Process/Thread Scheduling Now that we have seen the fundamental structures used to define a process's logical space and assign system resources, we must consider the task of scheduling threads for execution. This is one of the kernel's primary responsibilities and requires a considerable number of system resources. Traditionally, UNIX is designed to be a load-leveling operating system; that is, the kernel attempts to distribute access to system resources in an equitable fashion to all active threads. While this is a noble cause, at times you might like certain threads to receive a larger (or possibly smaller) share of the kernel's attention. Many operating systems accomplish this by assigning a priority to a job. UNIX has priorities but they don't function exactly the way you might suspect. HP-UX uses priorities to place threads in an appropriate run queue. When a processor needs to determine what to do next, it simply goes to its strongest active run queue and context switches to the first thread in the queue. A thread's position in a run queue is subject to possible kernel-induced priority decay, "voluntary" time slicing (round-robin queuing), and preemption by threads from a stronger queue being awakened. In this section, we explain the various schedulers and introduce the "mystic formula" by which HP-UX adjusts a thread's priority. A natural tendency in the discussion of priorities is to think in terms of numbers. We encourage you to instead consider only relative strength: is one priority stronger or weaker than another? There are several different priority schemes in use in the kernel. For some, zero is the strongest possible priority, and for others it is the weakest! (see Table 5-1.) Table 5-1. Priority policiesScheduler | Policy # | Policy Label |
|---|
HP-UX Timeshare | 2 | SCHED_HPUX SCHED_TIMESHARE SCHED_OTHER | | | 8 | SCHED_NOAGE | HP-UX Real Time | 6 | SCHED_RTPRIO | | | 0 | SCHED_FIFO | POSIX Real Time | 1 | SCHED_RR | | | 5 | SCHED_RR2 |
The challenge for modern UNIX systems is to incorporate the various priority schemes into one contiguous model. HP-UX uses a combination of three primary scheduling schemes: the traditional UNIX timeshare, HP real-time, and POSIX real-time schemes. Each scheme maps a range of priorities to a series of run queues; Figure 5-12 illustrates how the three schemes have been merged into a single priority continuum. Figure 5-12. Thread Priorities 
Each run queue has both internal and external priority values. The POSIX priorities presented a couple of challenges for the kernel designers. First, the number of POSIX priorities is a tunable parameter; 1 is the weakest priority, and the strength progresses as the value grows to the maximum of 512. For the other existing priority schemes the more positive the integer value the weaker the priority! This conundrum was addressed by adding the maximum number of POSIX priorities (512) to existing number of HP real-time and timeshare priorities (256) for a new total of 768 possible values. For internal use a process/thread priority is assigned a value between 0 and 767. An equivalent external priority is calculated using kernel macros and will fall in the range of 512 to +255, To understand the external number, we need to look back into the HP-UX history books a bit. Earlier versions of HP-UX had only 256 priority values 0 to 255, strongest to weakest which were reported via commands such as ps, top, and glance. Legacy scripts and programs expect timeshare processes to have priorities between 128 and 255. In order to maintain this standard and protect these scripts and utilities, an external number scheme needed to be developed. It was decided to report POSIX priorities as negative integer values starting with 1 and decrementing to the tunable maximum of 512. This approach meant that what used to be reported externally as the weakest priority of 255 stills comes out as 255. The strongest HP real time was and still is reported as 0, and the new strongest POSIX priority is reported as 512. Implementation of this model is really quite simple, as the POSIX real time priorities are simply inverted and added to this reporting continuum in the range of 1 to 512. This also maintains the concept that the more positive the value, the weaker the priority. There are several kernel parameters that relate to the priority system: PRTSCHEDBASE = 0: Strongest internal priority. RTSCHED_NUMPRI_FLOOR = 32: Minimum number of POSIX queues. MAX_RTSCHED_PRI = 512: Maximum number of POSIX queues. RTSCHED_NUMPRI_CIELING = ?: Tunable number of POSIX queues (defaults to 32). PRTBASE = 512: Strongest HP Real time priority. PTIMESHARE = 640: Strongest timeshare priority. PMAX_TIMESHARE = 767: Weakest timeshare. pzero = 153: Uninterruptible sleep upper limit. puser = 178: Start of the user-level priorities. timeslice = ? (default is 10): Number of 10-ms ticks a thread is allowed before a voluntary context switch is called by the kernel.
