System Development
|
| < Day Day Up > |
|
Poorly designed software and hardware components cost companies and users millions of dollars every year. Although it's difficult to produce systems without bugs, and people will always try to utilize software/hardware in ways that the designers never dreamed of, managed methods of development exist that can minimize the inherent bugginess of the systems we rely on. This results in more flexible, secure, and functional applications and devices.
Thoughtful planning, careful selection of team members, orderly division of responsibilities, extensive documentation, and adherence to standards are the ingredients for successful system development. Whatever the reason-user demand, new technology, or the endless drive to stay competitive-organizations will continue to seek ways to develop better, more secure technology. This section aims to explain the processes, security controls, and standards that pertain to the system development process.
System Development Life Cycle (SDLC)
The System Development Life Cycle (SDLC) is a structured, multitiered approach to developing, implementing, and maintaining Computer Information Systems (CISes). It functions as a road map for the teams of software engineers, system analysts, and other individuals involved in the research and development of new systems or those under modification. Rather than being governed by standards, the SDLC method can be customized to fit the needs of an organization. Its goal is to break down the different steps of development and then divide those steps into smaller tasks that are completed along the way.
The SDLC promotes an ordered flow of progress as the accomplishments of one step in the process are applied to the subsequent steps. For this reason, the terms waterfall and ladder are used when describing SDLC methodology. However, the basic waterfall approach assumes that each step is completed correctly along the way. This is just like a real waterfall where the water only gets one chance to fall. This inherent weakness of so-called linear progress has been corrected by the fountain approach to systems development, where amendments to the underlying SDLC architecture allow for steps to be reiterated. In other words, certain developmental phases can be cycled through repeatedly until the collective achievements suggest that the step in question is complete and the team can move on to the next step with confidence.
| Note | SDLC promotes broad documentation during all phases. |
The successful execution of the SDLC process is dependent upon the people who manage its implementation as well as the people who complete each specific task. It's about teamwork. The right people need to be selected for the right jobs. The process will also move along more efficiently if individual team members can see that their work is actually advancing the project. One aspect of SDLC that helps with morale issues, as well as overall performance, is its extensive use of documentation. The initial goals and outlines, as well as the progress along the way, should be documented as fully as possible.
The security concerns related to the SDLC must be addressed continually throughout the process. Concerns include separation of duties, protection of programming code in production, and certification/accreditation procedures.
Although the steps in the SDLC process can vary greatly, they generally follow an outline that includes the steps shown in Figure 7.3.
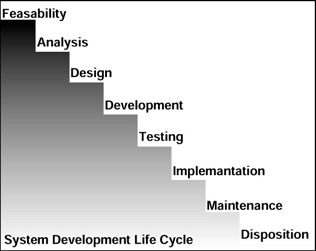
Figure 7.3: Steps of the SDLC process.
Feasibility
Once the possible need for the project has been identified, this first step aims to answer the initial questions one might expect to hear, such as, What will the project cost? Does the project pose any security threats? Is it legally and economically feasible? What are the risks? Will it have the support and sponsorship of those higher in command? Who will the team be comprised of? These questions and more are answered and then documented. The results of the feasibility phase are used to determine whether or not the project will get the green light.
Analysis
If the go-ahead is given, the analysis phase is set into motion. It aims to define and document further, such as security concerns, user requirements, and system performance. During this phase, alternatives such as purchasing an existing software package (as opposed to creating a new one) are evaluated. Decisions regarding outsourcing some of the workload are made at this step as well. After these concerns are evaluated and documented, the results are proposed to the organizational managers, who might choose to develop a product from scratch, purchase and modify an existing application, or scrap the project altogether.
Design
During the design phase, the system is reviewed and designed to meet the requirements laid out by the analysis phase. Plans are developed to convert existing data to the new system. Decisions are made regarding which operating environment to use, system architecture, and input/output. As stated before, the steps in the SDLC can be repeated as necessary. However, in the design phase, concrete decisions need to be made that usually prohibit a return to the analysis phase. It marks a firm commitment and a real investment in the project. This is not to say that a project has never passed the design phase only to be scrapped later; it just gets expensive at this point. This phase is crucial and proper documentation is key in the success of the design phase as well as system development as a whole.
