Section 9.6. Multi-Byte Strings and Character Sets
|
9.6. Multi-Byte Strings and Character SetsNot all languages use the same character set, not even in the western world. For example, the Unicode solves the problem by assigning a number to every unique character, just like the ISO 10646 standard. This standard reserves 31 bits for characters, which should be more than enough room for every script out there (including "fictional" scripts like Tolkien's Tengwar and the Egyptian hieroglyphs). The characters that fit in the range 0-127 are the same as the good old ASCII standard, and the range 0-255 is the same as iso-8859-1 (Latin 1). All "normal" scripts characters are encoded in the range 0-65533a subset called the Basic Multilingual Plane (BMP). Although Unicode only assigns numbers to characters, it is usually not used to store text. The simplest ways of encoding are UCS-2 and UCS-4, which store characters as 2- or 4-byte sequences. UCS-2 and UCS-4 are not really useful because there is a possibility of NULL bytes in the text or because the text would use too much space, even when the characters are only in the ASCII range. UTF-8, which solves these problems, is used more often. Characters in an UTF-8 encoded string can be 1 to 6 bytes long and can represent all 231 characters from UCS. This section of the chapter deals mainly with UTF-8 and conversions to other encodings (such as iso-8859-1). Tip For more information on Unicode, see the excellent FAQ at http://www.cl.cam.ac.uk/~mgk25/unicode.html. 9.6.1. Character Set ConversionsPHP 5 has support for character encoding and multi-byte issues in two extensions: iconv and mbstring. The main difference between the two is that iconv makes use of an external library (or the C library functions, if available), while the mbstring extension has the library bundled with PHP. Although iconv (at least in recent Linux distributions) supports much more encodings, mbstring might be the better choice for a script that has to be more portable. In addition to character encoding conversions, the mbstring extension includes a multi-byte regular expression library. The mbstring extension is enabled with the --enable-mbstring option. The additional regular expression support is enabled by default when mbstring is enabled, but it can be turned of with --disable-mbregex. The iconv extension is enabled with the --with-iconv switch. In Figures 9.13 and 9.14, you find the corresponding sections in phpinfo() for mbstring and iconv. The examples cover both extensions, whenever possible, and the character set used in the example scripts and output is in ISO-8859-15, unless otherwise noted. Figure 9.13. mbstring phpinfo() output. Figure 9.14. iconv phpinfo() output. Note Some of these examples require OS support for the used character set. If something is not supported, you might see a different output for the example scripts. In the first example, we convert ISO-8859-15 (Latin 9) text to UTF-8: <?php $string = "Kan De være så vennlig å hjelpe meg?\n\n"; echo "ISO-8859-15: $string"; echo 'UTF-8: '. mb_convert_encoding($string, 'UTF-8', 'ISO-8859-15'); echo 'UTF-8: '. iconv('ISO-8859-15', 'UTF-8', $string); ?> When the script runs, the output looks like this: ISO-8859-15: Kan De være så vennlig å hjelpe meg? UTF-8: Kan De và re sÃ¥ vennlig Ã¥ hjelpe meg? UTF-8: Kan De và re sÃ¥ vennlig Ã¥ hjelpe meg? Sometimes, it's not possible to convert text from one encoding to another, as shown in the following example: <?php error_reporting(E_ALL & ~E_NOTICE); $from = 'ISO-8859-1'; // Latin 1: West European $to = 'ISO-8859-2'; // Latin 2: Central and East European $string = "Denna text är på svenska."; echo "$from: $string\n\n"; echo "$to: ". mb_convert_encoding($string, $to, $from). "\n\n"; echo "$to: ". iconv($from, $to, $string). "\n\n"; echo "$to: ". iconv($from, "$to//TRANSLIT", $string). "\n\n"; ?> We try to convert the text Denna text är på svenska. from ISO-8859-1 to ISO-8859-2, but the "å" does not exist in ISO-8859-2. mb_convert_encoding() handles replaces the offending character (by default) with a "?", whereas iconv() just aborts the conversion at that point. However, you can add the //trANSLIT modifier to the to encoding parameter to tell iconv() to replace the offending character by a "?". The //trANSLIT also tries to convert to a representation of a character, such as converting "©" to "(C)", while converting from ISO-8859-1 to ISO-8859-2. You can use the mb_substitute_character() function to tell the mbstring extension to do something different with an offending character, as shown here: <?php error_reporting(E_ALL & ~E_NOTICE); $from = 'ISO-8859-1'; // Latin 1: West European $to = 'ISO-8859-4'; // Latin 4: Scandinavian/Baltic $string = "Ce texte est en français."; echo "$from: $string\n\n"; // Default echo "$to: ". mb_convert_encoding($string, $to, $from). "\n"; // no output for offending characters: mb_substitute_character('none'); echo "$to: ". mb_convert_encoding($string, $to, $from). "\n"; // Unicode value output for offending characters: mb_substitute_character('long'); echo "$to: ". mb_convert_encoding($string, $to, $from). "\n"; ?