As priority values are stored in the kthread structure (kt_pri) according to their internal value, you may need to convert them when looking at dumps or q4 printouts. Here are the equations to convert between the two schemes. To convert an internal priority to an external priority: External-Priority = Internal-Priority MAX_RTSCHED_PRI
To convert an internal priority to an external POSIX priority (the priority number you would pass as an argument in the rtsched() system call or rtsched line-mode command): External-POSIX-Priority = (MAX_RTSCHED_PRI 1) Internal-priority
To convert an external POSIX priority to an internal priority: Internal-Priority = (MAX_RTSCHED_PRI 1) External-POSIX-priority
Next, let's examine the scheduling schemes. SCHED_TIMESHARE and SCHED_NOAGE The classic UNIX scheduler is implemented in HP-UX as SCHED_TIMESHARE. This policy has two additional aliases: SCHED_OTHER and SCHED_HPUX. In Figure 5-13, we illustrate the basics of the timeshare scheduler and position it with respect to the overall priority system. Figure 5-13. Thread Priorities 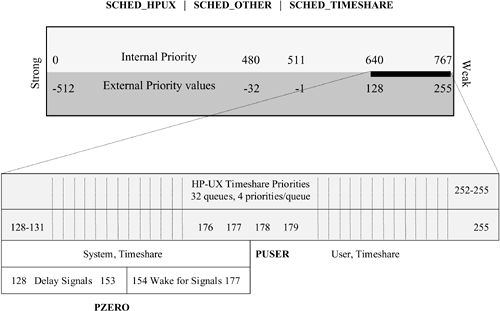
This scheduling policy consists of 32 run queues. Each queue contains four sequential priority values. The strongest queue handles threads with priorities between 128 and 131, while the weakest handles those between 252 and 255. The four priorities per queue is part of the legacy left by the early UNIX development work done on an older Digital Equipment Corp. hardware platform. The system was set up to handle 32 unique queues; this number was carried through in the UNIX kernel design. When it was decided to increase the priority range to an 8-bit value (0 to 255), the existing 32 queues were divided into the upper half of the number range, allowing for the later introduction of additional higher priority schemes. System-Level and User-Level Priorities Overall, the SCHED_TIMESHARE queues are divided into two groups. External priorities 128 to 177 are system-level priorities; 178 to 255 are user-level priorities. The system parameter puser sets the base priority for the user level (this should not be changed!). The system-level priorities are reserved for privileged kernel routines and system call code running on behalf of a user thread. Threads assigned one of the user-level priorities may have their value adjusted by the kernel depending on current system resource utilization levels or the thread's behavioral patterns (more on this later). This adjustment by the kernel is called priority decay. System-level priorities are said to be nondecaying; that is, their priority is not adjusted by the kernel. Threads in the system levels may fall into one of two additional subdivisions: those that will be awakened from a sleep queue to handle an incoming signal and those that will delay signal handling until whatever they are blocking on wakes them. Have you ever tried to halt a process with a kill-9 only to see it still there when you run ps immediately afterwards? If so, then you may be looking at a thread sleeping in the un-interruptible range (128 to pzero). Consider a kernel driver that has set up an interface card to perform a direct memory access (DMA) transfer between a data block on a disk and a physical address range in memory currently mapped to a thread's data space. If you were allowed to signal this thread to exit before the DMA completed, the kernel might attempt to return a physical page frame to the free list while the I/O interface was affecting its data transfer not a comforting thought! For such reasons, a sleeping thread may be placed at a priority below pzero to assure that the DMA transaction completes and the associated external interrupt is posted by the interface to the kernel I/O system to wake the sleeping thread (also called un-blocking the thread). When the thread wakes, the signal will be caught prior to the transition from the kernel space back to the user space, which in most cases results in the termination of the process and its threads. The kernel parameter pzero is the upper limit of the group, which delays signal delivery until wake up. Time Basics in HP-UX Scheduling: The Tick Time in HP-UX is measured by the kernel in terms of ticks. A tick is defined to be 10 ms. The CPU's hardware clock signal is monitored by a configurable counter circuit. The counter is set such that an internal processor interrupt occurs every 10 ms. This interrupt is handled by a kernel routine known as hardclock(). As a thread runs, the number of ticks that occur while it is running is stored in the thread's proc structure in the field p_ticks. This counter circuit is also the basis for the network time protocol service in which a system compares its time of day to that of another "server" system. Systems either are peers or belong to various strata; a system of lower strata will make fine adjustments to its counter interface to