Development
In the development phase, the results of the design phase are transformed into a comprehensive information system. This phase primarily focuses on the applications that drive the system but it also deals with the hardware and communications requirements of the project. Hardware related to the system will be assembled and hardened. User manuals and other documentation begin to take shape at this stage. System Security Plans (SSPs) and Contingency Plans (CPs) are also developed here. Other operational requirements are worked out, such as future training techniques for the new system. In addition to documentation and other security-related concerns, the development phase mainly aims to get everything in line for the next phase: testing the system.
Testing
In accordance with the SDLC policy of extensive documentation, developers don't enter the testing phase until a clear test plan has been written. The plan usually outlines the desired results of testing and defines the time constraints placed upon the phase. Once the modular software components that comprise a system are ready for a trial run, they are tested both individually, and then as a whole.
The interdependencies between software modules are tested to see if they will actually assimilate as planned. The operating system (OS)-specific questions are answered, such as, Will the system run on the platform it was designed for? It is during the testing phase that a beta version will be released to a controlled group in order to collect reports about strong points, weaknesses and bugs. User participation in this phase is referred to as acceptance testing. It is often difficult for developers to step outside themselves and give objective feedback from a user's point of view, so this aspect of testing is highly valued. Questions regarding the application's performance are answered at this point. This phase also tests the security related areas of the project, such as access control and data security. A project might see many reiterations of this phase before entering implementation, where things really start to come together.
Implementation
This phase is entered once the system testing is complete and the user acceptance has been established. It is during implementation that the system modules are translated into programming code and integrated with any hardware components that the system specifies. Exhaustive code reviews in this phase attempt to weed out previously undiscovered bugs and security concerns. Data conversion takes place to update the format of information or files to meet current system requirements. The system will then be put onto a production machine and evaluated.
Any certification or accreditation requirements are addressed and developers ensure that the system meets any regulations or legal guidelines that were imposed on the project. Standards are addressed and the training plans defined in the development phase are carried out. This phase leads to final production of the system, so it will not be labeled complete until it is functioning properly in a production environment.
Maintenance
Because the maintenance (or operational) phase will continue throughout the life of the system, a substantial portion of project funding-sometimes more than half-is reserved for system maintenance. Although maintenance is the phase that never ends, it is what keeps developers happily employed for years. Once users rely on an application, they will have an ongoing need for updates, upgrades, and product support. Over time, new users will be introduced to the system, so the need for training will never go away.
An application will also have to adapt to newer, faster hardware. Improvements will be made and features will be added. As a result of standard security audits carried out in this phase, security leaks could surface, requiring patches to be written and distributed in a timely fashion. Bugs will be discovered by users and the maintenance team alike and will need to be fixed. Another application or a new networking requirement could be thrown into the mix and the system might need adjustments to make it play nice with these components. People will want new functionality or add-ons. An application might need to be ported to an operating system for which compatibility was not originally planned.
A team must also coordinate its efforts to document the many modifications that are made and publish new manuals for each version of the application. If a new requirement is identified that entails major modifications of the system, the whole project might indeed revert to the beginning phase.
As you can see, this is quite a bit of work. A large portion of the maintenance process is the continual evaluation of a system to make sure it is meeting the needs originally defined in the early phases, or meeting the redefined needs of a system that's been overhauled. It is an expensive, unending quality-control undertaking. If you have been computing for some time, just think back to an early version of an application that you have relied on for years. Recall updates to your favorite programs that provided accessibility to the many new features that have come about in networking, cryptography, multimedia, hardware, and operating systems. If you have been affected by these advancements, you've witnessed the maintenance phase of the system development life cycle at work.
Disposition
The disposition (or disposal) phase is initiated to either phase out a portion of a system, or to terminate it completely and end the development life cycle. Once a system is deemed to be obsolete, the first step in this process is to prepare a disposition plan. This plan outlines an orderly fashion in which the disposition tasks are to be performed. The plan also addresses who is responsible for each task as well as any time constraints for completing the phase.
