What Is a Lock?
| Physically, a lock is one of three things: a latch, a mark on the wall, or a RAM record. LatchesA latch is a low-level on-off mechanism that ensures two processes or threads can't access the same object at the same time. You can make latches with, for example, the MS Windows NT API CreateMutex or CreateSemaphore functions. Consider the following situation (we'll call it Situation #1).
To avoid the crash, Situation #1 must change. Here's what should happen.
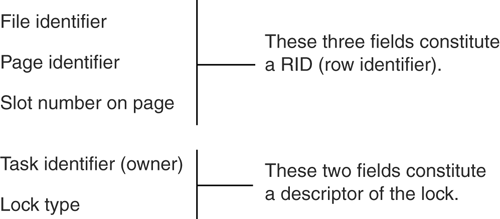
More concisely, the second situation uses mutexes or semaphores or EnterCriticalSection calls so that, when one thread starts to read a row, other threads are prevented from interrupting the read and changing the end of the row. MySQL uses a single statement latch for all processes, which means that two SQL statements cannot execute at the same time. The rest of the Big Eight are less extreme; they latch only while reading and writing bits of shared memory. A latch must be on for every shared bit of memory and must go off as soon as the memory has been read/written. Generally a transaction holds a maximum of one latch at any time, and that time is less than one millisecond. A second transaction that tries to get the same latch is blocked, so it must either spin (i.e., retry after an interval), or it must be enqueued (i.e., get in line). The words "blocked," "spin," and "enqueued" are forgettable jargon, but "latch" is a vital word because all multi-thread or multi-process DBMSs use latches. Marks on the wallA mark on the wall (properly known as an ITL slot ) is used occasionally, primarily by Oracle, to mark a row in a page of a data file. By putting a mark right beside the row accessed by a transaction, the DBMS ensures that no other transaction has to spend much time checking whether the row is locked. This mechanism only works when the number of locks in a page is small enough to fit in the page, so marks on the wall are appropriate mostly for exclusive locks (see "Lock Modes" later in this chapter). RAM recordsA RAM record (or lock record ) is the usual mechanism for locks of rows, pages, or tables. The RAM record is a permanent memory area that contains data describing what's locked, and how. For example, Microsoft's 32-byte lock records contain the information shown in Figure 15-1. Figure 15-1. A Microsoft lock record Keeping lock records in memory can cause high overhead. For example, if lock records are in order by time of creation rather than in order by RID or indexed by RID, they're quite a jumble . When the DBMS wants to lock a row, it must first scan all the lock records to see whether another transaction already has a lock on that row. So if Transaction #1 has done a scan and locked all of a table's rows (assume there are 50,000 rows), and then Transaction #2 does a scan of the same table, Transaction #2 must, on average, check 50,000/2 locks for each page for a total of 50,000 * (50,000/2) = 1,250,000,000 checks. To prevent such unacceptable situations, a DBMS will reduce lock longevity and lock count through practices like escalation. We'll discuss escalation later in this chapter. When the DBMS encounters a lock that it can't pass, it has two choices: it can return an error to the user (NO WAIT), or it can try spinning and enqueuing (WAIT). Oracle lets you choose whether you want NO WAIT or WAIT. Other DBMSs insist on WAIT, but they will time out if a specific period expires (say, one minute). Generally the DBMS vendors think it's better to WAIT, because users who receive an error message will probably just try again from the beginning of the transaction. Lock ModesLock mode (or lock type ) is the term for the type of lock a DBMS has arranged for a transaction. When DBMS makers pretend to offer a bizarre plethora of lock modes, we must force the truth from them: there are only three lock modes, and usually two are enough. The rest are fine distinctions and nuances , and we won't discuss them here. The three lock modes are shared, update, and exclusive. A lock's mode determines (a) what other locks can coexist with this lock and (b) whether other transactions have read and/or write permission when this lock exists. (For the record, a latch is an exclusive lock on anything. In this section, though, we're discussing only the non-latch locksthose used for locking rows, pages, or tablesand we'll use the generic word "object" to mean a row, a page, or a table.) The coexistence rules for locks are simple.
Table 15-1 shows these rules graphically. The lock rules for read and/or write permission are not so simple. It's often said that you need a shared or update lock to read, and you need an exclusive lock to write, but that's not always true. In this context, "read" means either "access" or "add to result set," while "write" means "data change"it doesn't imply "physical write to disk," though that can certainly happen. In simple terms, though, these are the rules. Table 15-1. Lock Modes and Coexistence
Usually a transaction reads an object before it tries to write the object, so an exclusive lock is normally an upgrade from a shared or update lock. For example, assume a transaction reads a table and gets a shared lock on Row #1. Later on, the transaction does a data change, so it changes the shared lock on Row #1 to an exclusive lock on Row #1. We'll look at how locks affect read/write permissions in greater detail later in this chapter.
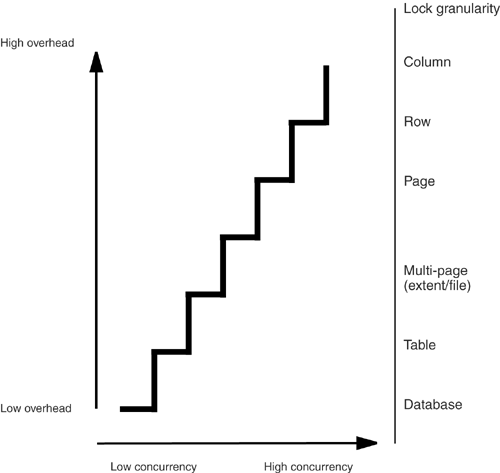
GranularityThe granularity of a lock refers to the size of the locked area. If you lock a row, the granularity is small. If you lock a table, the granularity is large. Both have advantages and disadvantages.
