Troubleshooting Philosophies
Troubleshooting philosophies vary depending upon training, knowledge, ability, suspicions, system history, personal discipline, and how much heat you are getting from users and management. Many philosophies fall apart when pressure mounts from users screaming that they need network services now, and when managers apply even more pressure because they do not understand or appreciate the complexities of network troubleshooting. If you are susceptible to these pressures, this causes you to become unstructured in your approach and to depend upon random thoughts and clues. Ultimately, this increases the time to restore or deploy network services. Characteristics of a good troubleshooting philosophy, though, include structure, purpose, efficiency, and the discipline to follow the structure.
Two philosophical approaches are presented here to organize your thoughts. The first method to be discussed describes an approach recognizing problems based upon their probability of occurrence. They are then categorized into one of three "buckets" for the differing probabilities. This is the bucket approach to troubleshooting.
The second approach tackles network problems based upon the OSI model. Each layer represents a different network structure that you might need to examine to restore your network. This is the OSI model approach for troubleshooting.
The approaches really tackle problems in a very similar manner, but represent different methods of remembering the approach. The second method does differ, though, in its granularity. The bucket approach groups troubles into three buckets. Each bucket contains problems with similar characteristics and represents areas of probable problems. The second approach tackles problems through the OSI model. The model helps to think through symptoms and what high-level sources might cause the problems.
In reality, your troubleshooting technique probably uses a little of both. The bucket method lumps the OSI model, to some extent, into three areas.
Regardless of which approach you use, you must have one foundational piece to troubleshoot your network: documentation.
Keep and Maintain Network Documentation
One element for any troubleshooting philosophy to work is frequently absent: documentation. Many administrators neglect to document their network, or if they do, they do not keep the documentation up to date. Documentation provides the framework to answer fundamental questions such as, "What changed?" or "What connects to device X?" or "What Layer 2 paths exist from point A to point B?" Reconstructing the network topology documentation during a crisis does not lend itself to an efficient or structured troubleshooting approach. You are not doing yourself, your career, or your users any good when you have to take time during the crisis event to determine the network topology.
Document your network with both electronic media and old-fashioned paper. Electronically, use spreadsheets, graphics programs, network management tools, or any other means at your disposal to keep the documentation up to date. Electronic documentation has the advantage of portability; however, it has the disadvantage of limited access and vulnerability to outages. If you keep the documentation on your laptop or desktop, but make it inaccessible to others on your staff by either taking it with you or using passwords, they cannot use the documentation when you are not around. For security reasons (or to satisfy company politics), you might desire this, but in most cases this is not a good practice.
Paper versions offer non-dependence upon the electronic device, but frequently tend to be outdated through neglect. When you make an electronic change, make sure that the paper copy reflects the change as well.
Another underutilized documentation tool exists in your network equipment. Most equipment has built-in documentation features such as description strings for interfaces, modules, chassis, and so forth. Use these to prompt your memory for connectivity. It takes only a few seconds to put a description string on the port configuration. On the Catalyst 5000/6000, use the set port name mod_num/port_num [port_name] command to document interfaces with useful information. For example, you might indicate who or what attaches to the port. If the port is a trunk, indicate what Catalyst it connects to. As with previous documentation discussions, be sure to keep the descriptions current. You will see the port name if you use the show port status command as shown in Example 16-1. Here, Ports 1/1 and 3/1 have assigned names indicating the device the port attaches to.
Example 16-1 Output from show port status
Console> show port status Port Name Status Vlan Level Duplex Speed Type ----- ------------------ ---------- ---------- ------ ------ ----- ------------ 1/1 Cat-B connected 523 normal half 100 100BaseTX 1/2 notconnect 1 normal half 100 100BaseTX 2/1 connected trunk normal half 400 Route Switch 3/1 LS1010Switch12 notconnect trunk normal full 155 OC3 MMF ATM Troubleshooting Philosophy 1: The Bucket Approach
The bucket approach to troubleshooting investigates likely problem areas based upon the probability of occurrence. It structures thoughts in terms of target areas for investigation. Specific problem areas frequently create the majority of situations you are likely to encounter. You can categorize these problems and place them into one of three buckets: cabling, configuration, and usage/implementation (other). The following sections describe the kinds of things to look for from each bucket. It is suggested that the probability of occurrence decreases for each bucket, as depicted by the size of the buckets in Figure 16-1. The first bucket, Cabling, is largest because it represents the highest probability of occurrence. You should check for problems from this bucket first in your network. The second bucket, Configuration, contains another group of problems, but typically has fewer instances in your network. Therefore, you check these problems after examining the cables. The last and smallest bucket, Other, contains all of the other problems that don't necessarily fall into either of the first two. Problems from this bucket occur the least and should be examined last in your system.
