Section 4.7. Criticism of Unicode
4.7. Criticism of UnicodeUnicode has been criticized on several accounts, from very different perspectives. The following discussion tries to summarize most of the arguments and comment on them. The presentation is not apologetic; it will admit that there are good points in the criticism. Criticism of lack of tools for indicating semantic structures is not discussed here. It is indirectly addressed in section "Why Not Markup in Unicode?" in Chapter 9. 4.7.1. Overall ComplexityAlthough the basic principles and structure of Unicode are simple, Unicode as a whole is complex, with difficult concepts, definitions, and algorithms. Is it too complex? The writing systems that people use are complex, especially when considered as a collection of systems that may be combined in texts. Some writing systems have myriads of characters; some use diacritic marks extensively; some use contextual forms for characters; and experts on different fields keep inventing new symbolisms. It was possible to make many old character codes much simpler than Unicode just because they ignore most of the reality of different writing systems, languages, and notation systems. Moreover, Unicode was not created in a vacuum. It was designed to deal with and to interoperate with a multitude of other character codes. The main implication was the introduction of compatibility characters, but this in turn required new concepts, definitions, and techniques such as compatibility decompositions and normalization forms. Another implication is that Unicode tries to preserve some of the internal structure of other codes in its coding system. The most obvious symptom of this is that the very first block in Unicode is the same as the ASCII set, with a mixed collection of characters. Unicode is complex because it deals with complex phenomena. In fact, much of the other criticism is aimed at Unicode's attempts at simplification of the complexity! But it remains true that if you are willing to limit yourself to one writing system with a fixed repertoire of characters, you could deal with it in a simpler and more efficient way. Many things could have been done differently, and perhaps in a simpler way. On the other hand, simplicity is relative: when the reality to be dealt with is complex, doing things the simple way in one respect may bounce back elsewhere. Moreover, as support for Unicode becomes more mature, most of the complexity will be hidden from almost all people, behind applications and subroutine libraries. 4.7.2. Inefficiency?Fairly often, people say that Unicode is too inefficient, since it uses two bytes for each character. We cannot afford doubling the size of each text file, and the duration of any text transfer, can we? There is also a more modern version of this claim, saying that Unicode needs four bytes for a character. As we have noted, and as will be discussed in detail in Chapter 6, Unicode has several encoding forms. Using UTF-8, for example, the size of a text file remains exactly the same as in ASCII, one octet (byte) per character, as long as the data consists of ASCII characters only. If you use other characters, then you "pay" for them: each of them requires two, three, or four octets. The inefficiency argument has a point, though. If you have Modern Greek text, for example, you can represent it in some 8-bit encoding, using just one octet per character. In any Unicode encoding, each Greek letter requires at least two octets. For languages like French, the effect is smaller, since the majority of characters used in French are ASCII characters. In processing character data in Unicode, inefficiency is caused either by the overhead of interpreting an encoding like UTF-8 or by the use of an encoding (such as UCS-2), which is simpler to process but wasteful in terms of storage. Moreover, if you really process character data in a Unicode-conforming way, you need to observe several mandatory rules, due to normative properties of characters. In reality, however, you can process Unicode data without making your application Unicode-conforming. To summarize, Unicode may imply some inefficiency as compared to simpler character codes, but usually the problem is small when compared with the gain. When the problem becomes important, various compression methods can be used. This may mean either general purpose compression or the special purpose compression schemes described in Chapter 6. 4.7.3. Is It Reasonable to Require Support for 100,000 Characters?The character repertoire of Unicode is large and expanding, and in most applications, only a small part thereof will be used. Wouldn't it be more reasonable to use, say, a code with 1,000 characters than to use a standard that requires support to 100,000 characters? After all, about 1,000 characters is sufficient for all European languages and the most common symbols. This criticism is based on a wrong assumption on the impact of the character repertoire. Surely Unicode contains more characters than most people will ever need. Many characters have been included for use in very limited environments, such as a language spoken by a few hundred people in the world, or an extinct language. But the number of characters is a much smaller burden than you might expect. Software that conforms to the Unicode standard need not be capable of rendering all Unicode characters. It need not contain a font that has glyphs for all characters. Not even all the fonts on a system combined need to cover all of Unicode. The conformance requirements in the Unicode standard say that an application may be ignorant of a character, as long as it does not destroy or distort characters that it does not understand. Unicode-enabled software need not even recognize all Unicode characters. You can