day Up > |
|
In this section, four fundamental areas are discussed, and the implementation of each in the PDM and SCM domains, respectively, is compared.
4.1.1 System architecture
The system architecture describes the way a system is built up, its infrastructure, and ways it can be integrated with other systems. Most PDM and SCM tools use a client-server architecture, the server containing the database in which all data is stored. This data is stored following a certain data representation implementing a storage data model. To provide effective support to distributed development, many servers are needed. The architecture also includes the strategy for server use (what data is stored in which server), the client-server and server-server communication, and ways that servers are kept synchronized.
4.1.1.1 Data representation
Ways that data is stored and represented in PDM tools is fundamentally different than in SCM tools. As described in Section 2.3.1, PDM tools focus on managing product data stored in business items. This data, relating to the product, is designated metadata. The actual data (e.g., drawings produced in CAD tools) are stored in files and referred to as data items. A business item is thus an entity in a database, described by metadata, while a data item is the actual file. Most PDM tools use an object-oriented data model, in which a hierarchy of different types of business items can be created with references to related data items. Many PDM tools also use an objectoriented relational database in which to store the business items (often called the PDM database), while the data items are stored separately in file servers.
Separating the business items and data items makes it easier for a PDM system to manage heterogeneous data (i.e., different file types and objects). Very large amounts of data can be stored and managed in a PDM system. When distributing (replicating) the data in order to make it more available in a distributed setting, only the business items are replicated. See Section 4.1.1.2 for details. Data is represented in SCM by what is more or less a file system with directories and files. The two different types of files, source (plain ASCII files) or binaries (executables), are usually treated differently. For source files SCM provides additional support, such as showing differences between different file versions or enabling interactive merging of two file versions. In general, all kinds of file types and objects represented as a file or directory may be managed and stored in the SCM tool. Metadata for a file is stored together with the file itself and not in a separate database. SCM systems usually manage large amounts of data.
The difference in data representation reflects the different histories of SCM and PDM. SCM mainly manages source files, which, together with directories, are their primary data model. It is possible to store, compare, and merge this data within the SCM tool. The need to manage metadata was only realized subsequently and was then implemented as an add on, using attributes. Moreover, in most cases, the user interface for managing attributes is rudimentary and is rarely used by developers (end users).
For PDM, the reverse is the case. The metadata is considered the most important. This data is stored in a well-defined (user-defined) data model that can be searched through and accessed through different views. The data items themselves, however, are treated as atomic objects, often stored by some other tool and only referred to from the business items.
There is, however, a tendency for SCM tools to also use a separate database for storing the metadata, thereby reducing this difference between PDM and SCM.
4.1.1.2 Data replication
Both PDM and SCM support distributed development by enabling replication of data (i.e., the storage of the same data on many servers where it is automatically kept synchronized and consistent)—see Sections 2.4.3 and 3.2.7. There are, however, differences. As illustrated in Figure 4.1, a typical PDM tool has a master server (often called a corporate server). This server contains common information such as access rights for all the other servers and the locations of the other servers in the network. The replication architecture can be likened to a constellation with the master server at the center. SCM tools usually have no such master server. Instead, servers replicate data between two nodes, using a peer-topeer protocol. Thus, any structure of servers can be built by connecting servers to each other. An example with four servers is depicted in Figure 4.2.
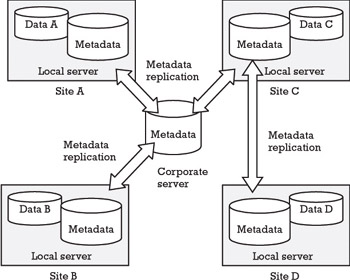
Figure 4.1: Server replication in a typical PDM tool.
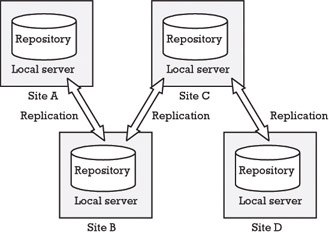
Figure 4.2: Server replication in a typical SCM tool.