effectively speed up or slow down its tick. These adjustments are continually refined until the system at the lower time strata is synchronized with the higher level server. Time Slicing or Round-Robin Queuing When more than one thread exists in the same run queue, a round-robin scheduling scheme is usually observed. The kernel-tunable parameter timeslice determines the number of ticks a thread is allowed to run before being rethreaded to the end of its queue. The default value of timeslice is 10 ticks, or 100 ms. Each thread maintains a count of its remaining ticks until the next timeslice in kt_ticsleft (in its kthread structure). Every time the hard-clock interrupt occurs, the running thread on each processor has its kt_ticsleft decremented by 1 and compared to 0. If the thread's timeslice has expired, then the current thread has kt_ticsleft reset to timeslice, and it is moved from the front to the end of its run queue. In effect, threads of the same run queue take turns in a round-robin manner. If only one thread exists in a queue when its timeslice expires, it is simply rethreaded to the front of its own queue. The kernel realizes this is the case and stops short of actually performing a full context-switch operation and simply continues execution of the thread. The thread's kt_ticsleft is reset, and the countdown starts all over again in case new threads are added to the queue. Priority Decay, nice, and User-Level Priorities The HP-UX source code includes an interesting statement in the comments; it goes something like this: A thread's priority is adjusted according to a mystic formula handed down by kernel hack to seed as part of the oral UNIX tradition. We don't claim to be sage kernel hacks, but we would like to demystify this a bit. Each thread keeps a parameter in its kthread known as kt_cpu. In older UNIX incarnations there was something called the process hog factor. This newer, per-thread kt_cpu, to some degree, is a modern extension of that idea, although implemented in a somewhat different manner. The kt_cpu may range in value between 0 and 255 and is used whenever the kernel needs to reevaluate a thread's priority. Another factor in the recalculation of a thread's priority is its nice value. The nice value is a user-provided parameter and may be set either programmatically via a system call or by the user from the command line, using nice when the process is first launched or renice to adjust the value of a running process. The system assigns a default nice value of 20 to all processes; this value is stored in the kernel parameter pnice. The nice command has an overall range of 0 to 39. A regular user may only increase the nice value between 20 and 39, while a superuser may "nasty" that is, negative nice a process all the way to 0. Okay, so each thread has a nice value so what? Here is the way the nice value and the kt_cpu come into play. Periodically, the kernel stops to reevaluate the priority of all threads actively waiting to run on the system. This happens once a second, or every 100 ticks of the hardclock(). A kernel routine named statdaemon() calls schedcpu(), which calls its helper setpri(), which in turn calls calcusrpri() to assess and adjust user-level thread priorities. The basic formula looks something like this (remember that puser = 178 and pnice is 20): The new priority = (puser + kt_cpu/4) 2(pnice p_nice)
Upon examination of this pseudo-formula, we immediately see that if the thread's p_nice value is set to the default of 20, then the niceness has no effect on the calculation. The nice value is stored in a thread's proc table structure in the p_nice field. As a result when you nice a process, you nice all of its threads to the same level. The nice parameter predates the introduction of threads to the HP-UX kernel. Table 5-2 shows the contribution of the nice value to a thread's calculated priority: Table 5-2. nice Contribution to Priority Calculationsnice = | 0 | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 39 | Priority adjustment | -40 | -30 | -20 | -10 | 0 | 10 | 20 | 30 | 38 |
The contribution of kt_cpu may also be calculated; it is simply kt_cpu/4 and added to the base user-level priority puser (178). To complete our total understanding of this phenomena, we simply need to ask how kt_cpu is set. Simple, right? If only it were so. Enter the mystic formula! A thread's kt_cpu is adjusted at the whim of the kernel. When a process requests kernel services, I/O, systems calls, and so on, the requested kernel routine may adjust the requesting thread's kt_cpu depending upon its mood. Seriously, if a resource is currently in heavy demand, then kt_cpu may be increased. If there is average traffic, it may be left alone, or if the kernel notes light usage, it may reward the thread and reduce it. During the statdaemon(), waiting threads are checked to see if they are being starved for CPU time how long