implement systems that use Unicode but have been designed to process some collection of characters only. Thus, a program that supports Unicode may well support only a subset of Unicode characters. Upon reading a character outside the subset, it may indicate, in some suitable way showing a question mark in a box, its inability to display the character. It must not, however, simply omit the character or replace it by another character (like "?") when it reads data and passes it to further processing. The normative properties of characters constitute a burden, since an application is required to honor the properties even if it cannot render the characters. This, however, can be handled by using the machine-readable files available from the Unicode Consortium's web site. You are not supposed to hand code the processing of 100,000 different characters. Instead, you use the character's code number as an index to a table of properties, directly or via a system utility. 4.7.4. Cultural BiasUnicode has often been criticized for being culturally biased so that it favors languages of Western European origin, and specifically English. The history of character codes is largely a story of extensions, starting from a very limited set of characters that were suitable for some technical needs and for coarse writing of English. At each step, care was taken to guarantee efficient processing of already encoded characters, thereby often making the processing of new characters less efficient. 4.7.4.1. Lack of precomposed charactersDespite the large amount of assigned characters, Unicode does not contain all characters in all languages. Although almost all living languages are covered, some of their characters are covered only indirectly. For example, you cannot express the letter One could say that Unicode was once open to the inclusion of precomposed characters as needed, but was then closed, after all "important" languages had been covered. The coding space would surely allow the inclusion of many additional precomposed characters to meet the needs of other languages, but a policy decision says otherwise. This means a cultural bias, but the practical importance of the issue is small. Because of the needs of special notations (in mathematics, linguistics, etc.), Unicode needs a general mechanism of using combining diacritic marks. The same mechanism can be used to cover the needs of some natural languages. 4.7.4.2. East Asian languagesAlthough most assigned code positions are for characters used in East Asian languages, it has been claimed that Unicode still discriminates against such languages and the CJK (Chinese, Japanese, and Korean) characters. Originally, Unicode was squeezed into 16 bits at the cost of omitting a large number of less important CJK characters and "unifying" different characters into one. The key issue is Han unification i.e., the treatment of characters of Chinese origin. In a long historical process, those characters had been adopted by other peoples and adapted to their languages. This often involved changes (such as simplification) in the shapes of characters. In defining Unicode, the characters were analyzed, and if, say, a Chinese character and a Japanese (kanji) character were deemed variants of the same character, a single Unicode code point was allocated for it. The general idea was that information about language could be used to decide on the particular shape of the character, and to some extent, this idea really works. In practice, for Japanese text you choose a font that contains Japanese versions of CJK characters, etc. If the same text contains both Japanese and Chinese, font variation or language markup (perhaps resulting in font variation; see Chapter 7) might be used. However, Han unification has been regarded as an artificial and even barbaric method. We can perhaps understand the feelings of people who say so, if we think about the possibility that, had Unicode been designed in East Asia, perhaps the Latin, Cyrillic, and Greek alphabets would have been unified, making, for example, Latin "b," Cyrillic The issue of Han unification is not, however, a case of East Asian peoples against the Western world. Many arguments were presented by East Asians in favor of the unification. If Unicode contained several clones of many Han symbols, many people would find it less manageable to work with different East Asian languages. The inclusion of unified CJK characters into Unicode does not prevent the addition of language-specific variants in other code positions, but that would work against Unicode principles. 4.7.4.3. Favoring UTF-8Several documents specify UTF-8 as the preferred encoding for Unicode, especially in Internet contexts. Technically UTF-8 has many benefits especially for texts that contain mostly basic Latin letters and other ASCII characters, and it works relatively well for the additional Latin letters used in languages of West European origin. For other languages, it does not work that well. Even for Greek text, UTF-8 uses a lot of space: data size is, roughly speaking, double the size it would need in a suitable 8-bit encoding. The same applies to most languages that are written using a relatively small repertoire of non-Latin letters. For East Asian texts, it's worse. Some non-Unicode encodings for them are rather efficient, since they have been optimized for such use. For plain text in Chinese, even UTF-16 is more efficient than UTF-8. In UTF-16, all commonly used characters take two octets. In UTF-8, all characters except ASCII characters take at least two octets. Moreover, for fast character-by-character processing, UTF-8 needs to be internally transcoded into UTF-16 or some other representation where all or most characters occupy a fixed amount of octets. 4.7.5. Excessive UnificationThe unification principles and practices have raised many objections. Unification prevents people from making distinctions that they might wish to make at the level of plain text. In some situations, a distinction could be made, but not reliably. Problematic unification cases include the following (in addition to Han unification, which was discussed earlier):
