Chapter 4: When Exchange Servers Fall Down
If you recall my earlier discussion of the black box of downtime, I was very adamant about pointing out that downtime is not a singular event, but a series of individual outage components. My main emphasis was to point out that, by identifying and evaluating each individual component of a downtime occurrence, we can look for ways to reduce the overall duration of a downtime event. By looking inside each outage point, we may be able to find possible areas of process improvement that will substantially reduce or even eliminate periods that are unnecessary or too lengthy. In Chapter 2, I identified seven points or components of a typical outage. These were prefailure errors, the failure point, the notification point, the decision point, the recovery action point, the postrecovery point, and the normal operational point. Within each of these components of downtime we can find many subcomponents in which we may be able to find errors or oversights that, once addressed, can be substantially reduced or eliminated.
It is the recovery action point that we will focus on in this chapter. I believe that this component of downtime is responsible for the majority of the “chargeable” time within a downtime event. For example, I have seen many organizations rack up hours and hours of downtime simply because they did not have (or could not find) a good backup or because they interfered with Exchange Server’s own recovery measures. I believe that lack of knowledge and poor operational procedures can create vast amounts of unnecessary downtime for an Exchange deployment. Therefore, I will gear this chapter toward a focus on Exchange disaster-recovery technology for the specific purpose of reducing the amount of time an operations staff spends recovering an Exchange server. An understanding of what types of failures can occur, as well as the scenarios in which disaster recovery will be performed, is the first step. We must also understand operationally how the Exchange database engine recovers itself. Next we must understand the process flow of how Exchange 2000/2003 performs backup and restore operations, as well the types of backup techniques that are available. This is followed by a look at overall best practices, tips, and methods of disaster recovery-process improvement. I will also take a brief look at some of the third-party backup applications and hardware products available for Exchange and the similarities and differences in their approaches. Finally, we will bring it all back together by discussing some sample scenarios that implement the practices and techniques we have discussed. My hope is that this chapter on Exchange disaster-recovery technology will provide you with meaningful insight into the recovery action point of the black box of downtime for Exchange Server and will help you identify methods for improving your processes—thereby reducing the amount of time spent recovering Exchange.
4.1 How can an Exchange server fail?
There are basically two scenarios under which we engage in disaster-recovery planning, testing, and operations. The first scenario is a server catastrophe. In this situation, your Exchange server has been completely lost due to some disaster incident such as fire, flood, earthquake, and so forth. This catastrophe requires that you completely recover your Exchange server from scratch. In this situation, you must concern yourself with the operating system (Windows Server), Exchange Server, and the information stores. For Exchange 2000/2003, we have two additional components—the Active Directory (AD) and the Internet Information Server (IIS) Metabase. In most situations, I do not anticipate that Exchange administrators and operators will be responsible for disaster recovery planning for the Active Directory. However, since the AD is really just JET/ESE “lite,” Exchange gurus may be called upon to assist infrastructure staff (whom I would typically expect to own the AD) with backup, restore, and maintenance planning for the Windows 2000 AD. Don’t write the AD off, however, as you will need to understand how AD recovery operations on an Exchange server should be performed. Whether you rely on the infrastructure staff or not, factoring the AD into Exchange Server disaster-recovery plans is a must. In most cases, however, I only expect AD recovery to be a factor in Exchange 2000/ 2003 Server recovery if your Exchange server was acting as a Windows 2000/2003 Domain Controller (DC) or Global Catalog (GC) server. This is a practice I would discourage if at all possible. Just ensure that you understand whether the AD is a factor during recovery of your Exchange servers. Most likely, you will find that a careful understanding of how Exchange databases rely on the AD is required for complete recovery.