In PDM tools, it is often possible to decide that either both the business items and the data items or only the business items should be replicated. It is most usual to replicate only the business items (the metadata), leaving all data items unreplicated, stored at their respective servers (one data item existing in one server only). In Figure 4.1, a typical example of replication of business items between four different sites is shown. At sites A, B, C, and D, the data items are stored in their respective local data repository (e.g., on a file server), here denoted Data A, Data B, etc. The business items are replicated to all servers. When a user requests a specific data item, the PDM system first searches for its business item, which, because it is replicated, can always be found on the local metadata server. The business item has a reference to the data item, pointing out the server in which the item is stored and from which it can then be requested. The local server will present the information for the user. Assuming that a user has access permission, he or she can update (check out and check in) a file and change the file itself and its metadata, irrespective of where in the network the file is located. A distributed locking mechanism controlled by the master server prevents the checking out of a file by two users at the same time. When a local server wishes to lock an item, a lock flag is sent to the master. If the item is not already locked, the server receives the lock flag and can begin modification of the item. To set a lock flag, it is thus necessary to reach the master server but not to reach all the other local servers.
In most SCM tools, the replication functionality was implemented as an add-on feature long after the standard systems were developed, and it is not possible for the SCM tool to manage metadata and files separately. The user can decide which data (typically, which files) should be replicated. Both these files and their metadata are then replicated. As stated earlier, the replication is performed between pairs of servers. Figure 4.2 depicts an example of how four servers can be connected and data are replicated by connecting the servers two by two. It is only possible to access data stored at the local server. A global lock is seldom used to avoid multiple updates. Instead most SCM tools implement replication using site ownership of the branches, as described in Section 3.2.7. This means that only one site is allowed to create new versions on a specific branch (the owner of that branch). Versions on a branch not owned by a site are read-only and cannot be updated (check out and check in) without requesting and obtaining transfer of the ownership to that site.
4.1.1.3 Application integration
A PDM system is usually integrated with various applications and builds an information infrastructure in which data from applications is gathered and exchanged. Integrations range from the simple, where the appropriate application is launched when a file is viewed, to the tighter, where the PDM system retrieves information from the applications, either through APIs or by direct access to application repositories.
The role of an SCM tool in a complete environment is somewhat different. It can be used as a stand-alone tool, or as a set of tools, and also as a set of functions offered for use by other tools. SCM tools are often designed to provide other applications with information and data (e.g., a file is checked out and sent to a compiler to be compiled). Many SCM tools are integrated in other tools. Typical examples are IDE. For this reason, many SCM tools include APIs with basic SCM functions (check in, check out, and baseline), which make them easy to encapsulate in other tools. It is also interesting to mention that many different tools incorporate certain basic SCM functions as their integral part and not as a part of an SCM tool. For example, Microsoft Word contains rudimentary version management.
The data format used for the exchange of data is also different. PDM has standards defining transfer protocols to enable the exchange of data with different formats. SCM uses plain files only.
The historical difference in the way integration with other applications is performed affects the possibility of integrating a PDM tool with an SCM tool. While PDM tools are often the central process that initiates activities in other tools, SCM tools are more passive, offering an API. Their complementary behavior makes their integration is easier (PDM encapsulating an SCM tool), but is not sufficient. To obtain a seamless and user-friendly integration, the entire processes must be integrated and the redundancy in functions must be avoided. For example, both PDM and SCM provide support for version management, but they are quite different (see Section 4.2.1).
4.1.2 Product model
A product model is an information model used to describe the structure (building blocks such as parts) and behavior (e.g., outputs, effects, and properties) of a product managed by the system. The extensive support for product model management in PDM and its absence from in SCM is perhaps the largest technical difference between PDM and SCM systems.
A PDM system has an explicit product model. The basic principle of product modeling in PDM is the composition relationship, which is used to form tree structures (often referred to as product structures), as described in Section 2.2.3. The product structure is not hidden in the system, but presented and edited by the user.