it has been since they had a turn as the running thread. If CPU utilization is low, this time should be very short; adjustments to kt_cpu may be made at this time as well. The kernel uses this as a means to avoid potential bottlenecks in various system resources. It is the sum total of the kernel's current activity level and the behavioral patterns of the thread which in the end determines how this parameter is set. Our story is not quite over yet. When these two factors have been assessed and totaled, they are limit-checked against the weakest priority (255) and the base of the user-level priorities puser (178) and adjusted within these bounds. There is another way that a thread's priority may decay: each time the total number of ticks a thread has used since it started is evenly divisible by 4, its current user-level priority is incremented by 1. This means that a user-level thread locked in a CPU loop would have its priority decay to the next weaker run queue after racking up 16 clock ticks (160 ms) assuming that it had started at the strongest priority in its run queue (remember there are four priorities per user-level run queue). When both mechanisms the "four ticks and you lose" and the once-a-second statdaemon() recalculation of all runnable thread priorities are combined, the basic personality of punishment and reward appears: if you are a CPU-intensive thread, you will be caught by many clock ticks and priority decay will move you out of the active queue. If you stop and ask the CPU to perform lots of I/O, your chances of being the running thread at the hard-clock interrupt is drastically reduced and you will be dealt with in a much gentler manner. There is another vague statement that bears repeating here: In general a thread will recover 90 percent of the priority points it has lost in four times the current percentage of CPU utilization, in seconds, once it has been pushed out of an active run queue. In other words, if the system is currently running at 80 percent CPU utilization, a thread that has suffered a loss of 10 priority points due to decay will recover 9 of them in 3.2 seconds. This is a very rough characterization but is surprisingly accurate. SCHED_NOAGE Now that you are beginning to see what priority decay is all about, let's introduce a relatively new kid on the block. The policy SCHED_NOAGE allows threads in the user-level run queues to be assigned a fixed timeshare priority. These threads are linked to the same run queue as other threads in SCHED_TIMESHARE and compete alongside them for system attention, but their priorities are not changed by any of the mechanisms we just discussed. This feature was originally introduced to support database operations. Prior to this option, you had to use one of the real-time policies if you wanted to have a fixed (or nondecaying) priority assigned to a process or its threads. SCHED_NOAGE offers a thread many of the same benefits as real-time run queues but without the inherent danger of a system hang which could result if a real-time thread behaves badly. SCHED_RTPRIO A number of years back, Hewlett-Packard decided to implement a real-time scheduling policy in addition to the classic timeshare scheme. Hewlett-Packard has a strong history in real-time computing, specifically with its HP-1000 family of computers running the proprietary Real Time Executive operating system on A-series minicomputers (referred to as RTE-A). These machines were used in manufacturing and process-control systems, and as HP-UX entered into this space and was determined to be Hewlett-Packard's strategic future path, real-time extensions to the HP-UX kernel had to be developed. Hewlett-Packard addressed this challenge with the introduction of the rtprio() system call and rtprio line-mode command in the HP-UX 7.0 release. In Figure 5-14, we see the relationship of this scheduler to the overall priority scheme. Figure 5-14. SCHED_RTPRIO 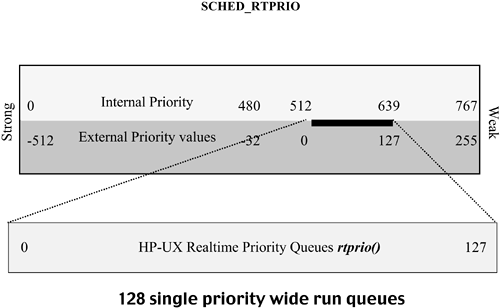
The real-time scheduler was named SCHED_RTPRIO and made use of the previously unused priority numbers 1 through 127. As Hewlett-Packard was writing its own rules at this point, the decision was to have a unique run queue for each priority number. These queues would use a round-robin scheme for threads in the same queue in the same manner as the SCHED_TIMESHARE scheduler and utilize the systemwide timeslice quantum value. As SCHED_RTPRIO run queues are stronger than the system-level queues when a real-time thread requests kernel services and needs to be put to sleep (possibly to wait on an I/O operation to complete), the sleeping kernel routine is promoted to the requesting thread's real-time priority. This allows the blocking routine's interrupt handler to respond at the stronger real-time priority when it is time to finish the request. Another advantage to real-time priority queues, at least from the kernel's viewpoint, is