The Development Strategy
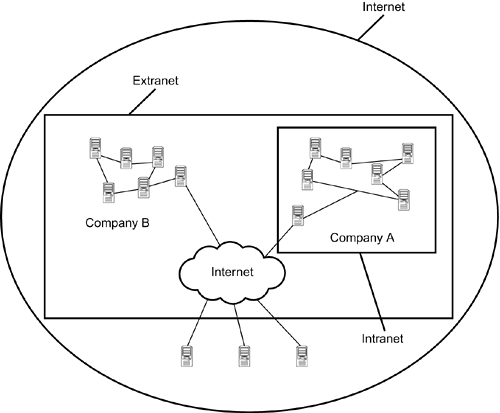
| The foundation for the application begins with an approximation or a sketch of the application's main elements. These elements, in the form of functional and technical specifications, are later separated into the system levels or tiers. Of course, there is always room for a standalone application that runs on a single computer, but for the purposes of this book, the focus is on the foundations of larger-scale applications that use and rely on network communications. Application development can be based on three essentials of network communications: intranets, extranets, and the Internet. Intranet applications are generally designed for a limited number of users working with a single company and operating on a network. Extranet applications are designed for larger numbers of segregated users working in separate companies on multiple networks. Internet applications are designed for the masses, encompassing very large numbers of users with no single network association and communicating through public channels. Figure 5.1 shows a general display of the different scopes of these applications. Figure 5.1. Network solutions.
Besides these three network solutions, you must also make basic design considerations for the three general elements of the system: the user interface, the data store, and the middleware that operates between the two. Each of these different solutions offers up its own unique set of challenges. Many pieces to the puzzle must be considered before proceeding with the system. Choices for each system are made based on the needs and the scope of the development project. Throughout the remainder of the chapter, you will visit many facets of the system and see how each piece plays an important role in the finished product. You should start out by keeping an eye on things right from the beginning and progress through all elements toward a complete system implementation. Auditing and Logging System ActivityYou can monitor system and application activity through a number of different techniques and implementations. The bases for both auditing and logging are essentially the same or similar concepts. You must determine who and what you are monitoring, under what circumstances these events are trapped and kept, and where the information gathered by the process is to be stored. Taking note of particular system situations is important so that you can take applicable actions to allow the system to perform as it was designed. Elements that are exposed to external individuals, public communication systems, and other sources should be closely monitored. Minimally, you should be planning for techniques to monitor system problems. You might also want to record the application user's activities for the purpose of maintaining statistical information. In a secure environment, you need to track attempts at breaching system security. Also, some situations could warrant maintaining information on elements of system usage to help you understand where optimized processes might better the overall system performance. The information collected by monitoring can be stored in a number of different locations and/or data stores. System, application, and security logging can be stored in the Windows NT/2000/XP/.NET event logs maintained by the built-in Event Viewer. Server-level applications, such as Microsoft Exchange Server, Microsoft SQL Server, and Microsoft Internet Information Server/Services (IIS), automatically maintain other information. Web server security can be addressed through locking down Master Properties of the WWW Service and enabling auditing and logging by default on all Web sites. Still other resources are available, such as the use of the Repository for storing data changes when strict data-handling rules are implemented into the system. The Application event log (see Figure 5.2) stores errors from applications running on the machine. Figure 5.2. The Application log in Event Viewer.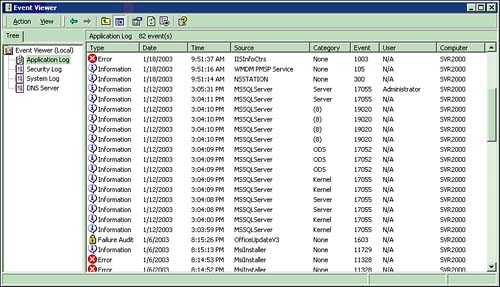
Monitoring and logging system information essentially breaks down in the following manner:
Other forms of monitoring and logging are equally important within the environment, but fall more on the shoulders of the network administrator than the developer. When putting together the physical schematics and functional design, information that these administrators can act on must be recorded. The documentation about the system's characteristics helps the IT staff properly plan for the necessary security in the system. After the system security plan is in place, network facilitators should accommodate activity monitoring. Logging information is an important aspect of application security and stability. An equally important aspect is periodically viewing the log information and acting on what is found. Recording the information is worthless if no one is looking at and responding to it. Breaches in security need to be remedied, holes need to be patched, and errors need to be fixed. Appropriate Error HandlingThere are many approaches to error handling in single applications or entire multi-application systems. How errors are handled depends on the ability to act on the error and remedy the problem. Some errors, particularly those made during data entry, can be caught and corrected at the user interface before any other handling by the system. Other errors cannot be caught, such as a lost connection or data error that requires a test against current data. Therefore, handling the possibility of errors at all tiers in the system is important. Of course, error handling is essential during the development process, and a strong test plan should be implemented to eliminate coding errors. With the advent of the Visual Studio .NET product line, handling errors in a traditional, unstructured fashion is possible, or you can make use of new functionality and use structured error handling across the entire product line. The general functionality of these methodologies is defined in the following sections. Structured Exception Handling