Thus, it is impossible to make, for example, apostrophes look different from right single quotation marks simply by using different code numbers for them and a font in which they are different. According to the Unicode standard, you should code both of them the same way, as U+2019. You would have to use methods above the character level to have them display differently, and this would be too clumsy for many purposes. Yet, people might wish to make the distinction, perhaps because an expression like 'don't' would look better that way. However, unification can be justified on several grounds:
In programming, unification might seem to make things simpler, since there are fewer different characters to be considered. However, it also creates problems. For example, recognizing quotations from a piece of text becomes more difficult, because you cannot know, without extra analysis, that U+2019 is used as a quotation mark and not as an apostrophe. 4.7.6. Semantic Disambiguation Frowned UponUnification itself means that in many cases a character has two or more essentially different meanings. In addition, even when different meanings of a graphic symbol have been coded as separate characters, Unicode mostly does this only by defining compatibility characters. For example, the letter "I" is also used as a Roman numeral that means "one." You are supposed to use the Latin letter capital "I" in that meaning too, in Unicode. Although Unicode also contains the character Roman numeral one Ⅰ (U+2160), it is equivalent compatibility-wise to normal "I," and it has been included only for compatibility with other character code standards. You are not supposed to use it in new data. Consider the expression "Charles I." To a human reader, it is usually obvious that "I" is a numeral and shall be read as "the first." To a computer, this is not obvious at all. For example, a speech synthesizer probably reads "I" the way we read the pronouni.e., the same way as "eye." There are various ways to address such problems, but they can be complex or have an ad hoc nature (e.g., explicit pronunciation instructions), and they are not portable across data formats and applications. It would be better in many ways if we could disambiguate characters at the character level, by using, for example, Roman numeral one (U+2160) in "Charles I," or by using a separate character, rather than the Greek letter pi, when we mean π as a number (3.14...). Even in cases where such disambiguation is possible in Unicode, it is not recommended in the standard; rather, the standard advises against it. Therefore, we cannot expect most software make any use of it. The Unicode policy in this issue is understandable, however. Semantic disambiguation at the character level would require a large number of new characters, and most people would probably not want to make the distinctions, or would make mistakes in trying it. 4.7.7. Misleading Names of CharactersSome Unicode names of characters are misleading, misspelled, or even completely wrong, when considered as a descriptive name. This has caused many protests. It is understandable that when you find a character that you know well and you notice an error in its name, you want it to be fixed. Yet, the response is always: Unicode names are fixed and will never be changed. To take a relatively harmless example, the character U+2118 has been named "script capital p." However, it is neither script nor capital; whether it is a "p" is debatable: it is historically based on the letter, but as a Unicode character, it is defined as a letterlike symbol. By shape, it is a calligraphic variant of lowercase p, Some cases are more problematic, however. Some names for characters in scripts that are not well known in the Western world are just wrong: a name might be one that is commonly used to refer to a character in the script, but to another one. To make things worse, some of the bad names have been caused by cultural misunderstandings and by naming a character "from outside"i.e., by people who do not live in the culture in which the character is used. Some of these names have even been interpreted as insults. Moreover, reluctance to change the names has been interpreted as an even worse insult. This is an unfortunate situation, but the conclusion is that you should try to avoid getting offended either by the Unicode names or by requests to change them. It is futile to suggest changes to individual names. Suggestions to remove or deprecate the entire system of Unicode names might some day lead to something, but this is not likely. The alias names for characters, mentioned in the code charts, are often no better than the official Unicode names. For example, the commercial at @ (U+0040) has the annotation "Klammeraffe (common, humorous slang German name)," which is seldom useful to a serious English-speaking person who is uncertain of the character's identity. The solidus / (U+002F) is adequately explained by specifying "slash" as an alternate name, but the further explanation "virgule, shilling (British)" is misleading. The word "virgule" is rare, but "shilling" is worse. The solidus does not mean "shilling," though it was once used in British English to separate the shilling digits from the pence digits, as in 2/6 (two shillings and sixpence) or in 2/- (two shillings). The asterisk * (U+002A) has the annotation "star (on phone keypads)," but the use of the word "star" is not limited to phone contexts, and do we really need to identify all keypad symbols with characters? The capital letter "G" has the annotation "invented circa 300 B.C.E. by Spurius Carvilius Ruga, who added a stroke to the letter C." Interesting as this trivia might be, it is of little value in establishing the identity of the character in the modern world. Besides, it's not necessarily correct; the invention has also been attributed to Appius Claudius. Thus, the idea that the annotations could be used as boilerplate texts presented to users, when displaying information on characters, is not very feasible. Although the Unicode databases specify many properties of characters, there is no single and uniform source of information on their identity and meaning (usage). 