The IIS Metabase is another important piece that is new to Exchange 2000/2003 disaster-recovery planning. The IIS Metabase is part of the IIS that stores static configuration information for protocols and virtual servers. Exchange 2000/2003, for example, will store information about the protocols it uses and the SMTP or other virtual servers that are configured for Exchange within IIS. Since IIS is now such an integral part of Exchange 2000, planning for IIS Metabase recovery is a vital component of disaster recovery that we did not have to worry about with previous versions of Exchange (since they did not depend on IIS). The final part of complete recovery for an Exchange 2000 server is the information stores. This involves one or more storage groups and any databases configured in those storage groups. Recovering a complete Exchange 2000/2003 server leaves us with many things to think about.
The second scenario we plan for is recovery of the Exchange information store or its components. For Exchange 2000 and beyond, the term information store expanded in scope. In previous versions of Exchange, the information store simply included the public (PUB.EDB) and private (PRIV.EDB) information stores. Recovery of these two databases is not trivial, but it pales in comparison with the possible recovery complexities presented in Exchange 2000/2003. Since Exchange 2000/2003 provides for multiple storage groups and allows you to configure multiple databases per SG, we now have much more to consider when planning for disaster recovery of an Exchange 2000 deployment. Our plans must include the ability to recover all storage groups and databases, an individual storage group, an individual database (MDB), one mailbox, or even a single message or document. Table 4.1 highlights the two basic recovery scenarios we face for Exchange 2000/2003 and the factors and considerations for each.
| Recovery Scenario | Components | Considerations |
|---|---|---|
| Complete Exchange Server recovery |
|
|
| Information store recovery |
|
|
4.1.1 Information store failures
Before moving further into how recovery operations work for Exchange Server, let’s pause to discuss the types of failures of the information stores in Exchange that may require us to perform these operations. While Exchange Server is a continuously operational system that does not require that the system be taken down, there are some failures that will require the system to shift into a recovery mode of operation. The Exchange information store is the focus of our discussion. There are two basic types of failures that cause the information store to need recovery—physical and logical corruption.
Physical database corruption
Once Exchange passes data to the operating system (Windows 2000/2003), it relies on the operating system, device drivers, and hardware to ensure that data is preserved. However, these lower layers do not always provide flawless protection of the data. Physical corruption to the Exchange database is the most severe form of failure you can experience, because you are not able to repair the data, and it must be recovered using your established disasterrecovery measures such as restoring from tape backup. Physical corruption to the database can occur in several areas such as an internal page, index, database header, leaf (data) pages, or the database catalog (Exchange has two copies per database). If given a choice, I would prefer corruption of a secondary index or internal page. The reason for this preference is that corruption is limited in these circumstances, and the data itself is usually safe. Because of the seriousness of physical corruption, it is very important that these errors are detected and corrected as early as possible.
The infamous –1018 error
Most often, physical corruption for Exchange databases is announced by the occurrence of a –1018 (negative 1018) error. When Exchange Server detects a physical corruption, the error is logged to the application log in Windows 2000/2003. Most often, these errors are encountered during online backup or database maintenance. This is due to the fact that the database engine checks every database page during these operations. As I described in Chapter 3, each 4-KB database page contains a header with information about the page. Within the header, both the page number and a checksum or Cyclic Redundancy Check (CRC) are stored. When the database engine reads a database page, it first ensures that the page number it requested is the one returned by checking the page number in the header. Next, the CRC is validated. If either an invalid page number was returned or the CRC failed, the database engine will report an error. In previous versions of Exchange Server, the database engine would simply log a –1018 error to the application log and continue on. However, ever since Exchange Server 5.5 Service Pack 2 (SP2) (and, by inheritance, in Exchange 2000/ 2003), ESE will attempt a retry of the page in question. ESE will attempt to reread and check the database page up to 16 times before declaring the page corrupt and logging the error (a good indication that your disk subsystem has a problem). In the event that this occurs, 200/201 series errors will be logged to the application log, indicating either that the database engine encountered a bad page, but retried successfully, or that it retried 16 times without success and the database must be recovered. If this occurs during on-line backup, the operation will be terminated. This ensures that a physically corrupted database is not backed up.