On the other hand, in SCM, product modeling is very weak. Even though creating a product structure is part of the identification activity in CM (see Section 3.3.1), SCM tools do not manage a product model. The differences in approach come from fundamental differences in the nature of hardware products and software products. For hardware, the product has a physical existence and consists of physical parts. For that reason the product structure can be represented by a part structure. In the software PLC, the software is transformed through different structures. The software architecture developed during the design phase determines the structure of the software system, which comprises software components, the externally visible properties of those components, and the relationships between them. The development structure used during the implementation phase includes source code and documentation related to it. It is natural that the software architecture and the development structure are similar, but in practice they are different as a result of two factors. First, the development process itself: the isolation and coordination of development activities requires a structure different from the software architecture. Second, many of the development tools used require specific structures. As a consequence, in the implementation phase, developers use a separate development structure adjusted to the development process. A completely different structure is that of the software product delivery package. It includes binary and user-documentation files and is adjusted to be most convenient for the delivery. Note also that different structures can be defined for different delivery media. This structure is derived from the development structure by a build and release activity. Moreover, we have a structure on the target system, when the software is installed. In many software systems, we recognize two different target system structures—an installation or deployment structure in which the software is saved on a medium (for example, a disk), ready to run, and a run-time structure in which the software is executed (the primary memory). Finally, we must remember that all of these structures are not physical, but virtual. The difference is very important, as they can be changed very easily. Indeed, completely different structures may be used in different versions of the same product. Because SCM tools are focused on the development phase, they usually have certain support for managing developing structures.
Different building blocks are used when creating (defining) the product model. The types of these blocks are defined in the data model, which describes not only the types of objects, but also object attributes and the relationships between objects. This data model may be changed in a PDM system to more exactly suit the particular company business model. A set of industry-specific data models is included in the STEP standard [2]. The purpose of STEP is to facilitate data transfer between various information systems within and between companies. It is a comprehensive standard, and its contents include descriptions of geometry and product structures. Several PDM systems support data transfer based on this standard, and some even have a data model based on this standard.
Only a few SCM systems include a customizable data model. Most SCM systems structure information by using the file and directory structure used in the operating system. SCM has no standard such as STEP.
4.1.3 Evolution model
The evolution model manages changes during the PLC and is related to version management.
PDM distinguishes three different concepts of versioning: historical versioning, logical versioning, and domain versioning. Historical versioning is conceptual and similar to SCM versioning, dealing with revisions/versions of a product. However, it is not possible to branch and merge. Logical versioning manages versions of parts as alternatives, possible substitutes, or options. Finally, domain versioning is not actually versioning but a presentation of further views of the product structure (e.g., as planned, as designed, and as manufactured) used by different actors during different phases in the PLC. These views are fundamental in PDM tools.
The emphasis on historical versioning in SCM, which is more advanced than PDM, arises from the differences in the natures of the products: software may be changed more easily than hardware. Thus, SCM must manage versioning in a more sophisticated way than CM for hardware [3]. Versioning in an SCM tool almost always includes the possibility of creating and merging branches. It is also easy to present the differences between two versions because the source code is usually stored in text format. There is no logical versioning in SCM. Variants are managed—but often using branches or conditional compilation—and are not clearly visualized using the product structure. The concept of view exists in many SCM tools and is related to the possibility of creating configurations by the selection of consistent versions of the files included in a specific configuration. This is used both to create private workspaces and to build the product.
4.1.4 Process model
The process models for SCM and PDM are conceptually similar. A process is described by a set of states and rules for passing from one state to another. These states and rules can be specified by state transition diagrams (STDs). An STD describes the legal succession of states (and optionally which actions produce the transition) for a product type, and thus describes the legal way for entities of that type to evolve. The alternative way to model processes is so-called activity-centered modeling, in which the activity plays the central role, and the models express the data and control flow between activities.
PDM systems have two process-related concepts: object states and workflow. The object state defines the life cycle of an object (e.g., preliminary, approved, and frozen). Workflows are based on a description of the process, its activities, their sequence, and the relationships between them. A workflow can be used to control data management activities within or between processes and is therefore an activity-centered model.
As SCM is intended to control software product evolution, it is not surprising that many process models are based on STDs. As [4] concludes, experience shows that complex and fine-grained process models can be defined that way. Unfortunately, experience also shows that STDs do not provide a global view of a process, and that large processes are difficult to define using only STDs. The activity-based model is not used to the same extent as in PDM, but some SCM tools provide process support similar to the workflow in PDM. Most SCM tools provide triggers to implement a process. These triggers, activated on certain occasions such as check in, can be used to activate scripts implementing a workflow, running tests, or for sending notifications to other developers.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 122
- Using SQL Data Manipulation Language (DML) to Insert and Manipulate Data Within SQL Tables
- Using Data Control Language (DCL) to Setup Database Security
- Using Keys and Constraints to Maintain Database Integrity
- Retrieving and Manipulating Data Through Cursors
- Monitoring and Enhancing MS-SQL Server Performance