One of the most important steps of the disposition phase is data archival. For several reasons, some materials created throughout the life cycle process must be preserved and/or transferred. These materials include data, software components, documentation, and any cryptographic keys associated with the storage of encrypted data.
Life cycle documentation is sometimes referred to as deliverables. The main reason for data archival is to facilitate a resurrection of the project if another organization were to bring the system back to life. Depending on the nature of the project, there might also be local, state, or federal policies that need to be observed concerning the preservation of related electronic records.
On the other hand, some materials will need to be destroyed, or disposed of. Again, what's saved and what's destroyed depends on the system in question. Software, data, or equipment might be among the casualties of the disposition phase. Hard drives or other media involved in the life cycle might need to be erased. Key words related to the erasure process include degauss, zeroize, sanitize, and overwrite.
It was a good system that had a long life but now it's time to say goodbye. The last step of this, the final phase of the SDLC, is the preparation of a Post-Termination Review Report-a sort of eulogy, if you will. This document details all the activities of the disposition phase, what was learned in the process, where the data, software, and equipment may be found, and who to contact to locate the archives. Finally, a short time (usually six months) after the end of this phase, a phase-end evaluation takes place to review the disposition process and make sure everything went according to plan.
Separation of Duties
Separation of duties breaks up the tasks in the development process to ensure that one person does not have too much control over any specific area of development. For example, a programmer will hand off finished code once it is developed. Another team member will then be responsible for implementing it into a production environment. A related process, aptly termed accountability, provides a means of connecting individuals with their actions. If there is a collapse of a control in the system, or a security violation occurs, accountability measures ensure that the right person is held responsible.
Certification and Accreditation
This is the bureaucracy of systems development. Here, we have a pair of terms whose subject matter depends on the system being certified and accredited. The terms of the certification/accreditation process are dictated by whichever governing body has set the standards that are applicable. These procedures are carried out during the implementation phase of the SDLC.
Certification
The first half of this duo is mostly concerned with evaluation. Usually carried out by an unbiased outside source, the certification process compares systems with a predefined set of security standards in search of violations. The security features of a system are analyzed to ensure they meet any requirements or laws. It's during this process that the comprehensive documentation created during the SDLC is invaluable. Certification is essentially the first step in accreditation.
Accreditation
The second half of this procedure is where to find the payoff. Also called an approval to operate, accreditation gives an organization the permission to put a system into production. Upon accreditation, a system's security features are deemed to be adequate and are formally accepted. Accreditation is usually restricted to a defined period of time, upon which the process must be repeated. Accreditation is also associated with an acceptance by management of any risks involved with operating the system.
Program Languages and Execution
A few terms regarding programming languages and how they are processed need to be clarified. Like English, French or Spanish, each different programming language has its own vocabulary and specific rules regarding grammar (or syntax). Let's take a look at the basic categories of languages and how computers read them.
Types of Languages
Here, we'll consider the following types of languages:
-
Machine language: Also called machine code or instruction code. This is the form of binary code that a computer can process directly with the help of built-in instruction sets. In the beginning, this is how all programs were written. Machine code looks something like this: 1101 0101. Because every kind of computer only understood its own brand of machine code, and writing programs with 1's and 0's produced many errors and took for-ever, it became necessary to find another way to program.
-
Assembly language: Developed to fix the problems of programming in machine code, assembly language makes things easier by using symbols that represent binary instructions. For a computer to process it, assembly code must be converted into machine code, which is done by an assembler. Although it simplifies programming a little bit, writing in assembly language is still tedious and prone to typographical errors.
-
High-level languages: To enable the efficient production of computer programs, many high-level languages have been developed that are easier for people to write with. Along with special characters and formulas, this method also makes use of simple English and mathematic terminology, resulting in the most popular and productive way to program. High-level languages decrease the amount of code a programmer must write. Java and C++ are high-level languages. These languages are also portable, which means that one does not have to write programs for any particular type of computer architecture. High-level code must also be converted into machine code before a computer can use it, and in the next section we will talk about how this is accomplished.