The best method of which I am aware for preventing database corruption is to deploy Exchange Server on solid hardware configurations and to practice proactive management of your Exchange deployment (stay tuned for Chapter 10). In my experience, however, not all occurrences of physical corruption are caused by hardware (contrary to what Microsoft Product Support Services may tell you). In fact, up until Exchange 5.5 SP2, Exchange itself was a potential source of corruption. This was particularly true in earlier versions, such as Exchange 4.0 and 5.0. However, Microsoft has done a significant amount of work and has collaborated with hardware vendors like HP and Dell to understand and reduce the occurrence of physical corruption. The retry instrumentation code (where ESE retries up to 16 times) was added in Exchange 5.5 SP2 and has significantly impacted the occurrence of –1018 errors by allowing the database engine to retry Read operations. This ensures that the error was not caused by a transient condition, busy disk subsystem, or other benign condition. In my recent experience with Exchange 2000 Server, most database corruptions are, indeed, rooted in some type of hardware problem (faulty hardware, bad cabling or termination, firmware issues, connections, controllers, and so forth). This means that Microsoft has taken these errors seriously and attempted to provide as much protection against them as possible. The downside is that hardware will continue to fail since physics is stronger than our desire for hardware to function perfectly.
Deploying rock-solid hardware does help, however. Implementing hardware-based RAID and ensuring that your hardware vendor of choice meets some basic criteria is important. Make sure your hardware vendor meets some basics, such as the Microsoft Hardware Compatibility List (HCL). Your hardware vendor should at least be in the top tier of server vendors, such as Hewlett-Packard, IBM, or Dell. Also, your vendor should have some basic experience with Exchange Server. A good consulting practice focused on Exchange, or industry experts who know Exchange and the hardware, are good indicators of a hardware vendor you can count on. Also, hardware vendors frequently update their code in the form of drivers and firmware (ROMs) for servers and devices such as disk drives and controllers. Make sure you are following your vendor’s recommendation about keeping up to date with the latest versions; this includes bug fixes and enhancements that address issues that could potentially cause corruption of your Exchange databases. I can’t tell you how often I hear of Exchange downtime that is charged against the hardware when the fix in the form of an updated device driver or ROM was available from the hardware vendor. So often, these updates are not applied, and the result is disastrous. I will defer my harping on this subject to later discussions on configuration, change, and patch management in a later chapter. However, this is a key point in reducing physical corruption in Exchange databases as a result of hardware problems.
The question of write-back caching
Another question that frequently surfaces in the area of Exchange database corruption and hardware is the issue of write-back caching. Write-back caching is a tremendous aid to performance because it reduces the amount of time it takes to return a write completion status to the operating system, thereby improving application performance (as shown in Figure 4.1). Rather than waiting until each write I/O has been written to disk, the write-back cache accepts the data to cache and informs the system that the write has been completed.
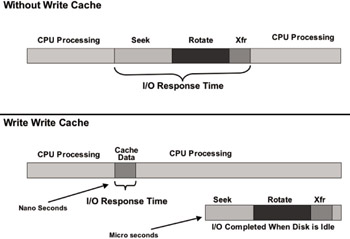
Figure 4.1: The impacts of write-back caching on disk I/O operations.
Write-back caching comes in two forms. First, disk drives have individual-write-back caches located on the disk drive that can improve the performance of write operations. These caches are very dangerous since there is no protection or battery backup for cache memory located on the individual disk drive. Although drive vendors make this available (mostly for benchmarking and performance reasons), most server vendors I am aware of will turn write-back caching off at the individual disk drive level. If you are in doubt, ask your server vendor about whether it disables write-back caching at the drive level.
