1.2 What does mission critical mean?
The term mission critical is overused in our world today. As such, we should pause and relate the term to our specific scenario and context.
Mission critical: A term applied to various systems on which the success of an organization or project depends. The loss of a mission-critical system results in unacceptable operational, functional, or financial harm to the organization or project.
It should be noted upfront that the term mission critical need not apply specifically or solely to large systems or even large Exchange deployments. Certainly, larger deployments in larger organizations may have millions of dollars of revenue per day riding on the availability of their messaging and knowledge-management systems. However, in the eyes of a small/midsize business owner or IT manager, a small deployment of 50 users may be equally important to his existence. Moreover, since a large portion of the total deployed Exchange servers in the market resides in small/midsize businesses, we must not limit our discussions or focus to include only large deployments. Mission critical refers not to the size of our messaging system, but to the importance of our data and the medium itself. Therefore, even small and midsize companies can have a need for and deploy mission-critical Exchange servers. It is not the size that matters—both large and small Exchange deployments need the tools, concepts, and methods I will discuss throughout this book.
Planning and implementing mission-critical systems is like buying insurance for your home or car. We accept the fact that, at some point along the road, something may happen, and we will have to file a claim. It does not pay to have an it-won’t-happen-to-me attitude. We select our insurance vendor in terms of price and service, but also in terms of our confidence that we will be without our home or vehicle for a minimal amount of time. As part of this insurance-selection process, we also look for a policy that will protect us from liability. Maybe if downtime were treated more seriously and made more of a business requirement, we would do a better job of setting service-level requirements and putting plans in place to meet them. Unfortunately, not all organizations treat disaster recovery and high availability planning as a business requirement.
Many see downtime and outages for their Exchange servers as something that will most likely happen to the other guy. The other problem is that, in order to do it right for any environment, you must have qualified staff and lots of money. In a study by the Gartner Group, only about 20% of companies running Web-based e-commerce sites have proactive reliability plans in place. In 1998, a similar study by IBM Recovery Services showed that number to be only about 8% or less. This illustrates to me how businesses have generally neglected the whole process of ensuring mission-critical environments. Perhaps because many organizations are so resource constrained because it is a very resource-intensive and time-consuming process.
As we endeavor to travel down the path of building mission-critical Exchange Server deployments, we must inevitably begin by defining exactly what is meant by mission critical. We must also clearly define sometimes overused terms such as availability and reliability in that same vein. We also need to identify the key topics and goals related to disaster-recovery planning and implementation within the context of messaging systems so that administrators, planners, and implementers of Microsoft Exchange Server environments will know what they are up against. Since any enterprise wide distributed application, including Exchange Server, can be perceived as mission critical, we need first to qualify and quantify which assets are mission critical and then establish the reasons, objectives, and steps for disaster-recovery planning exercises. In this chapter, I will look at what is meant by mission critical and its various facets applied to an Exchange
Server deployment. Next, we will discuss how to evaluate the risks in your Exchange Server environment. This risk-assessment process for your Exchange Server environment will serve as a valuable precursor in determining your availability requirements for your Exchange Server deployment. Finally, we will look at defining Service-Level Agreements (SLAs) for availability in an Exchange environment.
1.2.1 Taking Windows seriously
In postulating and strategizing my approach to the problem of deploying mission-critical Exchange servers, one foundational thought that should not be overlooked occurred to me. Are we taking Windows Server deployments seriously? Stay with me here. Prior to my present life in the world according to Microsoft, my base of experience was in the oddly married Digital VMS and Novell NetWare environment. Prior to that, I had a brief stint (although I don’t usually admit it) in the IBM AS/400 environment. So the thought occurred to me: What if Exchange Server ran on the OS/ 400 or VMS operating system in the world of minicomputers and mainframes? In my associations with these environments, years of experience and learning from mistakes had gone before me. In other words, disaster recovery, reliability, management, and other proven techniques for guaranteeing system availability were taken for granted or gospel (whether they followed them out of fear or because they had to) in the mainframe or minicomputer world. The procedures and practices have been practiced and honed to razor-sharp perfection over the last 20-plus years that these systems have been used in line-of-business computing activities.
Organizations have run their businesses on these systems for years and have invested in order to deliver the promise that they will be up and running when they need them. Microsoft Windows operating systems for mission-critical line of-business computing is a relatively new paradigm. This goes back to my question regarding the level of reverence we give to ensuring that these systems are available for the business-critical computing tasks we give them. Messaging and collaboration applications are not free from these requirements. Table 1.1 illustrates how the outages of certain types of business-critical processes and activities can cost organizations substantial amounts of money. Additionally, Contingency Planning Research’s most recent (2001) Cost of Downtime study reveals the following summary conclusions:
-
46% of companies surveyed said each hour of downtime would cost their companies up to $50,000.
-
28% said each hour would cost between $51,000 and $250,000.
-
18% said each hour would cost between $251,000 and $1 million.
-
8% said it would cost their companies more than $1 million per hour.
Table 1.1: The Cost of Downtime Typical Cost of Downtime by Business Type-Business Activity
Average Hourly Cost of Downtime
E-commerce/brokerage site
$6,400,000
Credit card transactions
$2,600,000
Catalog sales
$90,000
Package shipping and transport
$28,000
Source: Contingency Planning Research, Inc., 1998, http://www.contingencyplanningresearch.com.
