Conclusions ”So What's the Best Way to Provide High Availability for Your WebSphere Servers? The first thing to do in providing high availability for your WebSphere servers is to first leverage the built-in failover capabilities in WebSphere. Those capabilities vary with the version of WebSphere used, with V4 and V5 providing the greatest capability (e.g., leverage "server groups" in V4 and "clusters" in V5). Next, the application code should be designed for failure- related exception handling and recovery. After those two steps, then consider use of the two basic hardware approaches to high availability for WebSphere servers discussed in this chapter. The first approach is to use some sort of OS clustering (e.g., AIX HACMP or Microsoft MSCS) that provides failover with or without load balancing. The active/passive approach works well if high availability is required without high transaction rates. OS clustering systems that allow load balancing in addition to failover allow for greater transaction rates. Since OS clustering includes a disk array that is shared by Web servers, OS clustering is not an appropriate consideration for failover between different server farms. The second hardware approach relates to the case of having a high-volume system where a very scalable system is needed (e.g., the Web server for the Olympics); then some sort of Web sprayer (e.g. Network Dispatcher) provides a very good solution. It is a very scalable solution since it's easy to add Web servers to group of servers under the control of Network Dispatcher. For failover and load balancing between two widely separated server sites, IBM has used techniques such as Network Dispatchers and Cisco Distributed Directors. However, as discussed in this chapter, high availability can be solved with a continuum of techniques. A very basic way is to use a fault-tolerant server that has two of everything (Tandem computer or IBM zSeries). Highly fault-tolerant computers can be an expensive solution since half the components are always in standby mode. These days, almost all large Web servers do have many elements of fault-tolerant computers, such as RAID hard drives , redundant processors via Symmetric Multiprocessing (SMP), and redundant power supplies . Another basic solution would be to use round- robin DNS instead of devices such as Network Dispatcher. Since very high availability for Web servers ( especially those related to e-commerce) is becoming more and more important, we can continue to expect to see significant advances in the technology to support high availability for WebSphere servers. Net Dispatchers and HACMP for WebServer High Availability IP sprayers like Network Dispatcher provide a good method for both failover and load balancing for WebSphere systems that require high volume (high number of "hits" a minute) and high availability with failover. OS clustering such as AIX HACMP is a good way to have HA usually without load balancing. This section describes a high-volume, high-availability public access Web server system that IBM hosts for a customer at our Schaumburg, Illinois, server farm call an IBM Universal Server Farm (USF). IBM's USFs are very large server farms that host Web servers for many major IBM customers. The Web server system described here uses both Net Dispatchers and AIX HACMP. The diagram for this system is shown in Figure 14-7. The system consists of eight AIX servers accessed via the Internet plus numerous backend servers. Figure 14-7. Net Dispatchers and HACMP for Web server high-availability design. 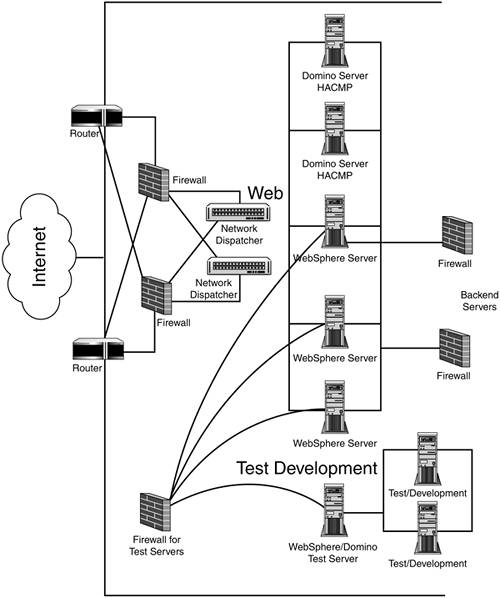
As indicated in the diagram, the eight AIX servers accessed via the Internet are made up of two Network Dispatchers for failover and load balancing: three large Web Sphere servers that serve as the main public Web server system, two Domino servers that share a hard drive system via HACMP, and one large test server for both WebSphere and Domino. The configurations for the AIX servers are given here. Notice that the Net Dispatchers are relatively small servers (only 256MB RAM, 1B4200MHz processor), while the WebSphere servers are quite large (e.g., 8GB RAM, 4B4500MHz processors).
-
7043 RS/6000 Model 43P -
1x200MHz processor -
256MB RAM -
2x4.2GB HDD (OS ”Mirrored) -
3x10/100Mbps Ethernet adapters -
Software: AIX 4.3.3, WebSphere Edge Server V1.0, and eNet Dispatcher 3.6.0.8
-
7026-M80 RS/6000 Model M80 -
4x500MHz processors -
8GB RAM -
2x9.1GB Ultra SCSI HDD (mirrored) for operating system -
4x18.2GB Ultra SCSI HDD (mirrored) for data -
6x10/100Mbps Ethernet adapters -
2xPower Supplies -
Software: AIX 4.3.3, IBM HIS v1.3.12.0, and WebSphere 3.5 Advanced Edition (both with Service Pack 2)
-
7025 RS/6000 Model F50 -
2x332MHz processors -
256MB RAM -
2x9.1GB HDD (OS “ Mirrored giving 9.1 GB usable) -
2x9.1GB HDD (logging “ Mirrored giving 9.1 GB usable) -
3x10/100Mbps Ethernet adapters -
2xAdvanced SerialRAID Adapter -
Software: AIX 4.3.3, HACMP 4.3, and Lotus Domino Server R5.0.8 | External Drive Array (shared by both Domino servers) | Qty. 1 |
-
1x7133-T40 Advanced SSA Subsystem -
4x9.1GB HDD (customer data ”mirrored giving 18.2GB usable) -
6x5 Meter Advanced SSA Cable Users accessing this very high transaction rate system are load balanced across the three large WebSphere servers via the two Net Dispatchers. Three large WebSphere servers are required to handle the heavy load. The three WebSphere servers in turn access the Domino system to handle such things as customer registration. The Domino servers are not required to be a high-volume system but are required to have high availability. Therefore, the two Domino servers use AIX HACMP for failover but do not have load balancing. Notice that each Domino production server is a relatively small machine with 512MB of RAM, 9.1GB (mirrored) hard drive for the OS, and 9.1GB (mirrored) hard drive for logging. The shared disk drive system for the Domino Application and Data consists of 4B49.1GB drives (mirrored), for an effective size of 18.2GB. The mirrored (RAID 1) aspect of the shared drive system gives the shared drive very high availability and reliability, which is necessary since the shared drive system is effectively a single point of failure. Because of HACMP clustering, there is only one Domino server name . Most of the time only the primary Domino server in the cluster is running. The secondary Domino server comes up only when the primary Domino server fails. Under failure conditions, the secondary server will come up, use the shared disk subsystem, restart the respective applications, and continue with the processes. It will use the same disk where the Domino data resides and the same IP address that the Domino server is using. Thus, the failover function is transparent to the WebSphere servers that access the Domino system. This Web server system using both Net Dispatchers and HACMP has been in place for over three years and has worked very well. |