The second implementation of write-back caching is at the controller level. Many vendors have hardware-based RAID controllers with large amounts of write-back cache. These caches typically vary in size anywhere from 4 MB to 16 GB. In the extreme case of a cache as large as 16 GB, you can see how important it is to have the cache protected. If the power or cache memory should fail, you could easily have megabytes of unwritten data in the cache lost. Most of the leading server vendors do provide protection for their caching RAID controllers. Of the third-party RAID controllers available, some provide protection, while others do not.
If in doubt, you should ensure that the controller you purchase for your Exchange servers meets the following three criteria points (summarized in Table 4.2). First, the cache must be protected by battery backup so that, in the event of power failure, data in the cache is preserved. Next, the cache memory should also be protected. This means that the memory used for the cache implements Error Checking and Correction (ECC) or some other form of protection such as RAID RAM configurations. With RAID cache RAM, the memory banks are arranged in a fashion that implements protection in the form of mirroring (RAID1) or distributed parity (RAID5). One final criterion is necessity that controller cache be removable. This is most important during a controller failure. In the event of a controller failure, if the cache is not removable, there is no means by which to recover any data currently in the cache. Furthermore, since the cache must be removable, the batteries must be movable along with the cache. This is best implemented with a cache memory daughtercard. A cache daughtercard provides a means for the cache memory and batteries to be part of the same assembly. When the controller fails, the cache daughtercard is simply removed and plugged into a replacement controller. Once the system is restored to operation, any data that was stored in the cache can be flushed to disk, thereby completing any outstanding write operations. In many high-end disk enclosures, the cache module and battery are actually implemented as a single module that plugs into the controller. It is very important that your caching RAID controller meet these minimum criteria. Other desirable controller features include the ability to configure the cache as read-ahead versus write-back and the ability to disable caching on a per-logical-drive basis. Once these criteria are met, you can safely deploy Exchange Server configured with write-back caching enabled.
| Controller Attribute | Description |
|---|---|
| Battery backup | The controller includes onboard batteries that maintain cache information in the event of a power failure |
| Protected cache memory | The cache memory is configured with protection schemes such as mirroring or RAID parity and provides protection in the event of memory-component failure |
| Removable cache module | The controller cache is contained on a pluggable card or module that is separate from the base controller. This allows the cache to be transferred to another controller in the event of controller failure. Note: The battery backup must be attached to the cache module in order to prevent data loss in the event of a base controller failure |
Contrary to much misinformation, there has been no documented correlation between Exchange database corruption and write-back caching at the controller level. In the early days of Microsoft Exchange Server (circa 1996– 1998), several incorrect or misleading Microsoft Knowledge Base (KB) or “Q” articles were written that incorrectly advised turning off write-back caching for Exchange Server. This error was due to the subtle differences between write-back caching at the disk drive level versus the controller level. Since most hardware manufacturers disable write-back caching at the disk drive level, the disk drive–level caching issue is moot. However, at the controller level, if the preceding criterion has been met, it is completely safe to deploy servers with write-back caching enabled for Exchange information store volumes. This is the best practice from a performance point of view as well. RAID5, in particular, will suffer huge performance penalties if writeback caching is disabled due to the overhead of the intense XOR computations required. However, performance will suffer for any RAID level when write-back caching has been disabled. The bottom line is this: Ensure that your RAID controller meets the three criteria I discussed. If it does, enable write-back caching (I recommend setting the controller cache for 100% write) and enjoy the performance gains for which it was designed without fear of physical corruption of your Exchange databases.
When physical corruption of an Exchange database is encountered, your options for recovery and restoration are limited. There are not many options for repair of a physically corrupted database. You can use the ESEUTIL utility that comes with Exchange. However, this method technically does not repair corruption in the database. ESEUTIL essentially just identifies the bad page or pages and deletes them from the database. My recommendation is that you avoid using ESEUTIL in the event of database corruption (or strictly as a last resort). ESEUTIL does have a repair mode of operation (ESEUTIL /P) that allows the database engine to delete corrupted pages, but the result is just an operational server with missing data. The result is loss of user data or, in worse cases, the introduction of logical corruption. The only way to recover from physical corruption of an Exchange database is to restore from backup or use another disaster-recovery measure. If you are able to restore the database to the last known good state (if your last backup operation completed successfully without errors, you can be assured it is good), you can then allow Exchange to perform recovery by playing through transaction log files and bringing the database to a consistent state. If you continually find your databases in a corrupted state, thorough hardware diagnostics will be necessary since the cause of corruption may likely be hardware related.