> outputs ISO-8859-1: Ce texte est en français. ISO-8859-4: Ce texte est en fran?ais. ISO-8859-4: Ce texte est en franais. ISO-8859-4: Ce texte est en franU+E7ais. Tip The web site http://www.eki.ee/letter/ is a useful tool that shows you what happens during character conversions. It provides lists of special characters needed to write a certain language, including a list of encodings that support this set. mbstring() also features a non-encoding encoding html which might be useful in some cases: <?php error_reporting(E_ALL & ~E_NOTICE); $from = 'ISO-8859-1'; // Latin 1: West European $to = 'html'; // Pseudo encoding $string = "Esto texto es Español."; echo "$from: $string\n"; echo "$to: ". mb_convert_encoding($string, $to, $from). "\n"; ?> outputs ISO-8859-1: Esto texto es Español. html: Esto texto es Español. The third parameter to the mb_convert_encoding() function is optional and defaults to the "internal encoding" that you can set with the function mb_internal_encoding(). If there is a parameter, the function returns either TRUE, if the encoding is supported, or FALSE and a warning if the encoding is not supported. If no parameters are passed, the function simply returns the current setting: <?php echo mb_internal_encoding(). "\n"; if (@mb_internal_encoding('UTF-8')) { echo mb_internal_encoding(). "\n"; } if (@mb_internal_encoding('ISO-8859-17')) { echo mb_internal_encoding(). "\n"; } echo mb_internal_encoding(). "\n"; ?> outputs ISO-8859-1 UTF-8 UTF-8 Tip You can see a list with supported encodings by using the function mb_get_encodings(). The iconv extension has similar possibilities. The function iconv_set_encoding() can be used to set the internal encoding and the output encoding: <?php iconv_set_encoding('internal_encoding', 'UTF-8'); iconv_set_encoding('output_encoding', 'ISO-8859-1'); echo iconv_get_encoding('internal_encoding'). "\n"; echo iconv_get_encoding('output_encoding'). "\n"; ?> outputs UTF-8 ISO-8859-1 The internal encoding setting has an effect on a couple of functions (which we cover in a bit) dealing with strings. The output encoding option doesn't have any effect on those options, but can be used in combination with the ob_iconv_handler output buffering handler. With this enabled, PHP will automatically convert the text output to the browser from internal encoding to output encoding. It adjusts the Content-type header if it wasn't set in the script, and the current Content-type starts with text/. This example changes the output encoding to UTF-8 and activates the output handler. The result is an UTF-8 encoded output page (see Figure 9.15): <?php ob_start("ob_iconv_handler"); iconv_set_encoding("internal_encoding", "ISO-8859-1"); iconv_set_encoding("output_encoding", "UTF-8"); $text = <<<END PHP, est un acronyme récursif, qui signifie "PHP: Hypertext Preprocessor": c'est un langage de script HTML, exécuté coté serveur. L'essentiel de sa syntaxe est emprunté aux langages C, Java et Perl, avec des améliorations spécifiques. L'objet de ce langage est de permettre aux développeurs web d'écrire des pages dynamiques rapidement. END; echo $text; ?> Figure 9.15. UTF-8 encoded output. The other way around is a bit more useful. It makes more sense to store all of your data in UTF-8 (for example, in a database) and convert to the correct encoding for the language you're currently serving. 9.6.2. Extra Functions Dealing with Multi-Byte Character SetsA couple of extra functions in both the mbstring and iconv extension are surrogates for some of the string functions. For example, iconv_strlen (and mb_strlen) returns the number of "characters" (not bytes) in the strings passed to the function: <?php $string = "Må jeg bytte tog?"; $from = 'iso-8859-1'; $to = 'utf-8'; iconv_set_encoding('internal_encoding', $to); echo $string."\n"; echo "strlen: ". strlen($string). "\n"; $string = iconv($from, $to, $string); echo $string."