In structured exception handling, tests for specific errors are performed at the point in the code most likely to cause problems. Blocks of program code are encapsulated within the error-testing mechanism. Each block of code has one or more associated error handlers, with each error handler specifying a condition on the type of error it can handle. If an error occurs at that point in the code, the corresponding error handler is implemented. This "Try/Catch" functionality has been used in object-oriented programming languages for a number of years. Structured error handling is shown in Figure 5.3. Figure 5.3. The Try/Catch structure. Unstructured Exception HandlingWith unstructured error handling, the capability to specify the location of the error handling is quite limited; essentially, you turn error handling on at the beginning of the process. It then has "scope" over that process and handles any errors occurring there. If the program encounters an error, program execution is diverted to another part of the program where the handler is located. Handling Different Error TypesSyntax errors, logic errors, and errors caused through user error and system malfunctions can collectively be the downfall of any application. Any one of these problems can threaten the existence of a system and cost valuable development time. Errors can also be financially detrimental if not repaired in an expedient and complete manner. Some errors are more easily solved than others. Syntax errors, for example, are normally noted at the time of coding, or at least the majority of them are recognized when an application is built and/or compiled. To minimize syntax errors that cannot be caught in the development environment, you need to concentrate on minimizing dynamically prepared code. Code assembled by the concatenation of strings, variables, and user input is more likely to produce errors. If you need to use this type of coding, ensure that a structured error-handling approach is used to trap any possible errors that might be generated. Logic errors are often more difficult to find, as any experienced developer will tell you. You can spend an agonizing amount of time testing and debugging an application and still find bugs when the application is deployed. One of the best techniques for minimizing this problem is to use a pilot rollout to a select group of individuals who are prepared to be beta testers of the product. Regardless, you should always perform post-installation checks against expected results to eliminate any errors you find. Data entry and other user errors can be a true nightmare. Wouldn't it be a wonderful world if everyone using an application was an IT professional with bullet-proof typing accuracy? A dream, of course, but there are procedures that can be used so that such errors are gracefully handled and corrected. Again, the use of structured error handling is important in areas of the program that might cause errors. Data validity checks, checking for as many predictable errors as possible, are important at every tier. As for the unpredictable (or should I say inevitable?) user faults, the code should identify the problem in plain English so that upon any failure, you can at least determine what went wrong. (Don't you just hate those cryptic error messages?) System malfunctions can be hard to plan for and can cause many applications to be unusable. Disconnected recordsets, backup measures, fallback alternatives, and other solutions can be built into some systems, but they can't be applied to every installation. When possible, try to record information, and when the results are critical to the application's success, use transactions so that you can determine what has been accomplished and saved and what hasn't. Integration to Leverage InvestmentSystem integration is a particularly challenging aspect of development in larger systems that combine a variety of platforms and technologies. Although it can be a challenge in any system, there are many opportunities to leverage current investment by integrating data sources, components that have already been designed, and elements of the system common to multiple systems. Techniques are available to integrate almost any technology with any other technology. Data integration is possible through Open Database Connectivity (ODBC) and OLE DB to any industry-standard data source. Mainframe integration is possible through Systems Network Architecture (SNA) technologies, such as Component Object Model Transaction Integrator (COMTI). Internet, extranet, and intranet integration can be performed by using Distributed COM (DCOM) and/or ASP.NET technologies. Integration can save a considerable amount of development time if properly thought out; however, it can also add development time if advanced technologies are not correctly utilized. World-aware systems are well within the reach and budget of most organizations these days, but leveraging previous investments requires proper planning. Globalization to Deploy to the WorldYou have visited the topic of globalization in Chapter 3, "Gathering and Analyzing User Requirements," and have learned it is the process of developing software that functions in multiple cultures/locales. This involved process must be taken into account whenever your application is going to be used by people in many countries having diverse cultures. In product globalization, you must first identify the cultures and/or locales the software needs to support, and design features into the product that will support them.