Logical database corruption
Logical corruption of your Exchange server database is problematic and is much more difficult to diagnose and repair than physical corruption. This is because logical corruption can be hard to identify and is often caused by problems in software (even Exchange itself ) or the operating system. With logical corruption, the user and administrator are typically unaware of an occurrence. To make matters worse, Exchange contains no built-in checking (like that available for physical corruption) to diagnose and alert you to logical database corruption. In addition, there are no specific symptoms that are identifiers of logical corruption. Usually, when an administrator is alerted to logical corruption, it may be too late for repair.
As previously mentioned, physical corruption may also cause logical corruption. Let me give you an example of this. Suppose a database page has become corrupt for whatever reason. In many cases, this page may just contain user data, and that data is simply lost. However, the rest of the database and its structure remain intact. Suppose, however, that the problem page contains B-Tree structure data or index information for the database. The loss of this page could render the entire database unusable since key structural information for the database has been lost. Logical corruption may manifest itself in other situations as well. Suppose, in another example, that a bug in the Exchange database engine incorrectly links tables contained within the database. The linkage between the many different tables contained in the information store and the indexes used is the key to storing semistructured data in Exchange in the fastest and most efficient manner. Logical corruption can render the entire dataset useless. If you encounter logical corruption (you may not recognize it as such), your troubleshooting skills will be quickly tested.
The saving grace here is that since Exchange 5.5, occurrences of logical corruption have virtually disappeared because the database engine has been continually refined and stabilized as various versions and service packs for Exchange have been rolled out. Also, in versions prior to 5.5, logical corruption could be introduced by replaying transaction logs incorrectly (such as in the wrong order or with a gap in the generational sequence). However, Exchange 2000 (and later versions) prevents this scenario by ensuring that the correct transaction logs exist before replay. While we have fewer statistics for Exchange 2000 and 2003, I expect this to continue to be the case. Because logical corruption is so unpredictable and sometimes invisible in nature, it is important to focus your attention toward preventing it. Ensure that you keep close tabs on new service packs and hot fixes that Microsoft releases that specifically address logical corruption issues that have been discovered (particularly in older versions of Exchange Server). Since logical corruption is potentially so serious, Microsoft is quick to address issues when they are found and escalated through the support channels. However, if you are unaware of these issues or fail to implement critical fixes, you may end up a victim of logical corruption. Another bright spot is the existence of tools that can repair logical corruption of Exchange databases.
Exchange information store tools
Since logical corruption may occur at either the information store level (tables, indexes, keys, links, and so forth), or the database level (B-Tree structures and so forth), we must have tools that address each of these levels. The ISINTEG utility looks at the information store to check potential logical corruption at this level. ESEUTIL, on the other hand, checks, diagnoses, and repairs problems at the database level.
ISINTEG
ISINTEG is the Information Store Integrity Checker utility. ISINTEG finds and eliminates logical errors in Exchange information stores. These are errors that may prevent the database from starting or mounting. They also can prevent users from accessing their data. ISINTEG has many uses in restoring Exchange databases to normal operation, but should not be seen as a regular tool for information store maintenance. ISINTEG can only be of assistance in certain scenarios in which a database has become damaged. ISINTEG works at the logical schema level of the Exchange information store. Because of ISINTEG’s focus on the logical level rather than the physical database structure, it is able to repair and recover data that other tools like ESEUTIL (which looks at physical database structure) cannot. When looking at data from the physical database level, ESEUTIL may find it to be valid since it looks for things like page integrity and B-Tree structure. Data that appears valid to ESEUTIL from a physical view may not be valid from the logical view of the database. For example, data for various information store tables, such as the Message, Folder, or Attachments tables, may be intact, but the relationships between tables or records within tables may be broken or incorrect due to corruption in the logical structure. This may render the database unusable from a logical database schema point of view. ISINTEG can potentially repair this logical schema corruption when other utilities may not even be aware of the problem.