Consider the chart shown in Figure 15-3. It shows that, as lock granularity moves from the database level to the column level, overhead increases. (Overhead goes up because there are more locks to manage as you move from large to small granularity; i.e., there are more columns than tables, so column locks take extra work.) It also shows that concurrency increases as granularity gets smaller. Where do you want to be on Figure 15-3's line? Well, we made another chart to show what each DBMS actually allows; see Table 15-2. Figure 15-3. Concurrency versus overhead Notes on Table 15-2:
One way to encourage row-level locking is to ensure that there are few rows in a page. You can do this by shrinking the page size or by declaring that some of the page should be left blank at first with the DBMS's PCTFREE/FILLFACTOR setting. EscalationEscalation is the act of consolidating several real or potential small-grain locks into a single big-grain lock. Concurrency gets worse , but overhead gets better. DBMSs will escalate page locks to table locks if:
DBMSs also support explicit locking of tables, either with one of these non-standard SQL extension-statements: LOCK [ SHARED EXCLUSIVE ] TABLE <Table name> LOCK TABLE <Table name> IN [ SHARE EXCLUSIVE ] MODE LOCK TABLES <Table name> [ READ WRITE ] or a similar SQL extension, like Ingres's SET LOCKMODE, InterBase's RESERVED clause in the SET TRANSACTION statement, Microsoft's (hint) in the DML statements, and Sybase's LOCK {DATAROWS DATAPAGES ALLPAGES} clauses in the CREATE TABLE and ALTER TABLE statements. To keep it simple, we'll call all these options "the LOCK statement" throughout this book. The LOCK statement exists because programmers may be able to predict escalation better than the DBMS can. For example, suppose a transaction starts with an SQL statement that reads 100 rows and ends with a statement that reads 10,000 rows. In that case, it makes sense to issue a LOCK statement right at the beginning of the transaction so that the DBMS doesn't waste time making page locks that it will then have to escalate. For another example, suppose that during the night there are very few transactions. In that case, it also makes sense to issue a LOCK statement, because the overhead will go down without affecting concurrency (because there's no concurrency to affect). As a general rule, if there are no concurrent transactions, then throughput is not a problem, so you might as well concentrate on response time. It does not make sense to use a LOCK statement on a regular basis, though, because overhead is cheap until there are many thousands of lock records in memory. Of course, the first thing to do is tune your query to reduce concurrency problems. Explicit LOCK escalation is what you do if you can't tune further. Intent LocksIf Table1 contains Page #1, and there's already a shared lock on Page #1, then the Law of Contagion says another transaction can't get an exclusive lock on Table1 . [1] Implicitly, any small-grain lock implies a shared big-grain lock.
Most DBMSs turn this principle into an explicit rule: if there is one or more locks on pages belonging to a table, then there will also be a lock on the table itself, as a separate lock record. The usual name of the big-grain lock is intent lock . Thus, a small-grain lock implies a corresponding intent lock on all coarser granularity levels. You have no control over intent locks; we only mention them by way of reassurance. If you try to lock a table, the DBMS won't have to search umpteen dozen page locks looking for conflict; it only needs to look for an intent lock on the table. Intent locks are thus a way to lessen overhead, and it's up to the DBMS to decide whether to deploy them. Some DBMSs make intent locks for indexed searches only. Table 15-3 summarizes the level of support the Big Eight provide for locks and lock modes. The Bottom Line: LocksA shared lock on an object may coexist with any number of other shared locks, or with one update lock. Shared locks are for reading. Table 15-3. DBMSs, Lock Modes, and Granularity: A Summary
An update lock on an object may coexist with any number of shared locks, but not with another update lock nor with an exclusive lock. Update locks are for reading when updating is planned. An exclusive lock may not coexist with any other lock on the same object. Exclusive locks are for writing. Usually a transaction reads an object before it tries to write it, so an exclusive lock is normally an upgrade from a shared or update lock. Exclusive locks are the barriers to concurrency. Implicitly, any small-grain lock implies a shared big-grain lock. DBMSs make explicit locks, called intent locks, to reflect this. Thus, if a page of a table is locked, there will also be an intent lock on the table. You have no control over intent locks. The granularity of a lock refers to the size of the locked area. If you lock a row, the granularity is small. If you lock a table, the granularity is large. When you lock a row, the chances are that you won't block other transactions, thus concurrency is high. On the other hand, there are many locks, so overhead is greater. When you lock a table, the chances are that you will block other transactions, thus concurrency is low. On the other hand, there are only a few locks, so overhead is smaller. One way to encourage row-level locking is to ensure that there are few rows in a page. You can do this by shrinking the page size or by declaring that some of the page should be left blank at first. Escalation is the act of consolidating several small-grain locks into a single big-grain lock. Concurrency gets worse, but overhead gets better. Use the SQL-extension LOCK statement to force big-grain locks in situations where you can predict escalation. If there are no concurrent transactions, then throughput is not a problem, so you might as well concentrate on response time. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
EAN: 2147483647
Pages: 125