\n"; echo "strlen: ". strlen($string). "\n"; echo "iconv_strlen: ". iconv_strlen($string). "\n"; ?> outputs Må jeg bytte tog? strlen: 17 MÃ¥ jeg bytte tog? strlen: 18 iconv_strlen: 17 The iconv_strlen() takes into account the multi-byte character Ã¥ (which is UTF-8 for "å"). Replacement functions for strpos() and strrpos() also exist. With these and the replacement for substr(), you can safely find a multi-byte string inside another multi-byte string. While trying to come up with an example for these functions that shows why it is important to use the multi-byte variants of those functions, we realized that it does not matter at all if UTF-8 is used as the encoding. The common problem that we are trying to illustrate was that a uni-byte character (like ") could also be a part of a multi-byte character in the same string. However, for UTF-8 encoded strings this is not possible, because all bytes of a multi-byte character have ordinal values of 128 or greater, while single-byte characters are always less than the ordinal value 128. iconv_substr() is still useful for a multi-byte version of a "shorten" function, which in the example adds dieresis if a string is longer than a given set of characters (not bytes!). <?php header("Content-type: text/html; encoding: UTF-8"); iconv_set_encoding('internal_encoding', 'utf-8'); $text = "Ceci est un texte en français, il n'a pas de sense si ce n'est celui de vous montrez comment nous pouvons utiliser ces fonctions afin de réduire ce texte à une taille acceptable."; echo "<p>$text</p>\n"; echo '<p>'. substr($text, 0, 26). "...</p>\n"; echo '<p>'. iconv_substr($text, 0, 26). "...</p>\n"; ?> Note The character set in which this example is shown is UTF-8 and not ISO-8859-15. When this script is run, the output in a browser will be similar to Figure 9.16. Figure 9.16. Broken UTF-8 characters.
As you can see, the normal substr() function doesn't care about character sets. It chops the "ç" into two bytes, generating an invalid UTF-8 character which is rendered as the black square with the question mark in it. iconv_substr() does a much better job. It "knows" that the "ç" is a multi-byte character and counts it as one. For this to work, the internal encoding needs to be set to "UTF-8." To demonstrate the use of iconv_strpos(), we use UCS-2BE (which actually doesn't encode anything, but simply stores the least significant bits of a UCS character), rather than UTF-8. The following script shows why you need to use iconv_strpos() and cannot simply use strpos(): <pre> <?php $internal = 'UCS-2BE'; $output = 'UTF-8'; $space = ' '; $text = iconv('iso-8859-15', $internal, ' Because there is no way to create UCS-2BE encoded texts, we "create" a UCS-2BE encoded text from an ISO-8859-15 encoded string consisting of the Euro sign, a space, and the text 12.50. The Euro sign is especially interesting, because the UCS-2 encoding is 0x20 0xac (in hexadecimal). A single space in any ISO-8859-* encoding is assigned the same code 0x20. In Figure 9.17, you see the hexadecimal representation of the UCS-2 encoded string after Original. /* Initialize the output buffering mechanism */ iconv_set_encoding('output_encoding', $output); ob_start('ob_iconv_handler'); echo "Original: ", bin2hex($text), "\n"; Figure 9.17. Problems without iconv_strops(). We initialize the output buffer and set the output encoding to UTF-8. Then, we output the hexadecimal representation of our string, which will be converted to UTF-8 by the output buffer mechanism. /* The "wrong" way */ $amount = substr($text, strpos($text, $space) + 1); With strpos(), we locate the first space in the string. Then with substr(), we obtain everything following this first space and assign it to the $amount variable. However, this code doesn't do what we expected. echo "After substr(): ", bin2hex($amount), "\n"; ob_flush(); We print the hexadecimal representation of the new string and flush the output buffer. The flush is needed so that all data in the buffer is send to the iconv output handler and we can reset the internal encoding to UCS-2BE. Without this flush, the output handler does not correctly encode the output (because it normally operates in blocks of 4096 bytes only). As you can see in Figure 9.17, following After substr(): the "space" was matched in the wrong location. The normal substr() function doesn't know a thing about character sets, and thus the $amount variable does not contain valid UCS-2BE encoded text. iconv_set_encoding('internal_encoding', $internal); echo $amount; ob_flush(); We need to set the internal iconv encoding to UCS-2BE, echo the (broken) $amount string, and flush the output buffer so that we can change the internal encoding again. /* Convert space character to UCS-2BE and match again */ $space = iconv('iso-8859-1', $internal, $space); $amount = iconv_substr($text, iconv_strpos($text, $space) + 1); Now, we convert our space character into UCS-2BE too, so that we can use iconv_strpos() to find the first (real) occurrence in the string. iconv_strpos() uses the internal encoding setting to determine if a character is found inside the string. Just like the normal strpos(), it returns the position where the needle was found, or false if it wasn't found. Therefore, because 0 can be returned if the needle was found in the first position, you need to compare with === false to see whether the needle was actually found. In our example, it doesn't matter if the needle is found at position 0 or not at all, because the iconv_substr() will copy the string starting from position 0 (false evaluates to 0) anyway. iconv_set_encoding('internal_encoding', 'iso-8859-1'); echo "\nAfter iconv_substr(): ", bin2hex($amount), "\n"; ob_flush(); We temporarily set the internal encoding to ISO-8859-1 so that we can safely output the hexadecimal representation of the string. We flush the output buffer because we next want to output the $amount variable, which is encoded in UCS-2BE. iconv_set_encoding('internal_encoding', $internal); echo $amount; ?> With these final statements, the full output is displayed, as shown in Figure 9.14. Notice that the first match (space = 0x20) is wrong. After the second one, the correct 0x0020 was found and the string chopped up accordingly (see Figure 9.17). 9.6.3. LocalesThe mbstring extension has similar functions: mb_substr()and mb_strpos(). In addition, it has functions that can be used instead of the standard PHP functions strtoupper() and strtolower() (respectively, mb_strtoupper() and mb_strtolower()). The mbstring functions take into account Unicode properties so that they correctly change the string to upper- or lowercase characters for any supported character. But you don't have to use the mbstring functions to do this for you because your operating system's standard function library should support this by default. Information on how to upper- or lowercase a character is stored in a language's locale. A locale is a collection of information defining the properties of language-dependent settings, such as the date/time formats, number formats, and also which uppercase character correspondents to a lowercase character and vice versa. In PHP, you can use the setlocale() function to set a new locale or query the current locale. There are a few different "types" of locales; each type is meant to control a different type of language-dependent property. The different types are shown in Table 9.9.
|
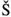 is only part of ISO-8859-2, not of ISO-8859-1. Because these character sets only have 8 bits to use, that only makes 256 different combinations. 8 bits is a problem for languages such as Chinese that have thousands of letters but 8 bits only support 256 characters. Thats why the Chinese (and also other Asian scripts) have to use another encoding for their characters, such as BIG5 or GB2312. The Japanse use other encodings for their characters: EUC-JP, JIS, SJIS, and so on. All those different character sets are a problem to work with because some map the same character number to a different character (such as © and
is only part of ISO-8859-2, not of ISO-8859-1. Because these character sets only have 8 bits to use, that only makes 256 different combinations. 8 bits is a problem for languages such as Chinese that have thousands of letters but 8 bits only support 256 characters. Thats why the Chinese (and also other Asian scripts) have to use another encoding for their characters, such as BIG5 or GB2312. The Japanse use other encodings for their characters: EUC-JP, JIS, SJIS, and so on. All those different character sets are a problem to work with because some map the same character number to a different character (such as © and 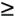 which caused our problem at the end of the preceding section). Thats one of the reasons the Unicode project was started.
which caused our problem at the end of the preceding section). Thats one of the reasons the Unicode project was started.
|
EAN: 2147483647
Pages: 240