ESEUTIL
ESEUTIL (see Figure 4.2) defragments, repairs, and checks the integrity of the Microsoft Exchange Server information store. In versions prior to Exchange 2000, ESEUTIL could also be used on the directory database. Unlike ISINTEG, which is sensitive to the use and content of data in the information store, ESEUTIL examines the structure of the database tables and records. ESEUTIL looks at structural issues for both the database tables and the individual records. In repair mode, ESEUTIL deletes any corrupted pages found in the interest of getting the database operational as quickly as possible. You can run it on one database at a time from the command line. You should only use ESEUTIL if you are familiar with Exchange database architecture. The best bet is to use the tool with the assistance of Microsoft Product Support Services. Again, as in the case of ISINTEG, the use of ESEUTIL should not be a regular database maintenance activity. The defragment option makes used storage contiguous, eliminates unused storage, compacts the database, and reduces its size. ESEUTIL copies database records to a new database. When defragmention is complete, the original database is deleted or saved to a user-specified location, and the new version is renamed as the original. If the utility encounters a bad record, it stops and displays an error. When defragmenting a database, the recommended requirement is disk space equal to twice the size of the database being defragmented. The defragment option of ESEUTIL is the /D switch along with the database name and other options. ESEUTIL since Exchange 2000 changed significantly because the nature and structure of Exchange 2000/2003 databases has also changed. The most notable change is that the /IS, /ISPRIV, /ISPUB, and /DS switches are no longer supported. The information about the location of the databases and transaction log files is now stored in the Windows AD (not the registry). Therefore, the information is not readily available to ESEUTIL (unless Microsoft went to the trouble of making ESEUTIL AD-aware), and the paths must be manually specified. The /S option has been added to allow you to specify a checkpoint file (*.CHK) that is in an alternative directory. The /L option provides a similar capability to specify and alternate locations for transaction log files. Several other changes to ESEUTIL have also been made for Exchange 2000 and later versions. It is important that you understand all of the new switches and options for ESEUTIL before using it with Exchange 2000/2003 databases. ESEUTIL is also critical to administrator-driven concurrent recovery operations in which you wish to initiate multiple recovery operations against the same storage group concurrently.
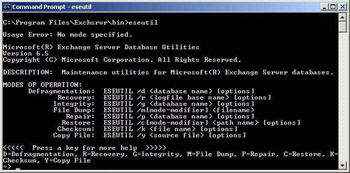
Figure 4.2: ESEUTIL command line options and parameters.
ESEFILE
ESEFILE is a tool written by the Exchange ESE development team for the specific purpose of checking the physical page integrity for the property store (EDB file). ESEFILE actually contains no ESE code but is simply a very light program that does nothing but page comparison and checksum validation. The main use of ESEFILE is to check individual databases for bad pages. ESEFILE (see Figure 4.3) uses Win32 file system APIs to read ESE pages directly from the EDB file. Each 4-K page is read in sequential order, and the page number and the checksum is verified. Since ESEFILE contains no ESE code, it runs very fast. ESEFILE has three functions, as described in Table 4.4. ESEFILE must be run with the database off-line.
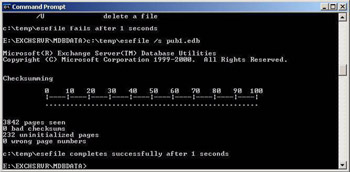
Figure 4.3: Using the ESEFILE utility to check physical database page integrity.
