7.2 System-level traffic engineering
|
|
7.2 System-level traffic engineering
Traffic engineering concerns the manipulation of network traffic in order to better optimize network resources (and possibly meet quality of service requirements). In Chapter 8 we deal with the network view of traffic engineering; here we are concerned primarily with traffic manipulation techniques within systems such as routers and switches. In practice the main techniques of interest include scheduling disciplines and bandwidth managers. Most routers provide facilities that enable network designers to exercise some control over packet. These techniques have particular value at the LAN-WAN interface, where speed mismatches and high-circuit tariffs mean that traffic flowing over the wide area interface needs to be actively managed, partly to make the best use of the bandwidth and partly to ensure that business- and mission-critical traffic gets priority access. As the processing capacity and resources available on modern routing and switching platforms have improved over the years, an increasingly sophisticated range of techniques has become available to control bandwidth allocation. Using these techniques the network designer can now exercise, with a high degree of granularity, the way in which applications are classified and prioritized.
7.2.1 Conservation law
It is important to consider at the outset that the fixed nature of circuit bandwidth means that prioritization has consequences. By improving the performance of one particular traffic flow over another, we are, by definition, penalizing other traffic on that circuit. This is referred to as the conservation law. More formally we can express this as follows [12]:
![]()
where pi is the product of the mean arrival rate and the mean service time for connection i, and qi is the waiting time at the scheduler for connection i. Note that this law applies to work-conserving scheduling systems (where the scheduler is idle only when the queue is empty) and is independent of the particular scheduling discipline. In practice this means that improving the mean delay for one particular flow results in increased average delays for other flows sharing that circuit.
7.2.2 Traffic-shaping techniques
Traffic shaping (sometimes called intelligent bandwidth management) is an admission control technique, whereby bandwidth is allocated to specified applications at the egress port of a switch or routing device (normally a wide area interface). The idea is to apply some control on the amount of bandwidth allocated to each application, thereby enabling mission- or business-critical applications to have guaranteed bandwidth and background applications (such as Web browsing) to be constrained within set performance bounds. Bandwidth managers are designed to understand the operating requirements of different applications and manage priority queues dynamically according to policy requirements (e.g., policy may dictate that SAP should always have priority over Web browsing and push applications). Implementations vary widely. Features may include the following:
-
The ability to identify application flows by address, port number (i.e., application), ToS bits, packet length, and so on.
-
The ability to create sophisticated traffic profiles (based as token bucket or other credit-based schemes), guaranteeing fixed bandwidth on a per-flow or a per-application basis, and allowing applications to burst in a controlled manner during off-peak periods.
-
The ability to dynamically allocate queue depth; for example, if videoconferencing session latency rises above some predefined threshold, the bandwidth manager can allocate more bandwidth. Advanced bandwidth managers may work on both outbound and inbound traffic and use more efficient algorithms to control congestion. Products may throttle outbound and inbound TCP traffic (e.g., by changing TCP window sizes and transmitting TCP acknowledgments at a controlled rate).
-
The ability to quench sources selectively in periods of congestion.
-
The use of automated discovery techniques to assess bandwidth management needs. The products can analyze which applications generate the most traffic and suggest an appropriate bandwidth management policy. The policy can then be fine-tuned to meet an organization's requirements.
Traffic shaping can be useful for applications where bandwidth costs are high and wide area circuit speeds are moderate (wide area interface between 56 Kbps and 384 Kbps). The level of bandwidth granularity offered may mean in practice that there is no added value for lower-speed circuits (e.g., if the implementation offers a minimum bandwidth allocation of 64 Kbps per application, then anything less than a 128-Kbps circuit cannot be subrated). Note that traffic shaping is a purely local bandwidth reservation technique; it has no end-to-end significance and so must be used in cooperation with broader strategies (such as RSVP) to provide service guarantees over an internetwork. If used in isolation, traffic shaping is only really applicable for point-to-point circuits or for private backbones (where you have complete control of all node configurations). It has questionable value when interfacing with a public backbone, unless specific SLAs are mapped directly onto the application flows at the point of egress. Where SLAs are mapped, traffic shaping could be used, for example, to enable an ISP to offer different service classes (e.g., gold, silver, and bronze). Without strict SLA mapping or tight integration with a higher-level QoS strategy, traffic enters a free-for-all fight for bandwidth as soon as it enters the backbone. It is also worth noting that not all traffic types can be managed (e.g., inbound ICMP and connectionless UDP packets may be unmanaged).