Note Binary machine code is the most raw of any type of programming code and all others must be translated into this format.
Interpretation and Compilation
At the core of a computer, the only language that is understood is machine language. High-level programs must be translated by interpretation or compilation for a computer to execute their commands. These two processes have distinct differences that are explained next.
Interpretation
As you might have guessed, a component called an interpreter handles interpretation. Commands are interpreted one line at a time, which is a little slower than other methods. Interpreters can determine the exact line number in the code where an error exists, which is a trick that compiled programs can't do. Java is interpreted. You might recall viewing a Web page that reported a specific line of code that contained an error in its Java script. Interpretation enables this handy method of detecting bugs.
Compilation
Yes, high-level programs are indeed compiled by a compiler. A compiler takes high-level source code and converts it to executable code in one fell swoop. This produces quick-running, OS-specific executable files such as a Windows .exe program. C++ is compiled. Compilers check for errors during translation but because they can't spot every kind of error, debugging can be more difficult. Also, compiled code runs the risk of having malicious code embedded within it. This is hazardous because it can be hard for a programmer to find such dangerous code among a mass of innocent code.
Security Controls
This area of applications development covers the combined concepts, principles, and controls that address the key facets of security throughout the process of systems development and beyond. These controls cover the operating systems, networks, storage methods, applications, and equipment involved in development. Focusing on the security of every aspect of system design, development, and operation, security controls establish common objectives to ensure that the confidentiality, integrity, and availability of the system are upheld to the fullest.
There are numerous tools, standards, and practices that fit into this catch-all category of security-related systems development and application environment controls. We won't expound on every possible scenario that exists in the real world. Therefore, with the objective of Security+ certification in mind, and in unison with the goals of this book, Chapter 7 will conclude with the elements of this group that are most likely to be seen on the exam.
Application environments are divided into domains, which are simply groups of objects. Subjects, such as users or processes in an application, request access to objects. Objects are defined by classifications and sets of rules governing what subjects may do with them, called permissions, must be set. In a system, a central component called the kernel manages requests for resources. The relationships between object access and subject permissions, and the processes that enable the necessary communications, create security concerns. In the following sections, we'll discuss the tools that ease these concerns, as well as some standards that you should be aware of.
| Note | The kernel is the top-level, authoritative component that controls requests for resources in an application environment. |
Process Isolation
Process isolation is where a unique memory address is assigned to each active application. This is done to isolate the processes of individual applications so that they don't modify each other's data. Isolation stops data leakage and also aids a system that is juggling multiple application processes by providing a way to track the whereabouts of each process. Similarly, hardware segmentation defines the amount of memory an application and its processes can consume. Resource isolation separates resources to keep processes from accessing each other's resources.
Least Privilege
This control measure ensures that an application process has only the necessary amount of privileges to accomplish the tasks it is designed to do. This keeps simple processes from having total system access. The least-privilege concept is also applied to users with regard to access control.
Layering
This is a method of dividing application processes into categories (or layers). Tasks are divided based on the role they play in the system. The inner layers perform more sensitive or high-level tasks while the outer layers work with rudimentary tasks. This separation provides a secure, structured way for processes to communicate with each other. In a process known as data hiding, layers are made invisible to each other to prevent any intermingling of processes whatsoever. Data hiding is also called information hiding.
Data Abstraction
This is the method of classifying objects in a system. Abstraction, which is the underlying basis of OOP, determines a set of admissible permissions and behavioral characteristics for objects.
Reference Monitor
Implemented by the security kernel, this is an intermediary software procedure that monitors process requests. When a process requests access to resources (or a subject requests access to an object), the reference monitor decides if the request should be granted.
Change Controls
The change control process exists to provide a management system that handles changes to applications, networks, or any other integral component of a system. The idea is to set up a system of requests and approvals that govern how and when changes are made, not unlike the checks and balances routine outlined by our constitution.