The ESEUTIL, ESEFILE, and ISINTEG utilities are very powerful programs. Left in the hands of an inexperienced administrator, these tools can also be very dangerous. These utilities can help resolve logical and physical corruption that occurs with the Exchange information store databases. However, my recommendation and that of Microsoft Product Support is that these tools be used only after efforts to restore from an on-line backup have failed. In this case, these utilities may help get your Exchange server up and running again. However, the price may be lost data since these utilities cannot magically recreate lost or corrupted data. Logical and physical corruptions are typically the most common reasons (aside from pure human error) that information store recovery operations are performed.
4.1.2 Infrastructure failures
As an Exchange administrator, you know that you cannot take much for granted. However, we often focus too much on the Exchange server itself— not realizing the potential pitfalls and impacts to our service that other core infrastructure services expose. Like any other application service, Exchange does not live in a vacuum, but it relies on a plethora of other supporting services. These services can have a detrimental impact on your ability as an Exchange administrator to meet your SLAs. What is worse, many of these services are out of your control and domain. As such, it is important that we briefly visit some of these key services and their impact on Exchange Server services and make some suggestions as to how to prevent failures in this area of vulnerability.
Active directory
Exchange 2000 became known as the “killer app” for Windows AD. Exchange 2000 Server was the first application to really leverage AD content. Exchange 2000/2003 Server uses the AD infrastructure for several purposes. First and foremost is authentication . When clients and other servers need to access an Exchange 2000/2003 Server, an AD DC is consulted. In fact, when any operations by clients or Exchange 2000/2003 Servers require authentication, the DC is used. Another use for the AD by Exchange 2000/2003 is configuration information . Server configuration data for organization, Administrative Groups, Routing Groups, Storage Groups, databases, and a multitude of other Exchange 2000/2003 configuration data is stored in the AD. When Exchange needs that data, the AD is consulted (either via a DC or GC server). Another key use of the AD comes from Exchange 2000/2003 clients. When an Exchange client requires a Global Address List (GAL), this lookup comes from the AD (more specifically, from a GC server). Exchange 2000/2003 also relies on the AD for other key functions such as user and server resolution, message routing, and SMTP operations. Exchange 2000/2003 uses a feature known as DSAccess to perform these AD access activities. Early on in the initial release of Exchange 2000, DSAccess was very sensitive to issues with the AD service. In more recent Exchange 2000 service packs and in Exchange Server 2003, DSAccess has been greatly enhanced to better manage problems with AD service availability. However, there are some good practices (shown in Table 4.3) that you can implement to ensure your AD service is all that Exchange needs it to be.
| Active Directory Component | Exchange Usage | Best Practices |
|---|---|---|
| Active Directory Global Catalog Server (GC) |
|
|
| Active Directory Domain Controller |
|
|
DNS
Like the AD, Exchange 2000/2003 also relies on the Domain Name Service (DNS) for several things. First, both clients and servers require DNS in a Windows environment to resolve host names to IP addresses on the network. More importantly, however, is Exchange 2000/2003 Server’s reliance on DNS for message routing and SMTP operations. Since Exchange 2000/ 2003 uses SMTP natively as the default message routing transport, the availability of the DNS service is critical to message flow throughout an Exchange organization. Equally important, Exchange clients also use DNS to find Exchange servers and AD domain controllers and global catalog servers. Again, as an Exchange administrator, this may be out of your control. However, you should take steps to ensure your requirements for the DNS service are well understood by those who support this service (in fact, you should have SLAs with the team that provides DNS services in your IT organization). This will ensure that proper reliability measures are in place so that Exchange services are not interrupted as a result of DNS service failure.