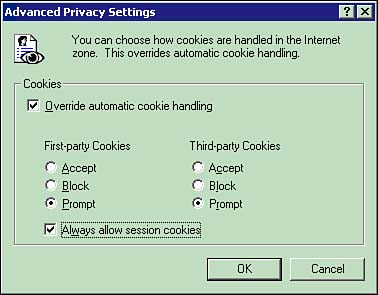
Writing applications that function equally well in any of the cultures supported is important. Globalization adds support for entering information using different formatting standards, displaying data in a manner the user expects, and outputting the data so that it is compatible with the culture using the information. It involves the use of a defined set of language scripts that relate to specific geographic areas. The most efficient way to globalize an application is to use the concept of cultures/locales. A culture/locale is a set of rules and a set of data standards that are specific to a given language and geographic area. These rules and data standards include formatting dates and times in the manner used by the culture. You must make provisions for numeric, currency, weight, and measure conventions as well as the locale's character set, which can also affect how data-sorting routines are implemented. Localization and LocalizabilityA model for dealing with multicultural application development divides the process of developing world-ready applications into three distinct parts: globalization, localizability, and localization. You have taken a quick look at globalization principles in the previous section, so now you'll continue by looking at localized development. In localized applications, you prepare an application to be sensitive and appropriate to different regional and cultural conventions, so you need to present data in a variety of languages and formats applicable to the locale. Localizability is an intermediate process that verifies globalized applications to determine whether the application is ready for localization. This process is really only a quality assurance phase. It is during this phase that you discover and fix any errors in the source code that preclude localization. Localizability helps ensure that localization does not introduce defects into the application. Localization means an application can be released more rapidly and handle all cultures that it is intended to service. In the majority of instances, no additional development is necessary to localize an application after the initial version is completed. Implementing world-readiness is part of the original development process, and post-development localization is a thing of the past. Properly prepared applications are easier to maintain. Building a localized version of the application with only isolated modules needing localization makes maintaining code easier and less expensive. The key to this aspect of localization is using resource files for localized versions of the application. Applications should use Unicode character encoding to represent text, as this 2-bytepercharacter mechanism allows for more than 65,000 character possibilities. Unicode enables you to represent virtually all text in the common communication characters for every spoken language in the world. If for one reason or another you cannot use Unicode, you need to implement double-byte character sets (DBCSs), bidirectional text, code page switching, text tagging, and so forth. Another common technique is implementing a multilingual user interface. Design the user interface to open in the default language and offer the option to change to other languages. Watch for Windows messages that indicate changes in the input language, and use that information for spell checking, font selection, and so on. Sensitivity to cultural and political issues is another important facet of development. Language that is considered "normal" to some can be offensive to others. Avoid slang expressions, colloquialisms, and obscure phrasing. Avoid images in bitmaps and icons that are ethnocentric or offensive in other cultures/locales. Avoid maps that include controversial regional or national boundaries. To localize an application, isolate all user interface elements from the program source code and put them into resource files, message files, or a private database. Using the same resource identifiers throughout the life of the project aids in ease of maintainability. Place strings requiring localization only in resources. Leave non-localized strings as string constants in the source code. Allocate text buffers dynamically because text size and dialog boxes might expand when translated. If you must use static buffers, make them extra large to accommodate localized strings. Data StorageThere are a multitude of different storage mechanisms for data that utilize everything from the smallest of personal computing devices to the largest of mainframes, and all can be leveraged in any given application. For the most part, the decision lies in whether to create a new data store or utilize existing data storage. At times, data can be ported onto compact devices to allow for some portability of data, but for the most part, these devices are insufficient to store the enormous amount of information used in most large business systems. In today's IT environment, data can be made available throughout the enterprise in a variety of data stores and operating systems through