Section 20.3. Researching the Privacy Space
20.3. Researching the Privacy SpaceI developed the Privacy Space Framework to make sense of existing "privacy solutions." This study had two distinct phases: a feature analysis phase and a validation phase. 20.3.1. Feature AnalysisThe first phase used grounded techniques to assess a sample of solutions in order to "make replicable and valid inferences from data to their context."[20] To do this, I developed a technique known as feature analysis. This technique borrows heavily from the field of content analysis. A central idea in content analysis is that many observed pieces of data are classified into a set of content categories.[21] Text, words, phrases, or other units are classified into categories. Entries in each category are presumed to have the same or similar meanings.
Feature analysis takes a similar approach. Instead of classifying words, feature analysis classifies software features. A software feature is a capability for completing a certain task that has been designed into a system. As such, a software feature can be named and described in words, and the content of the name and description can be analyzed using conventional content-analytic techniques. A privacy feature is a software feature that offers some kind of privacy-related functionality to the user. It is often found that solutions designed for one purpose are later adapted by someone for other purposes. For our purposes, a privacy feature need not be consciously designed, or designed for protecting privacy; it only matters that the feature in question somehow relate to privacy, even if by accident. To compile a list of privacy features , I started with a list of 134 privacy solutions. This list was compiled by examining software download web sites, privacy-related web sites, vendors' web sites, and news articles; visiting online and offline software stores; and following up on recommendations of friends and colleagues. The major product of this effort was a raw list of 1,291 privacy features and their descriptions. The data for phase one was collected in just over a month's time during the spring of 2002. I was able to obtain trial versions or academic licenses for most solutions and install them on my own computer for testing. There were a handful of solutions that I was unable to try myself, and for these I had to rely solely on their documentation for the analysis. To help the reader achieve a better understanding of the utility of the Privacy Space Framework and how it can be used to classify privacy solutions, here are some examples of solutions and their features. 20.3.1.1 Example 1: PGP FreewarePGP Freeware[22] is a program for encrypting and decrypting files and email messages using public key cryptography. The program's name (Pretty Good Privacy) and its marketing leave no ambiguity that this product was designed to help protect personal privacy.
My analysis revealed that version 7.0.3 of PGP Freeware includes 24 features that relate to privacy. Obvious privacy-related features include generating public and private keys, encrypting data, decrypting data, digitally signing and verifying data, and wiping files using a secure algorithm. Some of the less obvious privacy features I noticed relate more to the user interfacethe toolbar that allows easy access to the program's features; the lock icon in the Windows tray that provides visual information about the status of the program; the key management interface that allows the user to easily import and export public and private keys; and even controls for what to do with data left on the clipboard after the program exists. I categorized most such features as relating to prevention. PGP also has many awareness-related features (e.g., graphical depictions of key lengths) and also some detection features (e.g., the ability to verify a digital signature and thus ascertain its authenticity). My analysis found no response or recovery features in this tool, however. Overall, I categorized PGP Freeware as a prevention and awareness tool. 20.3.1.2 Example 2: WebWasherOne of the first tools I evaluated was WebWasher AG's WebWasher,[23] a program that removes advertisements and blocks pop-up windows on many web sites. I was already using WebWasher at the start of the Privacy Space study.
I identified 20 privacy features provided by WebWasher. Most of these relate to its web-filtering capability, such as its ability to filter cookies, web bugs, URL prefixes (e.g., http://search.com?url=http://realurl.com gets changed to http://realurl.com in order to thwart logging and advertising systems), and so on. The user interface for most of these features involves a checkbox to simply turn the feature on or off, as well as some explanatory text about what the feature accomplishes. Predictably, I found that most of these features deal with prevention and detection. WebWasher also includes some awareness features (e.g., a splash screen to let you know when it is running, warning messages when content is being filtered, and statistical information about the program's performance). Unlike PGP Freeware, WebWasher includes a response feature in the form of a connection cutoff button that allows the user to quickly disconnect from a web site feeding harmful content. WebWasher also includes a "black list" feature that I considered to be a response feature. Thus, WebWasher covers all five categories in some fashion. Overall, I considered WebWasher to be an awareness and prevention tool, but also noted its detection capabilities, which, in this case, only mean that in order to filter certain kinds of web content, the tool would have to look for it (e.g., detect it) first. 20.3.1.3 Example 3: ZoneAlarmMany would argue that a personal firewall like ZoneLabs' ZoneAlarm[24] (described in Chapter 27) is a security tool and has little to do with protecting privacy. At the face level, that is true. However, if you take into consideration the user-centered approach of my study, tie in the concept of exoinformation, and acknowledge the enormous amount of sensitive data our personal computers store for us, the role that a personal firewall tool such as ZoneAlarm plays in protecting personal privacy is quite clear.