4.1.3 Software anomalies
Perhaps the most ellusive causes of server outages and downtime are those that are too numerous to list but can all be placed into the “bucket” or category of software anomalies. This area of downtime causation is the most difficult to nail down since it is caused by both individual software components and their anomalies, as well as those produced by the interaction of software components running on an Exchange server. Arguably, this is perhaps the second leading cause of downtime. However, since it is so difficult to track down, it is very hard to prove or document.
Microsoft software is often the first to get blamed when Exchange or Windows servers crash. Understandably, a typical Exchange server does depend on a lot of Microsoft software before you even get to the layer of Exchange. Operating system services and fundamental constructs are the building blocks and foundation of an Exchange server and the services such as Internet Information Server (IIS), AD, the file system (NTFS), and others are critical to Exchange Server’s operational success. Microsoft is the first to admit that their software is not perfect. I can guarantee you that no product has ever shipped with all bugs fixed. Whether already known or new, bugs in Microsoft software (or any other software, for that matter) will never cease to exist. It is these problems—whether previously known or not—that produce an inherit risk to any application running on top of Windows (again, I could say the same thing about UNIX, Linux, or any other operating system ever invented or to be invented, so don’t get excited about me bashing Microsoft software).
Although it is Microsoft software that gets blamed most of the time for software anomalies that lead to downtime, it is my opinion that third-party software is the real leading cause. Take a look at your average Windows server and inventory the third-party software running on it. There are antivirus software, backup software agents, management software agents, UPS software, device drivers, and so forth cluttering most servers. Since these software components have, most likely, not been extensively tested on one another, there is a great deal of room for error. At least Microsoft is able to test most of its own software together, but how much does it get to test third-party software? Third-party software vendors test their software with Windows, but do they test with Exchange Server and other third-party software? If they do, the testing probably is not that extensive. In my personal experience working with customers running Exchange Server, I have seen the anomalies produced by the interactions of third-party software to be a frequent and common cause of Exchange server outages. The most common examples of this are backup agents and antivirus agents running on Exchange Server. In fact, Microsoft PSS has frequently cited antivirus and backup software as one of the top case issues on which they work with regard to Exchange Server support.
The interactions of all these components create a huge potential for problems and there are simply too many variables to control and accurately predict. Software anomalies may be a leading cause of downtime but both Microsoft and third-party vendors are doing better at alleviating this potential pain. Third-party certification and signing by Microsoft as well as new technology efforts such as the Exchange AntiVirus API (AVAPI) for antivirus software, Windows Volume Shadow Copy Services (VSS), and Exchange ESE APIs for backup are a good start. For example, when antivirus vendors leverage Exchange Server’s AVAPI, they greatly reduce the potential for problems with their software and Exchange, as well as make both their software and Exchange much easier to support. For Microsoft, the “Trustworthy Computing” initiative is the embodiment of this goal. In February 2002, Microsoft launched this initiative internally and externally, and it has had a great impact specifically on the reliability and security of Microsoft software. This initiative also raises the bar in the industry for all vendors to do a better job in this area. As you plan to make your Exchange servers more reliable, don’t forget to factor in the importance and impact of all the software you have running on your Exchange server. When properly understood and precertified (meaning thoroughly tested in the lab first), the total package of software running on your Exchange server should contribute to server availability—not detract from it.
4.1.4 Operator failures
Regardless of whose study of the leading causes of downtime you cite, operator/human error always tops the list. We humans are just not perfect (despite my attempts to convince my wife otherwise). It’s not that we are just plain stupid, it is that we are impacted by too many uncontrollable variables, such as experience, training, sleep, emotional state, and so forth. What this means to us as Exchange administrators is that regardless of what measures we take to ensure the reliability of our Exchange servers, human error can unravel it all. The best way to address this is to start by accepting this fact. From there, we can proceed to putting measures in place to mitigate the impact of human error on the reliability of our Exchange deployments. The standard fare here includes well-documented operational procedures, training, operational automation, availability of the right tools, and a plethora of other measures to ensure minimal impact of the human element.
EAN: 2147483647
Pages: 91