connection mechanisms and industry-standard software interfaces. Data stored on mainframe systems that use technologies such as Virtual Storage Access Method (VSAM), Information Management System (IMS), and DB2 can provide information to a PC network or send data to the Internet with relative ease. PC-based storage technologies, such as Microsoft SQL Server, can store data in their own definition through SNA's COMTI technologies or can provide a mechanism for getting data to and from other systems. For the most part, if data is already in existence on a mainframe, the cost of moving the data usually cannot be justified. By providing integration to existing mainframe data, you can provide data access to PC-based networks. In doing so, you preserve the investment in mainframe equipment. Integration with existing data provides the opportunity to support a migration strategy that can safely take small provable steps and minimize risk factors. Formats of data storage other than database systems are described in the rest of this section. Most application designs involve some level of data management. ODBC and OLE DB technologies are available to allow access to virtually any data source from within any application. Network applications can access this data directly, and Web-based applications can use XML or disconnected recordsets provided by the Web server. When creating a new data store (or if you need to move data from an existing source), you have to select a data-storage strategy that makes the most sense for your application. Office-based applications can use Microsoft Excel workbooks or Microsoft Access databases at very little cost, but when you are dealing with a larger amount of data or a multitude of users, these systems are unlikely to suit, and you will require a larger data store on a database server. Because this book covers Microsoft technologies for a Microsoft exam, that choice would be Microsoft SQL Server. Whether you store your data in Excel, Access, or SQL Server, you need to design a data structure to suit the purpose. The design of the data structure is beyond the scope of this chapter, and is discussed in Chapter 8, "Creating the Logical Data Model." Access or SQL Server relational database development incurs a larger development cost than working with Excel does. The cost is usually offset through improved maintainability of the data, however. Excel is best suited to small amounts of data on which you must perform calculations or that you want to present in a grid or chart. However, the lack of a proper data structure limits the data's usefulness for other purposes. Larger data sets that provide structure and are stored in Access or SQL Server can always be imported into Excel from any OLE DB or ODBC data source, if needed. Excel is best suited for use with one-time data storage or in summarizing statistical data drawn from another source. In using a relational database for an application geared to a single user or a small workgroup, Access or the Microsoft SQL Server Desktop Engine database is likely to be your best choice. The advantage to using the Desktop Engine is you can use it to create a SQL Server database from Access without actually having SQL Server on your computer, making it easier to port data to and from a larger dedicated database server. State ManagementThe term state with regard to application development refers to the system's capability to know what each individual user is doing. The data and other resources the user is working with must be maintained for each user; at the same time, you must prevent corruption of this information or access by other users. Maintaining information is closely related to the data storage topic in the previous section. State management is an issue particularly when working with applications designed for the Internet. In an application, each Web page is re-created every time the page is posted to the server. In some Web programming implementations, all information associated with the page is lost with each round-trip to the server. In many applications, it is important that this data not be lost; instead, the data should be stored temporarily so that it can be referred to during the session and often in future sessions. A variety of mechanisms are available to deal with state management of any system. Data, personal information, and changes to this information can be preserved in a variety of data stores. Visual Studio .NET has a feature called ViewState, which automatically preserves a Web page's property values and all associated data between round-trips to the server. By using this feature and saving application-specific values, you can interact with and preserve state information. Essentially, you have a decision to make concerning whether you want information to be stored on the client, where it can be retrieved quickly when the application is in use, or whether you want to store data more permanently on the server. If the data is stored on a server, obviously you must address accommodations for the resources used, as extra storage is likely to