A Review of Stacks and Their Uses
| for RuBoard |
Stacks are a basic data type in the computing world. They store items of data in ordered lists that are typically accessed from one end only in a last-in/first-out manner. A stack is similar to an inbox tray; items are placed on the top (" pushed ") and also removed from the top ("popped"). Figure 7.1 illustrates a simple stack.
Figure 7.1. The workings of a simple stack.
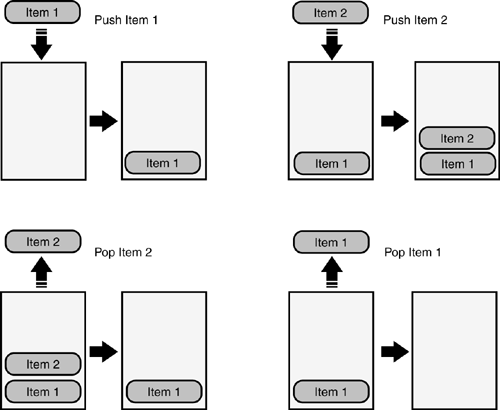
Due to their simplicity and low-level hardware support, stacks are extensively used in most computer architectures. They provide a convenient and efficient means of storing data, usually for short- term use, such as the local variables in a method call. Such stacks are often implemented in the computer architecture using a single hardware register to keep track of the top of the stack. This is known as a stack pointer (in the Intel architecture, the actual register is called ESP). When the stack is first initialized , the stack pointer is set to the stack base ”an address in memory indicating the lower boundary of the stack. As entries are pushed to or pulled from the stack, the stack pointer is raised or lowered as needed, always keeping track of where the most recent entry (the top of the stack) is located.
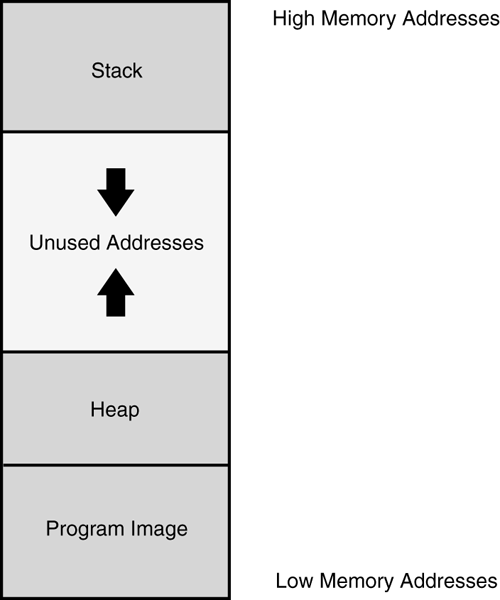
On most architectures, stacks grow from higher memory addresses to lower. This choice is largely arbitrary in today's systems, but it made sense before the advent of multithreading, when each program ran a single thread inside of its process space. The program itself would load into the process address space in the lower half of memory, followed by the heap ”a variable- sized region used to provide long-term memory allocation. The stack base would be set at the very top of the process's virtual address range. So while the heap grew up in memory, the stack would grow downwards. This gave the greatest flexibility in memory usage and avoided the problem of trying to determine heap or stack limits in advance. The diagram in Figure 7.2 shows a typical process memory layout utilizing this simplistic scheme.
Figure 7.2. The use of stacks in a simple process layout.
Modern operating systems utilize multiple threads, each thread requiring its own stack (because the data stored on a stack is generally private to a particular thread of execution). Thus, more complex schemes are used than just described. A detailed description of stack management techniques is beyond the scope of this book, but we now have enough background information to proceed.
So where am I going with this? Well, the stack can be used to store more than local variables. One of its most important uses is to track the return path through nested method calls. To illustrate this, let's define a couple of simple methods :
public static int Foo() { int result = Bar(123); return result + 1; } public static int Bar(int value) { int retval = value; return retval; } If we were to call Foo , Foo would in turn call Bar , take the result, increment it, and return the new number (124). When Foo makes its call to Bar , the execution environment needs to record where we were in Foo when the call was made so that it's possible to resume normal execution of Foo after Bar has done its work. This is achieved by pushing the resumption address (the address of the assembly code immediately following the call to Bar ) on the stack prior to making the call. After Bar has completed its work, it simply pops the return address off the stack and jumps to it, thus resuming execution in Foo where we left off.
If we were to halt Bar midway through its execution, we might see something as is shown in Figure 7.3 on the current thread's stack.
Figure 7.3. A typical stack trace.
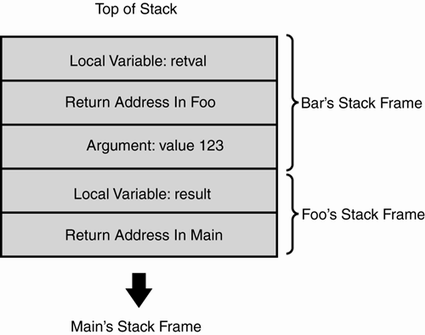
Notice how the stack forms layers of arguments, local variables, and return addresses for each method that the program is currently executing. Each of these layers is referred to as a frame. The layout of frames differs depending on architecture, operating system, and compiler (and sometimes even changes from method to method within a program), but the important point is that the system needs to record, at the very minimum, enough information to retrace its steps back from every nested method call that's been made.
You may have seen this information put to another use inside a debugger, where an examination of the stack allows the debugger to build and display the call stack (and possibly retrieve the values of local variables in each frame). To do this successfully, the debugger needs additional information from the compiler (in the form of extra debugging symbol files ” .pdb , .dbg , and .sym files in the Windows world). Alternatively, the debugger might have to make guesses as to how the stack frames are formatted, which is why debuggers sometimes give inaccurate or incomplete call stacks.
The .NET Framework retains enough information in the runtime image, and constructs its stack frames in such a careful fashion, that it is always possible to generate a correct and complete picture of the method frames on the stack. The act of generating this picture is referred to as a stack walk, and it's the central part of the implementation of a number of .NET Framework features.
| for RuBoard |
EAN: 2147483647
Pages: 235
- Article 200 Use and Identification of Grounded Conductors
- Article 332 Mineral-Insulated, Metal-Sheathed Cable Type MI
- Article 501 Class I Locations
- Example No. D2(b) Optional Calculation for One-Family Dwelling, Air Conditioning Larger than Heating [See 220.82(A) and 220.82(C)]
- Example No. D10 Feeder Ampacity Determination for Adjustable-Speed Drive Control [See 215.2, 430.24, 620.13, 620.14, 620.61, Tables 430.22(E), and 620.14]