that they don't need to be considered by the statdaemon during the 100-tick priority readjustment cycle. Here is a hint: On a development system it is a good idea to always have at least one shell session running at a stronger real-time priority than the code being developed; if a real-time application becomes a runaway, the stronger shell could be used to send it a kill signal as long as the tty (keyboard) interrupt handler is also running at a stronger priority. Take a look on an HP-UX 11i system: what process runs at the absolute strongest priority? It should show a process named ttisr running at a priority of 32. On most systems this is the strongest configured POSIX real-time priority. This routine is the teletype interrupt service routine no matter what, we want to be able to have our keyboard input detected! Speaking of POSIX real-time priorities, they are next on our list. POSIX Real-Time Scheduler The last of the three main schedulers and the newest is the POSIX real-time scheduler, Figure 5-15 illustrates its position in the priority continuum. This scheduler features three different policies: SCHED_FIFO, SCHED_RR, and SCHED_RR2. Figure 5-15. SCHED_RTPRIO 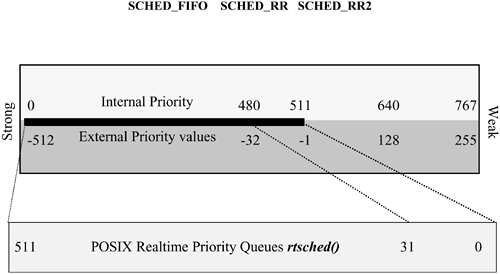
When the POSIX committee first approached the creation of a UNIX real-time scheduler specification, it requested several key features: The POSIX scheduler would feature up to 512 single-priority run queues. The number of queues would be configurable between 32 and 512. The weakest priority would be 1 and the strongest 512. Each thread assigned to a run queue would have a choice of three scheduling policies among other threads with which it shared a queue: FIFO, RR, and RR2. The POSIX run queues would be systemwide and not tied to a specific processor. When a POSIX queue had an active, runnable thread and it was the strongest queue, it would schedule the thread to run on the first available processor (unless the thread itself had expressed a specific processor affinity).
The implementation of these design goals presented its own set of challenges, as we previously mentioned. To understand how these features have been implemented in the HP-UX kernel, let's break them down. Sizing the POSIX Queues The sizing of the POSIX queue is controlled by a tunable kernel parameter, rtsched_numpri. The minimum supported value is RTSCHED_NUMPRI_FLOOR, or 32, and the maximum is RTSCHED_NUMPRI_CEILING, or 512 . Most systems simply leave this parameter at its default value of 32. Once this count is set, the kernel builds the POSIX run queues. The POSIX run queue is considered to be global, but it should be noted that on large systems with multiple processor sets (psets), there is a unique POSIX run queue created for each pset. SCHED_FIFO This policy schedules threads in a queue strictly according to time, when they were placed into the queue. First-in, first-out is the name of the game here. Once a thread gets the CPU, it keeps it until it requests a system call resulting in its blocking (being placed or a sleep queue) or until a thread of stronger priority preempts it. When a running thread is preempted, it is placed at the head of its queue. If it blocks on a system call upon wakeup, it is placed at the end of its queue. SCHED_RR The SCHED_RR, or round-robin queuing policy, uses the system's timeslice quantum and moves a thread to the end of its queue when its timeslice expires. If a thread operating under this policy is preempted, it resumes operation at the head of its queue. SCHED_RR2 This policy represents a round-robin scheduler with the difference that the timeslice may be adjusted differently for each queue at least that was the intention. Current implementation allows this policy to be selected, but there is no kernel code to implement the per-queue timeslice quantum value; it simply uses the system timeslice quantum value. In effect, SCHED-RR and SCHED_RR2 both function in an identical manner. Some general housekeeping items need to be mentioned at this time. With the introduction of the POSIX real-time extension came the rtsched() system call and the command-line rtsched. This call, just like the rtprio() call, requires privileged group capabilities in order to be used (see set_priv_grp and get_priv_grp commands in the manual pages). To make things a bit easier, the rtsched call may be passed any of the valid scheduling policy names as an argument, and it will implement the requested policy. The timeslice value kernel parameter may be set to 0, in which case the default value of 10 ticks is used, or the desired number of ticks may be set (use caution: in most cases this parameter should not be set lower than 5 or greater than 30 these are both extreme cases). Another interesting option is to set timeslice to 1; this will effectively turn round-robin scheduling off for the system. Again, we don't recommend this for most configurations. |