be needed. Each storage option has distinct advantages and disadvantages, and maintenance of state is usually implemented as a combination of the two techniques, depending on how the data is to be used. Client-Side State ManagementClient-side state management, as mentioned previously, uses resources on the user's computer to store data; the information is made readily available with no need for round-trips to the server to obtain the data. The biggest downside to this form of storage is that the data itself falls under the user's control and can easily be deleted or otherwise tampered with. Scalability also becomes a major factor in dealing with client-side state. In client-side state management, many features are available. ViewState, query strings, hidden fields, and cookies are discussed in the next few paragraphs. ViewState is used when you need to store small amounts of information. This feature is useful if a Web page in an application posts back to itself. Security is present in the use of ViewState, but is very limited. Hidden fields are used for storing small amounts of information and are also useful in an application in which a page posts back to itself or to another page. Hidden fields are not a very secure technique for state management, however. Cookies are used when you need to store small amounts of information on the client machine. The lack of security and/or reliability, however, might affect the capability to use cookies as a form of state management. Query strings are useful in transferring small amounts of information from one page to another when security is not an issue. The first notion to understand is the use of ViewState. Web-based controls and Web server controls have a ViewState property that provides a dictionary object for retaining values between multiple requests of the same Web page. This method preserves page and control property values between round-trips and is used during a single session when posting data back to the same page. Whenever a Web page is processed, the state of the page and controls is saved into a character string. This string is then saved in the page as a hidden field. When the page is posted back to the server, the Web page can be parsed and a server-side application can view the state string. Closely related to the concept of ViewState is the use of hidden form fields that have no direct user interaction. Microsoft Web-based technologies enable you to use fields that are hidden from view, although physically still on the page the user is viewing. The field, although unseen, can have properties set and values maintained just as though it were any other control on the page. The information stored in these fields and other visible fields is sent back to the server when a Web page is submitted. A hidden field acts as a storage repository for any page-specific information you would like to store. The biggest negative to the use of hidden fields is that you are not really hiding the data from the user. If the user selects to view the page's source code, the values maintained by the field can be seen and potentially altered or otherwise tampered with. A hacker can use these fields to corrupt the system and potentially even bring the system down or cause worse consequences, depending on what the data exposes. In many instances, you might want to store data from one session to another so that when the application runs in the future, it can obtain values from a data store. Cookies servethe purpose of storing data in a physical file on the user's hard drive in the temporary Internet cache or in memory. A cookie can hold a small amount of data. Usually the data identifies the user and the properties and preferences used over again in every session. A cookie contains page-specific information that the server sends to the client along with page output; the browser then stores the information for future retrieval. Cookies are temporary unless provided with expiration information; in which case they are persistent, remaining on the user's computer unless explicitly changed or deleted. Generally, cookies are used to store information about a particular client, session, or application. The server can read the information stored in the cookie and extract its values if needed. A possible use is to store an encrypted token that could indicate the user has been authenticated. Other uses are varied because cookies can store any desired information. The Web browser sends data back only to the server that originally created the data; therefore, cookies are a relatively secure way of maintaining user-specific data. You should exercise caution when using cookies because you can set the cookie's domain property to a domain, thus exposing the cookie to all servers in the domain. Cookies tend to be a nuisance to most users, and blocking cookies (particularly third-party cookies) is a common practice. Internet Explorer 6.0 now blocks third-party cookies by default. The Internet Explorer settings for cookie use are shown in Figure 5.4. Figure 5.4. Cookie management options in Internet Explorer.