Traffic shaping functionality may be integrated directly into edge router and switching products or may be provided as a standalone platform placed between the routing node and the circuit. The class of products was pioneered by companies such as Packeteer (rather than managing queues to prioritize or reserve bandwidth, the approach they adopted was to manage TCP/IP flows proactively, by measuring the RTT of packets to assess the level of congestion and quenching senders of low-priority traffic in busy periods). There are now several other products available in this class, utilizing a variety of reservation, prioritization, scheduling and congestion control techniques, including Check Point (Floodgate), Nokia (integrated rate shaping software), and products from Allot Communications.
Token bucket
Token bucket is a widely used strategy for shaping traffic and forms part of the Integrated Services (IS) model. Token bucket defines a data-flow control mechanism where a sender adds characters (tokens) at periodic intervals into a buffer (bucket). New packet arrivals are queued and will be processed only if there are at least as many tokens in the bucket as the length of the packet. This strategy allows a precise control of the time interval between two data packets on the network. In practice it enables many traffic sources to be easily defined and provides a concise description of the load imposed by a flow.
The token bucket system is specified by two parameters: the token rate, r, which represents the rate at which tokens are placed into the bucket, and the bucket capacity, b, (see Figure 7.2). Both r and b must be positive. The parameter r specifies the long-term data rate and is measured in bytes of IP datagrams per second. The value of this parameter can range from 1 byte per second to 40 terabytes per second. The parameter b specifies the burst data rate allowed by the system and is measured in bytes. The value of this parameter can range from 1 byte to 250 gigabytes. The range of values allowed for these parameters is intentionally large for possible future network technologies (network elements are not expected to support the full range currently). In Figure 7.2, the bucket represents a counter that controls the number of IP octets that can be transmitted at any time. The bucket fills with octet tokens at a rate, r, up to the bucket capacity. Arrivals are queued and packets can be processed only if there are sufficient octet tokens to match the IP data size. When a packet is processed, the bucket is drained of the corresponding number of tokens. If a packet arrives and there are insufficient tokens, then the packet exceeds the Tspec for this flow and may be relegated to best-effort service. Over time the average IP data rate is r, and b is a measure of the degree of burstiness allowed.
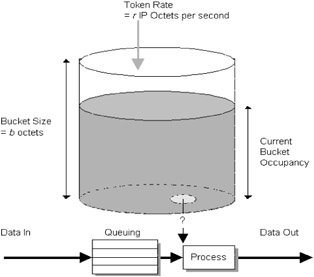
Figure 7.2: Token bucket scheme.
Traffic that passes the token bucket filter must obey the rule that over all time periods, T, the amount of data sent does not exceed rT + b, where r and b are the token bucket parameters. There are two additional token bucket parameters that form part of the Tspec: the minimum policed unit, m, and the maximum packet size, M. The parameter m specifies the minimum IP datagram size in bytes. Smaller packets are counted against the token bucket filter as being of size m. The parameter M specifies the maximum packet size in bytes that conforms to the Tspec. Network elements must reject a service request if the requested maximum packet size is larger than the MTU size of the link. Summarizing, the token bucket filter is a policing function that isolates the packets that conform to the traffic specifications from the ones that do not conform.
7.2.3 Scheduling techniques
A router is a closed system, and from the network perspective should be treated as a micronetwork in itself. When a packet enters the system, it is important to understand what happens to that packet as it is processed, classified, placed on output queues, and subsequently dispatched. When designing a network, it is imperative that you understand how each system deals with high-priority or time-sensitive traffic. For example, if the router becomes saturated with low-priority traffic, does it start discarding all traffic (including high-priority traffic) arriving at input ports, or does it make space for these packets by clearing out low-priority traffic from queues? How many queues does the router have? How is mission-critical traffic handled? How is delay- or jitter-sensitive traffic handled? This is an area where vendors offer differentiation, and many of the schemes offered are implementation specific. Aside from the obvious requirements for prioritizing mission- or business-critical traffic, increasingly network users are demanding granular quality of service guarantees for a whole range of applications and services. It is, therefore, essential to have control over flow classification and scheduling processes, and most high-end routers today implement a sophisticated range of queuing algorithms that can be configured to meet a particular policy requirement.