4.7.8. Concepts and DefinitionsAlthough the Unicode standard contains parts that can be regarded as rather complex and theoretical, it has also been criticized for not being theoretical enough. It has been remarked that the fundamental concepts, even the concept of character, have been defined more or less vaguely and even inconsistently. The Unicode standard contains several different ingredients: the prose text, the code charts, the property tables, and different annexes and reports. For example, Unicode Technical Report #17, "Character Encoding Model," defines "character repertoire" as "an unordered set of abstract characters to be encoded" and adds that the word "abstract" means "that these objects are defined by convention." The question arises then: what is a character that is not defined by convention? It seems that the word "abstract" in the Unicode material is just an attribute that has been thrown in for different purposes in different contexts. In defense of Unicode, it needs to be said that Unicode's starting point was challenging. Many of its compromises, and confusions in terminology, come from several decades of a wilderness of "character sets" or "code pages." Unicode was designed to cover all characters in commonly used character codes, and it was natural to adopt terminology from older standards. Besides, Unicode disambiguates a lot by using terms like octet, code point, glyph, etc., instead of using the word "character" in a wide range of meanings as in ordinary language. The organization of the Unicode standard has been described as practically confusing, too. Information on characters is partly scattered around the standard. Moreover, the update procedures make it troublesome to find out the exact content of the standard at a given moment of time, if there are any updates since the last major version. 4.7.9. Illogical Division into BlocksFor historical reasons, many Unicode blocks are essentially copies of ranges of characters in other standards. This has led to somewhat strange allocations especially in the first two blocks. Many characters in Basic Latin (ASCII) and Latin-1 Supplement would logically belong to other blocks, such as General Punctuation. Thus, when you try to get an idea of the punctuation characters in Unicode, for example, you need to look at several blocks. If no previous character codes had been taken into account when defining Unicode, the use of the coding space would undoubtedly be different. It would be based on grouping by usage. The order of blocks would probably be different too. Now the CJK characters, for example, have been distributed into blocks in a manner that looks rather random. The reasons for making the first two blocks essentially copies of ASCII and ISO 8859-1 are both technical and cultural. Such an assignment helps in efficiency; consider how ASCII characters are representable each as one octet in UTF-8, still keeping UTF-8 simple. They also help in continuity, since people who have worked with ASCII and ISO 8859-1 can find their characters easily. The evolving nature of Unicode also makes some illogical assignments more or less necessary. New needs have led to allocation of blocks and ranges in a manner that cannot be smoothly integrated with old allocations. All the different extension blocks reflect the gradual incorporation of scripts and characters into Unicode. |
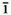 ̀ ("i with both a macron and a grave accent) as a single character in Unicode. It needs to be represented using combining diacritic markse.g., as
̀ ("i with both a macron and a grave accent) as a single character in Unicode. It needs to be represented using combining diacritic markse.g., as  followed by a combining grave accent. You can contrast this with the fact that all characters with diacritic marks as used in Western European languages, such as é and â, are included in Unicode as separate (precomposed) characters.
followed by a combining grave accent. You can contrast this with the fact that all characters with diacritic marks as used in Western European languages, such as é and â, are included in Unicode as separate (precomposed) characters. , and Greek β just glyph variants of a single Unicode character. After all, they have the same origin, and language information could have been used to select between the glyphs!
, and Greek β just glyph variants of a single Unicode character. After all, they have the same origin, and language information could have been used to select between the glyphs!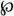 . By meaning, it is a conventional symbol for a certain mathematical function. Its thus a character with well-defined semantics, quite independent of the name. The name becomes a problem only if it is taken too seriously.
. By meaning, it is a conventional symbol for a certain mathematical function. Its thus a character with well-defined semantics, quite independent of the name. The name becomes a problem only if it is taken too seriously.