The disadvantage to cookies, as with other forms of client-side storage, is that the user can access the cookie. This means the user can delete the cookie, often unknowingly by clearing the Internet cache. Cookies must also be accepted by the user, and some browser settings prevent storing cookies on the user's machine. This is, in fact, a common practice to thwart advertising companies from placing unwanted cookies on the computer. The final client-side technique used frequently to send information to the server is the use of query strings. A query string is information added at the end of a URL. It starts with a question mark and includes any attribute values. A query string can provide a simple but extremely limited way of maintaining some data from the client and a way to pass information from one page to another. In most cases, query strings are limited to 255 characters. In addition, query values are exposed to the Internet via the URL, so in some cases security can be a significant issue. You can see that most client-side mechanisms have significant drawbacks and would not be used to store large amounts of data that must be present for an application to function properly. Also, with client-side facilities, the user must be connected to the application for the server to have access to the data. This makes most client-side mechanisms undesirable for many applications. Server-Side State ManagementUnlike client-side techniques, server-side storage of state information offers many ways to maintain large amounts of state information that is always available to the server. Data is made available for statistical analysis or use by other applications, as the information can be stored locally to the server through a variety of techniques. Other server-side mechanisms offer more functionality and flexibility than their client-side counterparts. A Web server has two basic types of state information it keeps for every application: application and session. Application state is the system-level data accessible to every user of the application and is often referred to as global state data. Session state is maintained on a user-by-user, session-by-session basis and is, therefore, independent of the activity of other users and sessions. Application state can be used if you are storing infrequently changed, global information. Application state is useful in storing information needed by many users. However, it has a very limited form of security and should not be used to store large quantities of information. Session state is useful if you are storing short-lived information specific to an individual session. Again, lack of sufficient security can be an issue, and you should not store large quantities of information. Maintaining too much application or session state information can occupy significant server resources and drastically affect scalability. Database support is the best alternative for storing large amounts of information. Database storage allows for transaction management and is most useful when stored data must survive application and session restarts. Data mining can be a major concern, and security can be an issue if not properly implemented. IIS and other Web server systems enable you to save values using application state for each active Web application. Application state, because of its global outlook, can be accessed from all pages in the application. This form of state management is useful for storing information that needs to be maintained between server round-trips and between pages but is not specific to any one user. Application state information is available while the application is running on the server and is erased after the application stops. Therefore, you need to combine application state management with database storage or other physical storage principles if the data is needed outside the application scope. Session state, on the other hand, allows saving values for each active session, not necessarily one session per user, as it is possible for a single user to have multiple sessions open at any one time. Session state is erased when the browser is closed or the user navigates away from the application. Therefore, you need to combine session state with other forms of storage if the data will be needed after the session has been closed. A common use for session state is to identify browser or client-device requests made to the server. These requests can be assigned to a specific session. Session data allows for temporary storage of data from the initiation of the session until its termination. This temporary storage creates a set of variables that the application can use without repeatedly fetching the information from other data sources. Because both application and session state are temporary forms of variable and object information storage, it is usually necessary to provide database support to store some of the information. Maintaining state by using database technology is commonplace when storing large amounts of user-specific information or simply when the data is important enough to keep available at all times regardless of system failures. Database storage is particularly useful for maintaining long-term data that must be preserved for an application or session, even if the server must be restarted or the application and/or session is closed. ASP.NET also provides Cache State as an alternative to application state. Cache State uses built-in synchronization, which eliminates the need for locking mechanisms. Database storage is often combined with the use of cookies as a backup mechanism should something happen to the data stored in the cookies on the user's computer. Also, cookies can supply identifying information that allows pertinent data to be drawn from a database. Using databases, you gain the increased functionality and reliability of storing data in a secure location that can be backed up and is, therefore, more reliable. It is much easier to uniquely identify the browser or client device assigned to a particular identifier and relate stored information to that identifier. Data in the database can easily be altered and stored back in the database. Any data stored in the database is accessible throughout all applications in all sessions. Constraints to Support Business Rules and Validate DataData validation is a set of practices that attempt to guarantee that every data value in a data set is as correct and accurate as possible. You can perform data validation by using several different approaches, each operating at a separate tier of a system. Data validation is performed through the use of user interface code on the front end to perform simple tests on the data that minimize the efforts the rest of the system needs to find errors. Application code in the middle tier is set up to find more complex errors that might require intensive processing or access to other data values. In the physical data store, you use database constraints, rules, triggers, and other processes as a checking mechanism to perform checks within the data structure itself. Data validation falls into four basic categories, regardless of the level of checking:
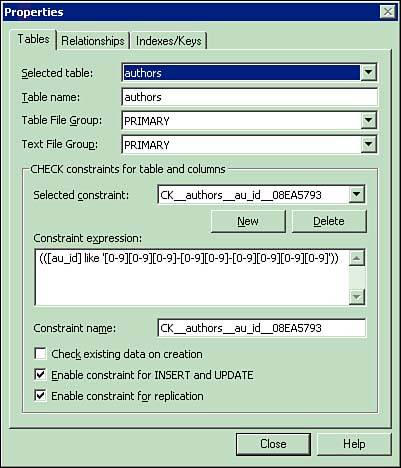
One of the most basic forms of data validation is verifying the type of the inputted values against the expected type for a field. Data type validation can check input to make sure numeric content contains no invalid characters or perform more specialized testing that ensures a string contains only alphabetic data. Usually, these types of checks are performed within the user interface on a field-by-field basis. In this manner, the data can be corrected before the user advances to the next field. A similar technique in the user interface is form validation, which involves checking all fields at once in a large process and providing feedback on all errors found. In this type of development, make sure you provide feedback on all missing or incorrect data. It can be annoying to the user if it takes several processes to complete a form while waiting for feedback each time an attempt is made to post the form. Range checking is similar to type checking, except that checks are also made to ensure that inputted values are within allowable minimums and maximums for the field. Checks can be made for negative values that shouldn't be allowed or to ensure that an entered date fits into an acceptable range of valid dates. As with data type validation, your user interface application can generally provide this checking and minimize the amount of incorrect data sent ahead for further processing. Code checking is much more complicated. You might require access to data stored in a table or other data source, or require database access to search against acceptable code values. A common code test is to ensure that postal code information is suitable for the area of the country provided with the input. You might have completely different processing needs for other areas, such as calculating applicable taxes for different provinces, states, and countries. This type of validation procedure is generally implemented as a business rule in a middle-tier service. The code could stand on a business rules server performing multiple checks, some of which could perform database queries. Some code checking that does not require data access, as in smaller table lookups for state codes, can be performed within the user interface application. The more complex the checking mechanism is, the more likely it resides in the middle tier away from the user interface and, in most systems, away from the data store. This form of middle-tier application is intended to perform intense data-checking processes while minimizing the load placed on the data storage server itself. Data can become corrupted, regardless of the amount of checking performed away from the data store, so in most systems you find actual physical objects in the database that provide an additional level of data-exception checking. Constraints, triggers, and rules are all techniques available in most enterprise-level database management systems to provide this additional level of protection. Figure 5.5 illustrates a constraint in the table definition of the Pubs sample database provided with SQL Server. Figure 5.5. Setting up a constraint to control data validity.
Deployment Strategies to Get the Product Out ThereThe deployment of a particular application is determined by those responsible for day-to-day system operations and those on the system development team. There is no single approach, but this section covers a variety of deployment options. Many variations of these options are possible, and you could potentially combine a number of deployment options in any particular system. To understand the deployment characteristics needed, you must consider the components of the system in which you are deploying. Normally, you deploy components in a single tier or farm, but for a variety of reasons, deploying the same component in many locations is also possible. Many of the basic deployment scenarios are discussed in this section. A lot of Internet projects deployed to Web servers can initially be deployed through simple copying mechanisms. This method is useful for simple updates of static Web pages or updated graphics, but should not be the limit of the deployment. If copying techniques are used, you should also use the facilities available on the server to properly monitor, log events, and control security. In larger systems, permissions and access vary, depending on which area of the system the user is interacting with. Automated deployment of applications is also readily used to get applications to the appropriate users on an intranet or controlled network. Microsoft Systems Management Server (SMS), Active Directory application deployment, and other third-party tools can effectively ensure that applications users need are installed on their computer systems. The advantage to this type of deployment is that the user can be hands-free from the installation. Distributable media, such as CD, DVD, and floppy disk, can be used with the Windows Installer technology. These programs can be installed directly from the media, or the contents of the media can be copied to a network share for installation across the corporate network. The Visual Studio .NET software can easily accommodate this form of deployment through setup projects. Distributable media can be a convenient way to distribute an application that does not require involved configuration. Web project setup and installation through Visual Studio .NET is similar to a standard Windows Installer setup and preferred as a deployment mechanism to Web servers. The Web server installation automatically takes care of component registration and some application configuration. Other types of deployment projects can be used to facilitate more involved deployments. There are many advantages to the new deployment