Each bucket is its own Pandora's Box. Unfortunately, no one stands over the bucket warning everyone to not spill the bucket. It happens. Your job in troubleshooting is to determine which bucket spilled its contents into your network.
Figure 16-1. Three Buckets of Problems
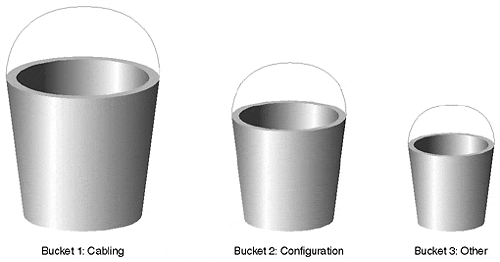
Bucket 1: Cabling
The bucket of cable problems contains issues such as wrong cables, broken cables, and incorrectly connected cables. Too often, administrators overlook cables as a trouble source. This is especially true whenever the system "was working." This causes troubleshooters to assume that because it was working, it must still be working. They then investigate other problem areas, only to return to cables after much frustration.
Common cable mistakes during installation generally include using the wrong cable type. One, for example, is the use of a crossover cable rather than a straight through cable, or vice versa. The following list summarizes many of the typical problems:
Crossover rather than straight through, or vice versa
Single-mode rather than multimode
Connecting transmit to transmit
Connecting to the wrong port
Partially functional cables
Cable works in simplex mode, but not full-duplex
Cables too long or too short for the media
Remember that when attaching an MDI (media dependent interface) port to an MDI-X (media dependent crossover interface) port, you must use a straight through cable. All other combinations require a crossover cable type. Fortunately, using the wrong cable type keeps the link status light extinguished on equipment. This provides a clue that the cable needs to be examined. An extinguished link status light can result from the correct cable type, but a broken one. Be aware that an illuminated link status light does not guarantee that the cable is good either. The most that you can conclude from a status light is that you have the correct cable type and that both pieces of equipment detect each other. This does not, however, mean the cable is capable of passing data.
A form of partial cable failure can confuse some network operations like Spanning Tree. For example, if your cable works well in one direction, but not the other, your Catalyst might successfully transmit BPDUs, but not receive them. When this happens, the converged Spanning Tree topology might be incorrect and, therefore, dysfunctional.
Note
I have a box filled with cables that were healthy enough to illuminate the status light on equipment, but not good enough to transmit data. Consequently, I wasted much time investigating other areas only to circle back to cables. I should have stuck with my troubleshooting plans and checked the cables rather than bypassing it. Make sure that you have a cable tester handy one capable of performing extensive tests on the cable, not just continuity checks.
Cisco introduced a feature in the Catalyst 6000 series called Uni-Directional Link Detection (UDLD), which checks the status of the cable in both directions, independently. If enabled, this detects a partial cable failure (in one direction or the other) and alerts you to the need for corrective action.
Another copper cable problem can arise where you fully expect a link to autonegotiate to 100 Mbps, but the link resolves to 10 Mbps. This can happen when multiple copper cables exist in the path, but are of different types. For example, one of the cable segments might be a Category 3 cable rather than a Category 5. Again, you should check your cables with a cable tester to detect such situations.
Another example of using a wrong cable type is the use of single-mode fiber rather than multimode, or multimode rather than single-mode. Use the correct fiber mode based upon the type of equipment you order. There are a couple of exceptions where you can use a different fiber mode than that present in your equipment, but these are very rare. Plan on using the correct fiber type. As with any copper installation, look for a status or carrier light to ensure that you don't have a broken fiber or that you didn't connect the transmit of one box to the transmit of the other box. And as with copper, a carrier light does not always ensure that the cable is suitable for data transport. You might have too much attenuation in your system for the receivers to decode data over the fiber. If using single-mode fiber, you might have too much light entering the receiver. Make sure that you have at least the minimal attenuation necessary to avoid saturating the optical receiver. Saturating the receiver prevents the equipment from properly decoding the equipment.
Unless there is a clearly obvious reason not to do so, particularly in an existing installation, check cables. Too often, troubleshooting processes start right into bucket 2 before eliminating cables as the culprit.