Based on my criteria, I found 13 privacy-related features in ZoneAlarm. Several of these are awareness related, such as the network traffic meter tray icon (e.g., if you are seeing heavy traffic either coming in or leaving your computer and you aren't using the network, you should probably investigate further), and the numerous different pop-up alert messages. An excellent response feature is the Internet Lock, a means of severing all network communications without having to physically unplug a wire. Passive detection features are built into ZoneAlarm, and response is highly automated, although always at the discretion of the user. For example, when a port scan is detected, ZoneAlarm can be set to automatically block the originator of the scan and thereby prevent any further access from that miscreant. To alert the user of the event, a warning message is displayed (an awareness feature). Although I found the numerous pop-up warnings to be a bit excessive, they could be tailored by severity based on personal preference. As I became more comfortable with the program, I was able to shut off all but the most severe warning messages. I found ZoneAlarm to be a fully featured personal firewall, although the version I evaluated lacked any significant recovery features. I was unable to fit ZoneAlarm into a single overall privacy space category; I wound up noting that it was related to awareness, detection, prevention, and response. In retrospect, I would consider it primarily a prevention tool with significant detection capabilities built in. 20.3.1.4 Phase one resultsLooking at feature counts per solution (Figure 20-1), I found that 19% of solutions contained only one discernible privacy feature. Solutions having five or fewer privacy features made up almost half (47%) of the sample. I view this result as evidence of a need for a more comprehensive privacy system that would include groups of privacy features. Figure 20-1. Number of privacy features found in different software solutions that I studied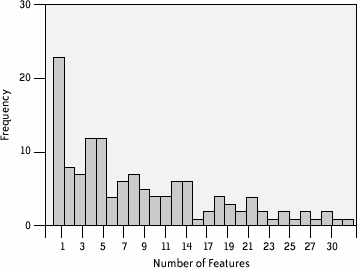 Each solution was categorized using the framework; this categorization took place before the features were analyzed and categorized in an attempt to make a face-level judgment about the solution. Later, each feature was individually categorized as well and compared to the overall solution categorization. In both cases, the prevention category proved to be dominant and the other categories matched up well compared to the feature categorizations, suggesting that face-level assessments are accurate. As indicated by Figure 20-2, very few solutions were categorized as being involved solely with recovery from intrusions. This indicates that recovery might be a likely avenue for new research and/or innovation. Figure 20-2. Solution categorizations in different software solutions that I studied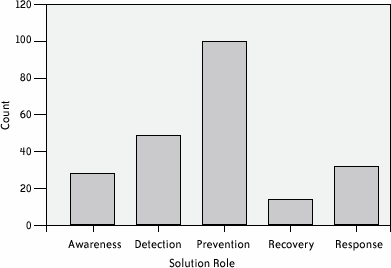 Another interesting trend was the heavy contribution to the privacy space made by lone entrepreneurs. Heavy emphasis was placed upon the use of basic user interface widgets (very few novel visualizations or componentsjust standard graphical UI fare), with the clear hope of turning a profit by targeting operating systems with the most market penetration. Many of the solutions examined in the study disappeared shortly thereafter. Some features have been adopted by larger companies and have become part of privacy software suites (e.g., Norton Internet Security 2002). I speculate that a lot of trial-and-error development has been taking place in lieu of a systematic, user-based approach. Technological privacy solutions have had a market, but that market was smaller and less profitable than many anticipated. Today, tools such as personal firewalls are in widespread use, and spyware scanning and removal tools are just now becoming pervasive; yet it is unclear whether people understand the privacy-enhancing implications of using these tools. 20.3.2. ValidationUsing a sampling of the overall features list, the second phase of the study addressed the issue of validation of the Privacy Space Framework and its categories. Here, we sought to ensure that the work done was sufficiently replicable and hence that it would be useful in future privacy space projects. A stratified sampling technique was used to generate an abbreviated list of 118 unique privacy features from the raw list of 1,291 privacy features. The sampling technique created equally distributed lists of features within the five Privacy Space Framework categories. Despite the overall sample being heavily biased toward the categories of prevention and detection, we elected to use a sample unrepresentative of the actual distribution of features. The intent was to test the framework categories and the feature analysis technique, not the overall results of the first phase.
We used a modified version of the Delphi method, a consensus-building forecasting technique that uses iteration with controlled feedback where the participants remain anonymous to one another. Results of responses are summarized statistically and are fed back to the participants through the multiple rounds of the study. The Delphi method has been used for making planning decisions and setting work agendas and policy in government, business, and industry.[25] The Delphi method is also useful in soliciting opinions on subjects where there already exists a set of sampling data in order to help validate opinions.[26] It is in this second type of application that Delphi applies to the problem of validating the Privacy Space Framework.
Delphi participants were screened via email exchanges and were required to be self-reported "privacy pragmatists"[27] who routinely use or have used at least one online privacy application for a period of time. It was also required that participants be familiar with privacy issues and be using, or have used in the past, some kind of privacy software or service. Routine users of such solutions were preferred, although no formal test or survey was undertaken to ensure that criterion. It was expected that those without the appropriate background would be unable to complete the exercises, so no additional vetting process was used. Fifteen participants took part in the Delphi study.
The Delphi study consisted of an online survey of three rounds and a final exit survey. The study participants were asked to categorize each feature with one or more of the five privacy space categories (awareness, prevention, detection, response, and recovery). Each participant completed this task by assigning a value under each role category. The values ranged from 0% to 100%. If the participant felt that a feature belonged in more than one category, or wasn't sure which one(s) it belonged in, he could allocate the 100 points proportionally. The analysis of the results involved three major comparisons:
The following summarizes the characteristics of these comparisons:
One conclusion we might draw from the results of these analyses is that the Delphi study did not achieve a solid consensus. In retrospect, it is possible that the design of the online surveys was to blame. It is generally acknowledged that temperamental methodologies such as Delphi are unforgiving with respect to flaws in the survey instrument. Despite the difficulties revealed by the analysis of the second-phase data, it is clear that the participants in the Delphi study agreed with my feature categorizations a majority of the time and that this result was not a random occurrence. The within-group comparisons were also highly favorable. This part of the study involved many difficult tradeoffs. Those tradeoffs resulted in there being many uncontrolled variables at play, which, in turn, led to the results being less tidy than I had hoped. If I had the ability to repeat the validation exercise, I would increase the time commitment for each Delphi round and make the participants explain their decisions to one another in writing rather than rely on the numeric ratings alone. |
EAN: 2147483647
Pages: 295