The other factor in this equation is hardware. Are we still treating our mission-critical server’s hardware running Windows Server as PCs?
Thirteen years ago, Compaq introduced the first “server” called the Systempro. Until that time, desktop computers were simply turned on their side and put into the data center as servers running operating systems such as Novell NetWare or Banyan Vines and were used for file- and application-sharing tasks, most of which were not that mission critical. With the advent of the PC server, we were not really sure what to do with these devices. They were the same as our desktop computers (although some, like the Compaq Systempro, even had multiple processors), but also different. Being part of that revolution, I remember struggling with my desktop PC being used as a server and being frustrated with the fact that many of the taken-for-granted luxuries of the minicomputer environment were nowhere to be found there. At the time, there was no such thing as RAID disk arrays or redundant power supplies for my little NetWare fileserver. In addition, major availability technologies such as VAX/VMS Clusters and Compaq (HP) NonStop Himalaya (both of which I think are really cool.) were nowhere to be found in my somewhat limited PC server world. As far as disaster recovery, most Windows administrators and system operators have been left to figure this out on their own. I have many repressed memories of being paged at 10 P.M. by the help desk to let me know that my fileserver had crashed and then spending the entire night trying to figure out how to get it back up. At the time, tape drives and disaster recovery-software were just becoming available for the PC server world. In the meantime, my friends back in the “glass house” found it humorous that I had crossed over into the dark side-only to find nothing but virgin territory when it came to building mission-critical systems.
My point here is that PC-based servers and operating systems like Novell’s NetWare and Microsoft’s Windows are, in relative terms, infants to the world of mission-critical line-of-business computing. The challenge we face for deploying mission-critical Exchange servers lies in understanding this issue and discovering how we can take tried and proven technologies for increasing system reliability and uptime and apply them to Exchange Server deployments that are mission critical in nature. As more and more business processes are moved to this environment and as new technologies for leveraging Exchange Server are discovered, defined, and deployed, this issue will have to be addressed. Maybe the very thing preventing operating systems like Windows from enterprise-level acceptance is our failure to take them seriously.
1.2.2 An information vacuum
All of this has left a terrible, deep-down groaning in the bellies of Exchange Server administrators and implementers everywhere. Even Microsoft’s own documentation for Exchange Server disaster recovery and reliability has been somewhat lacking in the past. In fact, it wasn’t until recently (Exchange 5.5) that Microsoft recognized that customers were in dire need of such assistance. Since then, Microsoft has been valiantly adding to the body of information available on this subject. Microsoft has begun to provide additional tools such as books, white papers, utilities, and additional Microsoft Authorized Training and Education Center (ATEC) courses targeted to meeting the growing need for knowledge for administrators and implementers. Microsoft’s Microsoft Operations Framework (MOF) initiative was also derived from this requirement. Microsoft has also recognized the need to work more closely with hardware vendors such as HP, Dell, IBM, EMC, Network Appliance, and so forth.
With the Exchange 2000 release, a major design goal was to address this key area of concern—reliability. The Exchange 2000 release contains many improvements in storage management, backup and restore, clustering, and administration and management that will help organizations deploy mission-critical Exchange servers. Exchange Server 2003 further builds on these reliability improvements and seeks to raise the bar of Exchange deployment reliability. Also, despite the fact that we will look deeply into
Exchange Server in this book and illustrate some weaknesses or identify potential areas for reliability improvements, most research indicates that Exchange still compares well with other messaging systems in terms of reliability (as shown in Table 1.2).
| Microsoft Exchange Server | Lotus Domino | |
|---|---|---|
| Total downtime per year (hours) | 27.2 | 75.2 |
| Operation hours (yearly) | 8,760 | 8,760 |
| Availability (uptime) | 99.7% | 99.1% |
| Source: Creative Networks, Inc., 1998. | ||
Hardware manufacturers also recognize the tremendous opportunity to leverage their technology to improve Exchange Server reliability. With so much attention on the need to make Exchange deployments more bulletproof, these vendors have targeted storage and backup solutions directly at filling this void. As organizations look to increase uptime for Exchange, they are also looking to their hardware and integration partners to assist them. In fact, in my previous work at Compaq (HP), I worked under the assumption that my customers would select their hardware vendor for Exchange based largely on the solutions, services, and deployment expertise for Exchange brought to the table by the vendor —not on the hardware by itself.
Service vendors have jumped on the Exchange high-availability bandwagon as well. HP Services (formerly Compaq Services) is the largest Exchange services provider with millions of Exchange users under deployment contract. In that extensive experience, the tremendous need for Exchange reliability has also been recognized. Illustrating this point, the top Exchange service providers, like HP, IBM Global Services, EDS, and others, have begun to offer services such as disaster-recovery and high-availability assessments to their Exchange customers. These services are designed to assess and identify the areas of vulnerability of a particular Exchange deployment and to assist the customer in assessing risks, developing plans, leveraging technology, defining SLAs, and the many other tasks that go into designing mission-critical deployments for Exchange Server.
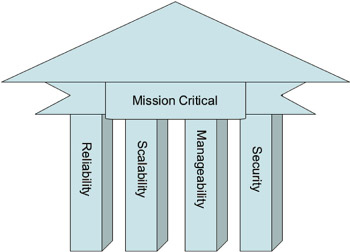
Figure 1.1: The four pillars of a mission-critical system.
EAN: 2147483647
Pages: 91