Bucket 2: Configuration
After confirming that cables are intact, you can start to suspect problems in your configuration. Usually, configuration problems occur during initial installations, upgrades, or modifications. For example, you might need to move a Catalyst from one location to another, but it doesn't work at the new location. Problems here can arise from not assigning ports to the correct VLAN, or forgetting to enable a trunk port. Additional configuration problems include Layer 3 subjects. Are routers enabled to get from one VLAN to another? Are routing protocols in place? Are correct Layer 3 addresses assigned to the devices? The following list summarizes some of the things to look for in this bucket:
Wrong VLAN assignments on a port.
Wrong addresses on a device or port.
Incorrect link type configured. For example, the link might be set as a trunk rather than an access link, or vice versa.
VTP domain name mismatches.
VTP modes not set correctly.
Poor selection of Spanning Tree parameters.
Trunk/access port mismatches.
EtherChannel mismatches.
Routing protocols not enabled.
Default paths not defined.
One of the most common configuration errors is wrong VLAN assignments. Administrators move a device to another port and forget to ensure that the VLAN assignment is consistent with the subnet assignment.
Other configuration errors arise from not modifying default parameters to enable a feature, or to change the behavior of a feature. For example, the trunk default mode is auto. If you leave the Catalyst ports at both ends of the link in the default state, the link does not automatically become a trunk. You might not realize that they are in the default setting and fail to realize the true reason for the link remaining as an access link.
The Catalyst PortFast feature, disabled by default, can correct many network problems when enabled. If you have clients failing to attach to the network or network services, you might need to enable PortFast to bypass the Spanning Tree convergence process and immediately reach the Forwarding state.
Note
You can enable PortFast on all ports except for trunk ports to alleviate the probability of client/server attachment problems. However, enable this feature with caution, as you can create temporary Layer 2 loops in certain situations. PortFast assumes the port is not a part of a loop and does not startup by looking for loops.
Bucket 3: Other
This bucket contains most other problem areas. The following list highlights typical problems:
Hardware failures
Software bugs
Unrealistic user expectations
PC application inadequacies
Sometimes, a user attempts to do things with his application program that it was not designed to do. When the user fails to make the program do what he thinks it should do, he blames the network. Of course, this is not a valid user complaint, but is an all-too-often scenario. Ensure that the user need is valid before launching into a troubleshooting session.
Unfortunately, you can discover another culprit in this bucket. Equipment designers and programmers are not perfect. You will encounter the occasional instance where a product does not live up to expectations due to a manufacturer's design flaw or programming errors. Most manufacturers do not intentionally deploy flawed designs or code, but it does occasionally happen. When corporate reputations are volatile and stockholder trust quickly evaporates, vendors work aggressively to protect their image. Vendors rarely have a chance to intervene reputation slams on the Internet because word spreads quickly. It is much more difficult for a vendor to recover a reputation than to maintain it. Therefore, vendors usually work under this philosophy and strive to avoid the introduction of bad products into the market.
As administrators, though, we tend to quickly blame the manufacturer whenever we experience odd network behavior that we cannot resolve. Although easy to do, it does not reflect the majority of problems in a network. We do this because of the disreputable companies that polluted the market and occasionally crop up today. Many networks fail to achieve their objectives due to unscrupulous vendors. As an industry, we now tend to overreact and assume that all companies operate that way. Do not be too quick to criticize the manufacturer.
Note
Yes. Even Cisco has occasional problems. Be sure to check the Cisco bug list on the Web or send an inquiry to Cisco's Technical Assistance Center (TAC) if you experience unusual network problems. This might be an unexpected "feature" of the software/hardware.
Troubleshooting Philosophy 2: Evaluate Layers of the OSI Model
The other troubleshooting philosophy looks at problems according to the OSI model that divide network technology into identifiable components. As you identify problems at each of the layers, you will find that you can place them into one of the three buckets discussed in the previous section. You can, for example, look at the physical layer. Problems at the physical layer relate to cables and media. Is there too much cable? Not enough? Did you connect the cable into the correct port? Clearly these problems easily fit into the first bucket.
What about the second layer of the OSI model, the data link layer? This layer describes the media access method. It defines how Token Ring and Ethernet operate. It also defines how the bridging methods work for these access methods. Spanning Tree and source route bridging operate at this layer. 802.1Q encapsulation is defined at Layer 2. If you misconfigure the native VLAN on the two ends of the link, the trunk port experiences errors.