strategies Microsoft provides in its new line of development products. Through the newest Visual Studio release, you can easily generate shared components and CAB creation installation as well as the previously mentioned Web and Windows Installerstyle projects. Merge module deployment options can easily handle the deployment of application modules that are to be used by a variety of applications. Using these deployment projects, you can now easily have components whose code can be shared with a number of programs simultaneously, thus leveraging the development effort. Cab Projects enables you to deploy applications via a Web browser. Using the .cab files created with this technology, you can efficiently deploy ActiveX controls and other components through the Internet. Using any of these techniques or a combination of these strategies can enable you to deploy Windows applications that will be used in many environments. In heterogeneous environments, these applications can be integrated with the current system or can coexist with systems they might be replacing down the road. Coexistence Strategies for a Smooth TransitionIn a coexistence deployment strategy, you retain the original system after deploying a new one, which can offer a number of positive results. The two systems can run in parallel to minimize the risk and ease the movement to a new approach of handling corporate procedures. New users of the system can use the newly developed system, and existing users can remain unaffected until a slow migration over to a single system can be performed. In this respect, a staged migration can be planned between the original and the newly developed system, thus gaining users' trust because they can actively participate in the migration process. In a coexistence strategy, system bugs and performance shortfalls can more easily be noticed. In planning coexistence, the system can be partially or entirely run in parallel. If this strategy is properly implemented, usually movement to the new system is smoother. It is, however, a more costly process, as procedures are often duplicated and many tasks are redundant. Coexistence can also add to the cost of licensing, particularly if licenses are purchased on a per-connection basis. Appropriate Licensing MeasuresThere are many issues to consider when it comes to software licensing. As software developers, I am sure we all would like to be paid for the software we develop. Few of us can boast that we have never pirated software, but as a developer, certain bells should go off in your mind when you hear about so-called free software. Many hours go into developing programs and technologies, but all too often, these products can be found on an illegal bulletin board or file share. Therefore, you should ensure that everyone is appropriately licensed for the tools used in the system. Doing so can relieve a lot of headaches at a time when development companies seem to be cracking down on lawbreakers. Now I'll jump down from this soapbox and move on to discussing how developers can protect their investment and the investment of the companies they work for. After investing time in coding a component or other system element, building a licensing strategy into the project helps ensure appropriate use by only authorized users. Managing licensees is an ongoing process. If you choose to license a component, Web Service, or another element, you must think about possible malicious use of these elements. As readily as license key information is available over the Internet, at best it is often a matter of keeping the honest people honest while taking action against blatant misuse and abuse. In Web Service licensing, you must determine how you are going to identify Web Service users and verify their identities. The duration of each registration and techniques used to block access must all be considered. Making these decisions helps you decide what the licensing will look like. Although it is possible to use a Simple Object Access Protocol (SOAP) interface, it would be far simpler to use ASP.NET. First, you want to obtain information for billing and authentication purposes. The amount of information needed is a decision you'll make for each site, but minimally, it should include the licensee name or company name as well as e-mail address and/or personal address information. After the data is submitted, a verification process could ensure identities before licenses are issued. When licensing components and other programs on distributable media, you can build license key data into the distribution product. You can make licensing allow for further development, as is often the case with ActiveX control licenses. Extensibility enables a development team to use and modify the original product. You can also configure licensing so that the product is used solely as it was originally developed. Licensing in this respect prevents another programmer from adding functionality and repackaging a modified control. Data Migration or IntegrationIn a well-designed system that has been in existence for a while, data sources are used as they stand whenever possible. Usually, the current platform of a data source is maintained, and few changes are made to the data structure. Data migration can be costly and should not be taken as a foregone conclusion. When a system is being developed from the beginning, you have choices as to what source and platform should be used. If a system, however, is aging and the current data source can no longer meet the demand, it might be time to consider moving the data to a different platform that provides the necessary improvements. Integration with current data sources is a far better solution than assuming data is to be migrated to a new platform. When you make the choice to migrate data to another platform, you must factor a variety of elements into the deployment process and development budget. For example, data movement from platform to platform can be handled in different ways, and custom data migration routines might be needed. To get mainframe systems and PC networks working together, you can use SNA and host integration technologies currently available to all for the coexistence of both types of systems. Most other data technologies built on ODBC or OLE DB standards can be more easily manipulated from one source to another. Products such as Microsoft SQL Server can use industry standards to aid in migrating or transforming data. |
EAN: 2147483647
Pages: 175