One of the dilemmas for router designers is that the more sophisticated the queuing strategy, the more likely that additional processing resources are consumed, and this also affects overall system throughput and response times. For many network applications (particularly multimedia) what we are striving for are minimum service guarantees; for example, it may be more important to have bounded latency and jitter than high throughput. No queuing discipline is right for all scenarios, so there is often a balance to be made between complexity and performance. Different queuing strategies are applicable, depending upon the service requirements of your network and the levels of congestion expected.
Another subtle issue for designers is that routing strategies tend to focus mainly on output queuing. If packets are allowed to enter a system freely (i.e., without any congestion control at the input side), prioritization can become ineffective. For example, a system that employs sophisticated techniques to ensure that control traffic (e.g., OSPF, VRRP, Spanning Tree, etc.) is always prioritized over user data at its output queues, may still fail to maintain network integrity if the system is besieged by user data packets at the input port. This can be a particular problem where large bursts of small packets originating on high-speed LANs are destined for lower-speed WANs. The designer must ensure that control packets are not dropped at the input port due to lack of buffer space or processing resource or aged out of internal queues due to other processing demands. If control traffic is not serviced in a timely manner, this may lead to network instability, which can further aggravate congestion.
Figure 7.3 illustrates a broad classification of the better-known strategies today. For the interested reader, [13] provides an excellent description of scheduling disciplines. We will concentrate in this section on a subset that is typically deployed on internetworking equipment today. We cover the following:
-
First-in/First-Out (FIFO) or First-Come/First-Served (FCFS) queuing
-
Priority queuing
-
Custom queuing
-
Weighted Round Robin (WRR)
-
Weighted Fair Queuing (WFQ)
-
Class-based Queuing (CBQ)
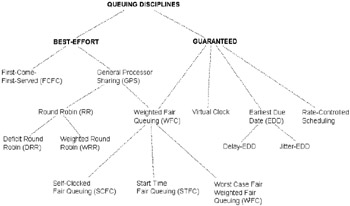
Figure 7.3: A classification of queuing disciplines.
Some of these queuing models are standard, and some are proprietary; however, network designers should be familiar with all of them. You should check with your router vendor about the queuing strategies supported by your specific platform.
FIFO queuing (or FCFS)
FIFO queuing is an open technology that offers simple store-and-forward functionality; it is often implemented as the most basic queuing strategy in a wide range of networked devices (it also has many other applications in IT). Packets are stored in a queue and serviced strictly in the order they arrive, so the next packet processed is always the oldest, and packets arriving at a full queue are discarded. FIFO queuing is the least demanding of system resources. The data structures used to implement FIFOs can, therefore, be extremely simple, and enqueue/dequeue operations are very fast (since we never have to search/insert/move entries, performance is constant, O[1]). FIFO queues require very little user configuration (at most you will be able to configure the queue size and maximum age timer for entries in the queue). The disadvantage is that FIFO queuing cannot accommodate prioritized traffic (packets wishing to minimize delays cannot jump the queue).
In practice even low-end routers that support FIFO queuing implement some form of prioritization, although this may not be visible to the user. Mission-critical routing and control traffic is typically placed in a separate FIFO queue and dispatched in preference to user data, as illustrated in Figure 7.4. This simple queuing model ensures that network integrity is maintained even under periods of heavy congestion (e.g., OSPF hello messages would always be dispatched on time). Note, however, that even with this enhancement there is no prioritization of application traffic and therefore no ability to offer QoS guarantees. As we will see in the remainder of this section, sophisticated queuing disciplines often achieve granular prioritization by implementing multiple FIFO queues.
