Understanding the Types of Replication
|
|
The three types of SQL Server replication are snapshot, merge, and transactional replication. Each type offers varying levels of autonomy and latency. Snapshot replication offers the highest possibly autonomy, but also the highest latency of the replication types. Transactional replication offers almost instantaneous updates, but a site doesn't have autonomy. Merge replication is right in the middle.
Each type of replication uses its own combination of replication agents, which allow it to perform specific tasks. Table 12-1 shows you the agents that each type of replication uses. There are others miscellaneous agents as well that perform cleanup functions.
| >Type of Replication | |||||
|---|---|---|---|---|---|
| Snapshot | Log Reader | Distribution | Queue Reader | Merge | |
| Snapshot Agent | * | * | * | ||
| Merge Agent | * | * | |||
| Transactional Agent | * | * | * |
Snapshot Replication
Snapshot replication provides the highest amount of autonomy for subscribers, but this feature is delivered at the price of latency. Snapshot replication takes a complete copy of the article and replicates it to the subscribers using BCP files for other SQL Server or .txt files for other data sources like Oracle. Before the data is loaded you can specify that the replication engine does any of the following:
-
Keep existing data
-
Drop the entire table and re-create it
-
Delete the table that matches the given filter
-
Delete all data from the table
Because snapshot replication uses a complete data refresh, it is essentially one-way. You cannot easily update a subscriber and expect the data to be migrated back to the publisher. It can be forced, but it is not advisable.
Snapshot replication is perfect for environments that must only be loaded on a periodic basis. During the subscriber setup, you specify how often the subscribers will be refreshed. Snapshot replication would be a good choice in the following scenarios:
-
A database that's used for running ad hoc reports against
-
A data warehouse
-
A remote office that needs an updated list of products that they cannot edit themselves
-
An HR application that only needs to update the branch offices weekly with new employees
Caution Since all the data from the publisher is being transferred to the subscriber in snapshot replication, it is important to make sure you have ample network bandwidth before deploying this solution. You also need to ensure that the subscriber is refreshed during nonoperational times since the data on the subscriber is most likely purged. The final consideration is to make sure that the replication folder has enough space. By default, this folder is \Program Files\Microsoft SQL Server\MSSQL\REPLDATA.
Snapshot replication uses two agents to perform its data movement: the snapshot agent and the distribution agent. The snapshot agent takes a picture of the data at a given point in time and prepares it for transfer. The distribution agent works to move snapshots and transactions from the publisher to the subscribers. Figure 12-2 shows a diagram of the way this works.
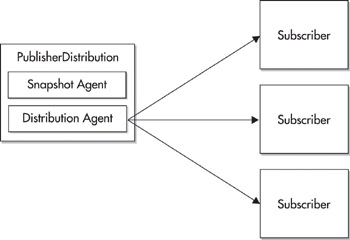
Figure 12-2: Snapshot replication model
If you are pushing data to subscribers, the distribution agent will generally run on your distributor. If you are pulling data, this agent will live on your subscribers.
Here's what happens when an article is ready to publish:
-
To ensure the data integrity, the snapshot agent creates a shared lock on the data in the article.
-
The schema for the article is sent to a work folder. Typically this folder is \Program Files\Microsoft SQL Server\MSSQL\REPLDATA. A set of subdirectories is created under this directory to hold the publication name and date stamp.
-
BCP files are created with the actual data for every table and an index file (.idx) is also created to re-create the indexes. For non-SQL Server destinations, .txt files are created for the data.
-
The snapshot agent releases the shared locks on the articles.
-
The data is transferred and applied on each subscriber.
| Note | If you have sites on the Internet subscribing to the publication, typically the snapshot folders for those subscribers are located in the \REPLDATA\FTP folder. |
Merge Replication
My favorite type of replication is merge replication, diagrammed in Figure 12-3. I prefer merge replication because of its sophisticated logic and its ability to recover from errors. Merge replication was first introduced in SQL Server 7.0 and allows you to decentralize your data from the central publisher paradigm. It allows you to modify the data on the publisher and on each of the subscribers and have the data merged. This is achieved through MS DTC and triggers. The triggers record the rows that need to be synchronized and then the merge agent replicates those changes to the publisher.
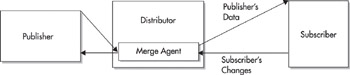
Figure 12-3: Merge replication model
| Caution | If you choose this type of replication, make sure you have plenty of space on the drive that holds the replication folder. |
When you configure merge replication, the merge agent takes the initial schema prepared by the snapshot agent and applies it to all subscribers. If a change occurs on the publisher, the change is replicated out to each subscriber at the next synchronize time. If a change is made on a subscriber, the change is sent to the publisher and then distributed to each of the other subscribers. Before the data is merged into the publisher, the change must first pass through logic on the distributor to determine if a conflict has occurred. A conflict can occur when two servers update the same row. The conflict resolver has logic that can be customized and preprogrammed to take care of this. Some of the logic you may want to invoke includes the following:
-
First or last server to update the record wins
-
A certain server always wins
-
Custom logic written in COM
Transactional Replication
Transactional replication provides the least amount of autonomy, but the highest amount of data consistency. It is the closest you can come to real-time replication in SQL Server. As a transaction is committed, it is sent to the distributor, which then sends the transaction to each of its subscribers. Transactional replication, which is diagrammed in Figure 12-4, works well with subscribers that have a constant connection to the network and to the distributor.

Figure 12-4: Transactional replication model
Transactional replication is very light on your network's bandwidth. If 20 rows are updated in a gigabyte database, only 20 rows are sent to the distributor. All logged changes occur through standard INSERT, UPDATE, and DELETE statements. Transactional replication uses the Log Reader to detect changes in the contents of the articles. If a change occurs, the INSERT, UPDATE, or DELETE statement is copied to the distribution database until the distribution agent applies it to all the subscribers.
| Note | SQL Server Personal Edition is not licensed to become a publisher in transactional replication. |
Bidirectional Replication
Bidirectional replication is the most complex type of replication and must be engineered with careful planning. With this type of replication, each system acts as a publisher, subscriber, and distributor, as shown in Figure 12-5.
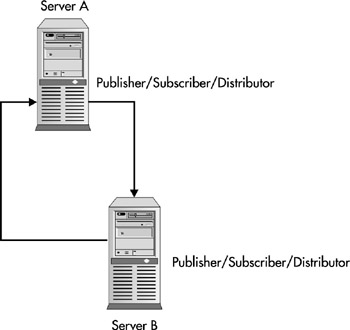
Figure 12-5: Bidirectional replication model
This type of architecture can complicate your topology, and leave your system in flux-some servers will have some data, while other servers have different pieces of data.
Bidirectional replication can also present the risk of sending your system into an endless loop. This could happen if a transaction were to occur on Server A and was replicated to Server B. Server B would see it has a new transaction and replicate it to Server A. Server A would then repeat the process until your system is finally brought to its knees. The workaround for this that I see most often is to add an ownership column to each table.
| Tip | Rather than try to create this type of system, it is better to use merge replication since the end result of bidirectional updates is still achieved. I'll cover this in the next section. |
|
|