Change controls are comprised of a series of steps that the proposed changes must work their way through before being transferred to a production system. This lesser process of making changes to an established system mirrors the system development process as a whole; changes fall into the maintenance category of the SDLC. With a focus on full documentation to record every step of the process, this practice is implemented as follows:
-
Request: By filling out the proper paperwork, a formal request is made.
-
Analyze: In this phase, costs are calculated, security-related concerns are taken into account, and an estimated time of completion is gauged.
-
Review: Management reviews the proposal and if it looks good, the change is approved.
-
Develop: The actual code is added to the application or the existing code is altered.
-
Test: Nonproduction testing and quality checks are performed until any existing bugs are worked out.
-
Change: The change is implemented into production. If necessary, versions of software will be updated to reflect the change. Change controls protect the availability of a system, which could be disrupted by the implementation of an untested change.
Data/Information Storage
As you know, data and information are stored and archived via different methods, on various types of media. The systems used to retain and record information are categorized under the following headings:
-
Primary: This is the central memory of a computer. Primary storage is referenced directly by the CPU. Primary storage is limited to the amount of memory in a system, making it relatively minimal in size, as well as costly. Chunks of data in memory are given an address that the system calls when referencing them. When a program crashes, the resultant error might mention one of these memory addresses in an indecipherable string of characters on your (now blue) screen. A loss of power can destroy data in memory because it is kept alive by electricity only. This weakness of primary storage is known as volatility. Random Access Memory (RAM) provides primary storage space.
-
Secondary: This means that the data stored on hard disk drives or other magnetic media. Secondary storage is non-volatile and it supports primary storage with its larger capacity and lower price tag. Being one of the components in a computer with moving parts, HDDs (hard disk drives) can be prone to failure. Executable data in secondary storage must be moved to primary storage before it can directly interact with a computer's CPU or a device on the system.
-
Real: When an application has been allotted its own chuck of memory to reside in, it is said to be in real storage.
-
Virtual: Secondary storage devices are used to increase the apparent amount of physical memory in a computer, resulting in virtual memory. To an application, it appears to be the same as primary storage. Through a process called paging, data is shifted back and forth between the HDD and primary storage areas. Although virtual memory can greatly increase the capacity for running large applications, the process comes with a reduction in performance.
-
Sequential: This describes storage that is accessed intermittently, such as a magnetic backup tape.
Note Virtual memory is made possible by the secondary storage areas of hard drives. It is used to increase the amount of primary storage.
A defined subset of subjects and objects consists of the following:
-
Trusted computing base
-
Security perimeter
-
Reference monitor and security kernel
-
Domains
-
Resource isolation
-
Security policy
-
Least privilege
-
Layering, data hiding, and abstraction
Modes of Operation
To implement security with regard to what an application process can and can't do, at least two modes of operation are specified. In supervisor mode, a process can execute any command it wishes. In user mode, it is restricted. This division is made by separate sets of instructions for each mode. Each set of instructions has its own privileges. This is done so that users or other applications' processes cannot take over a computer's processor.
Applications need total control to do their job, but at the same time, total control must be kept from outside influences. Modes of operation are toggled by the application to provide necessary functions while keeping the system protected. These mode shifts act like a security guard that protects the system's resources. For example, if a user tries to execute a command that requires supervisor privileges, the application switches to supervisor mode and performs the operation. Before giving control back to the user, however, the program will revert the process to user mode. In effect, this distinction of modes protects the memory address space of each application.
Without going any deeper into programming theory, just remember that these modes prevent hostile takeovers by malicious users and they prevent the processes of rogue applications from successfully attacking a system. Supervisor and user modes are defined in a processor's architecture and programs are written to take advantage of this device. The separation of these modes is commonly represented by a set of theoretical rings, as seen in Figure 7.4. These rings correspond to the multiple levels of trust defined by the processor's architecture.
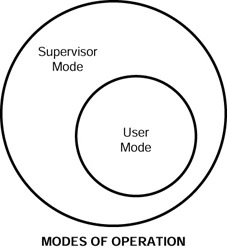
Figure 7.4: Modes of operation.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 136