At Layer 3, you must investigate routing issues. If you have problems communicating with devices in another VLAN, you need to determine if the Layer 3 is not routing correctly, or if there is something at Layer 1 or Layer 2 preventing the VLANs from functioning. Diagnostic approaches here test connectivity from a station to the router, and then across the router(s) interface. Figure 16-2 shows three VLANs interconnected with routers. Systematic troubleshooting determines if Layers 1 and 2 operate by attempting communication to each router interface.
Figure 16-2. Testing Cross VLAN Connectivity
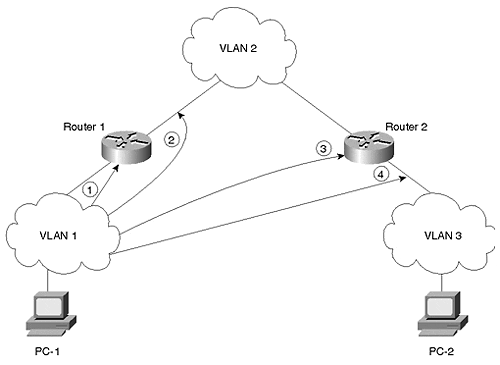
In Figure 16-2, PC-1 desires, but fails, to communicate with PC-2 in the figure. Assume that it is an IP environment. From one PC or the other, attempt to communicate (maybe with ping) to the first hop router. For example, you might first initiate a ping from PC-1 to the Router 1 interface (point 1 in the figure). Do this bypinging the IP address of the ingress port of Router 1 which belongs to the same subnet as PC-1. Then, try the outbound interface on Router 1 (point 2 in the figure). Continue through the hops (points 3 and 4) until you reach PC-2. Probably, somewhere along the path, pings fail. This is your problem area. Now, you need to determine if there is a routing problem preventing the echo request from reaching the router, or an echo reply from returning. For example, suppose the ping fails on the ingress port of Router 2 (point 3). To determine if the problem is at Layer 2, attempt to ping the router interface from another device in the VLAN. This might be another workstation or router in the broadcast domain. If the ping fails, you might reverse the process. Try pinging from the router to other devices in the broadcast domain. Check the router's interface with the show interface command. On the other hand, you might need to check the Catalyst port to ensure that the port is active. You might need to check the following items for correctness:
Is the port enabled?
Is the port a trunk or access link?
If not a trunk, is the port in the correct VLAN?
Does the port speed and duplex match the settings on the attached device?
The Catalyst show port command provides this information. If all of these parameters look good, you probably have a Layer 3 issue preventing the router port from communicating. One further data point to investigate: Do any other protocols have a problem getting through/to this router? If they also have problems, this is a strong pointer to Layer 2 issues. If other protocols work, but IP does not, you need to seriously investigate Layer 3. Check the router's port address and mask to ensure that it belongs to the same subnet as the other devices in the broadcast domain.
Remember that you might need to redraw your network to show Layer 3 paths. Chapter 5, "VLANs," discussed how the physical drawing of your network does provide good insight in how the data flows in your network. A drawing that shows how Catalysts interconnect provides some Layer 2 information about data flow, but certainly not any about Layer 3. For effective troubleshooting, you might need to show the Layer 2 and the Layer 3 paths in the network. For intra-VLAN troubleshooting, you need to draw the Layer 2 paths. This should include bridges and trunks so that you can examine your Spanning Tree topology. If you have problems with inter-VLAN connections, you might need to draw both layers. You might need to draw Layer 2 to ensure that you can get from a device to the next hop within the VLAN. Communication from router to router must cross a VLAN. Likewise, you might need to draw the Layer 3 pictures to ensure that you know what router paths the data transits so that you know what VLANs to examine.
Other Layer 3 issues might include access lists or routing table problems in routers. If you have an access list blocking certain stations or networks from communicating with each other, the system might appear to be broken, but in fact is behaving just like you told it to.
Be sure also to check workstation configurations. If the workstation has a wrong IP address for the VLAN it attaches to, it will fail to communicate with the rest of the world. Fortunately, IP utilities like DHCP minimize this, but occasionally some stations are manually configured and need to reflect the subnet for the VLAN.
EAN: N/A
Pages: 223
- Integration Strategies and Tactics for Information Technology Governance
- Linking the IT Balanced Scorecard to the Business Objectives at a Major Canadian Financial Group
- A View on Knowledge Management: Utilizing a Balanced Scorecard Methodology for Analyzing Knowledge Metrics
- Measuring ROI in E-Commerce Applications: Analysis to Action
- Technical Issues Related to IT Governance Tactics: Product Metrics, Measurements and Process Control