The exit() System Call Mechanics When a thread makes an exit() system call, it is asking to be removed from its run queue and to have its cumulative resources returned to the kernel for dispersal to their appropriate free lists and arenas (Figure 9-9). As we mentioned earlier, when any thread of a multithreaded process calls exit(), all of its threads are halted and removed from kernel tables and structures. Figure 9-9. The exit() 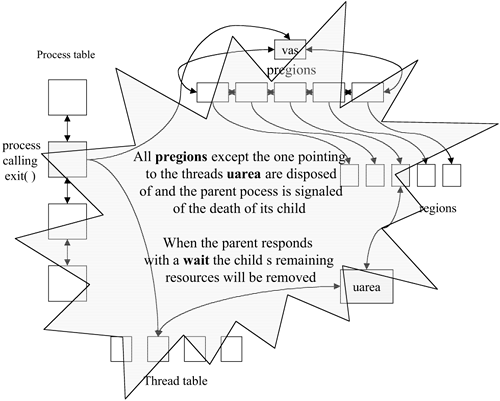
Actually, there are two variations of the exit call, the original exit() and __exit(). When a programmer codes a call to exit(), an additional call is made to atexit(). The idea is that the programmer may wish to have specific functions performed as part of the exit procedure (i.e., some standard I/O library routines require a final "flush" of buffers to avoid data loss when a program terminates). Since an exit() may be called on behalf of a thread by the kernel (as the result of a fault or signal) or at the request of another process (by the kill command or system call), a programmer may need to schedule cleanup actions as part of the program's exit logic. This feature is embedded into the basic exit() call. There are some conditions in which these cleanup actions may not be desired or in fact may cause problems. When is an executing thread not running in its own run environment? During a vfork(). If a child of a vfork calls exit() while it is still running in the parent context, then any scheduled cleanup actions are actually modifying the parent environment. Once the child completes its exit, the parent may wake to find that its context has been corrupted. For this reason and others, the __exit() call was created. This call bypasses the call to atexit(). It proceeds directly to exit, does not pass atexit, and does not collect $200! In the kernel both calls are handled by exit1(). Walk, Don't Run, to the exit1() Nearest You As part of the kernel mechanics, when a thread calls exit() or __exit(), or when a fault results in the kernel scheduling exit() on behalf of a thread, a sequence of events takes place involving the kernel, the exiting process, and the parent process. In the case of a multithreaded process, all sibling threads are immediately halted, and in all cases deconstruction of the process's resources is begun. A write lock is obtained for the process (we don't want two siblings attempting to exit at the same time). We set p_flag=SWEXIT, ignore all signals, release semaphores, cancel pending callouts, and release our virtual memory regions (provided we are the last active process to reference them; for shared regions, it is a case of "last one out turns off the lights"). We close all open file descriptors, perform any requested Sys-V semaphore undos, and destroy any adopted processes. If the exiting process has children, we turn them over to init and send a SIGCHLD to init if there are any newly adopted zombies waiting for the reaper. Finally, the kthread and proc structures are removed from their active lists. All kernel structures are released with the exception of the proc, calling kthread, vas, and one remaining uarea, region, and pregion. The state in the proc and kthread structures are set to p_stat=SZOMB and kt_stat=TSZOMB respectively. A special case exists when the thread calling exit is a first-generation result of a vfork() call. In this case (indicated by the proc structure p_flag = SVFORK), we set vfork_state=VFORK_CHILDEXIT in the vforkinfo buffer. The kernel deconstructs the child and wakes the parent. When the kernel next schedules the parent thread to run, the context switch, swtch(), calls resume() to restore the thread's save state. In the case of vfork_state=VFORK_CHILDEXIT, the save state comes from the vforkinfo buffer. The buffer is released, any sibling threads that were suspended during the vfork are placed back on their run queues, and the parent thread continues. Night of the Zombies: Responsible Parenting At this point, the kernel notifies the parent process (as indicated in the exiting process's p_ppid field) of the death of its child. This is accomplished by sending a signal to the parent process. The actual signal is called SIGCHLD. It is the responsibility of the parent process to respond to this signal using one of several system calls. The calls fall into the generic label of wait and consist of four variations, although once we get past the system call interface, they are all processed by the same kernel procedure, wait1(). The four user-callable versions of wait are as follows: wait(*stat_loc): This is the classic wait call and suspends the calling thread until status information about one of its terminated or stopped children may be returned. If there is a waiting zombie when the call is made, it returns immediately. wait3(*stat_loc, options, *resource_usage): This call allows the requesting thread to be specific about which child process it wishes to receive status information about. In addition, there are three optional flags that may be passed: WUNTRACED to receive status information about children that have stopped due to a signal receipt WNOHANG, which keeps the calling thread from suspending if no child status is available WNOWAIT, which causes the request to not be registered and allows a later wait to be requested against the same child if used in conjunction with WNOHANG when the child is not ready to exit
waitid(idtype, id,*infop, options): This call is used if the parent wants to wait for a child to simply change state. Three focus options are allowed by passing the appropriate idtype argument: P_PID to specify a specific process ID P_PGID to specify any process within a specific process group P_ALL to wait for any of its children
In addition, the following options may be specified: WEXITED to wait only for children that have exited WSTOPPED to wait for a stopped child WCONTINUED to wait for a child to continue WNOHANG and WNOWAIT which function the same as in the wait3 call
waitpid(pid, *stat_loc, options): This version functions the same as the wait call if the passed pid=-1. If pid>0, then the call is for a specific child. If pid<-1, then the call is for any child whose process group is equal to pid x -1 (absolute value). The options available are similar to those in the wait3 call.
In all four wait variations, version control is passed by the system call interface to the kernel routine wait1(), where the real work is done. First, a search is made for zombie children. If they are found, their status is passed back to the caller and the zombie is laid to rest. This is called reaping a thread. Stopped, traced, and continued children may also be looked for depending on the actual call specifics. Before wait1() may modify any of the child resources, a lock must be acquired to make sure that the thread is being reaped only in response to a single request. The kernel also reaps any adopted zombies that may be queued for its attention. The Grim Reaper Pays a Visit When the kernel reaps a kthread with kt_stat=SZOMB, the thread's final resource usage statistics are added to its process, and it is laid to rest with a call to kissofdeath(). The reaped kthread structure is placed on the freekthread_list. Next, the process itself is reaped in a similar manner. Its resource usage statistics are added to the process that called the wait, and the proc structure is placed on the freeproc_list. A call to abandonchild() removes it from the parent's list of children. (Don't you just love this stuff? I mean, what a violent piece of code. We have daemons, zombies, kill processes, death-of-child signals, abandoned children, and calls for the kiss of death. UNIX internals is not for the fainthearted!) It should be noted that a parent process may choose to ignore the SIGCHLD signal. In this case, its children remain in the SZOMB state. While a zombie has freed most of its system resources, it does occupy a place in the process and thread tables. If the parent aborts without issuing the necessary wait, the children are frozen in the zombie state indefinitely basically until the system is rebooted, as only the parent of record may issue a wait for a zombie child. Another possibility is that the parent process may exit or abort before its children. In this case, HP-UX tries to solve the potential problem by reassigning the parent process ID of the orphaned child to the patron of all processes, init. The init process periodically issues a waitid("P_ALL"...) to clean up any adopted zombies. This approach has reduced the number of inadvertent zombies on a system to minimum. The limiting factor is that the "adoption" is only performed if a child calling exit passes the kernel an invalid parent ID number. If a parent process is blocking an attempted death-of-child signal and aborts without handling it, the child will remain a zombie. Responsible parents always clean up after their children or at least pass the responsibility on to another! |