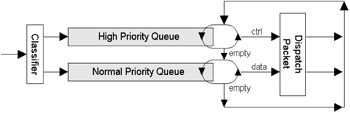
Figure 7.4: Enhanced FIFO queuing.
Priority queuing
Priority queuing is a widely used scheduling technique that enables the network designer to classify traffic by priority, directing traffic into different FIFO queues. Traffic may be classified according to a number of criteria (protocol and subprotocol type, receive interface, packet size, or source and destination IP address) and then queued on one of four (or possibly more) output queues (e.g., high, medium, normal, or low priority). High-priority traffic is always serviced first. If a priority queue overflows, excess packets are discarded and source quench messages may be sent to slow down the packet flow (if supported by that protocol).
You may be able to adjust the output queue length on priority queues. Figure 7.5 illustrates the principles of priority queuing. With some implementations additional fine-tuning may be possible on designated protocols (e.g., IP ToS bits or IBM Logical Unit [LU] addressing). This enables more granular control for mission-critical or time-sensitive applications, such as IBM SNA, multimedia, or SAP environments.
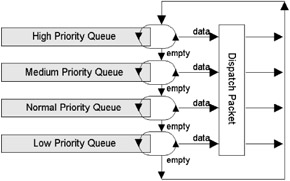
Figure 7.5: Priority queuing.
Priority queuing is useful on low-speed serial links where the WAN link may be frequently congested. If the WAN link never becomes congested, then this strategy could be overkill. Priority queuing introduces a problem in that packets classified onto lower-priority queues may get treated unfairly, either by not servicing them in a timely manner or by ignoring them so long that they are aged out of the queue and never get serviced (generally forcing a retransmission by the source).
Custom queuing
Custom queuing is a technique promoted by Cisco that is designed to address the unfairness problem with priority queuing; it is designed to cope with a wider range of applications with different bandwidth or latency requirements. Different protocols can be assigned different amounts of queue space, and a set of queues (up to 17 in Cisco's IOS) is handled in a round-robin manner (as shown in Figure 7.6). The first queue (Queue 0) is serviced first and is reserved for control messages (such as routing or signaling protocols); the remaining queues are user configurable. Priority is promoted by allocating more queue space to a particular protocol. Each queue has a transmission window to stop any particular protocol from hogging the system indefinitely. The effect of custom queuing is to reserve bandwidth for defined protocols. This enables mission-critical traffic to receive a guaranteed minimum amount of bandwidth at any time while remaining fair to other traffic types. For example, you could reserve 45 percent of bandwidth for SNA, 25 percent for TCP/IP, 15 percent for NetWare, and the remaining 15 percent to be shared among other protocols. Although bandwidth is reserved, it can be made available to lower-priority traffic if it is currently unused.
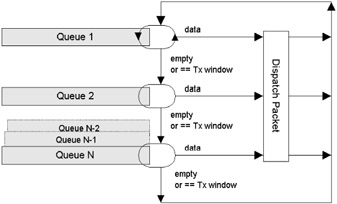
Figure 7.6: Custom queuing.
Custom queuing is designed for environments that wish to ensure a minimum service level for a number of applications and is commonly used in internetworking environments where multiple protocols are present. Custom queuing guarantees a minimum bandwidth for each application at the point where links become congested. Many organizations also use this strategy for delay-sensitive SNA traffic, because of these bandwidth reservation capabilities. Custom queuing is ultimately fairer then priority queuing but not so strong when prioritizing a single dominant application.
Weighted Round Robin (WRR)
Weighted Round Robin (WRR) is an open technology and one of the simplest scheduling algorithms. It works by dispatching packets from priority queues in a round-robin manner, taking a fixed number from each according to the priority weighting configured. For example, if three priority queues are established (high, medium, and low), and a weighting of 5:2:1 is defined, then each dispatch cycle takes five packets from the high priority queue, two from the medium-priority queue, and one from the low-priority queue. While fast and effective, at times of congestion incoming packets may be discarded because no buffer space is available in the appropriate queue (sometimes referred to as tail dropping). Lost packets typically lead to retransmissions, further aggravating the congestion problem. WRR is implemented in products from Cabletron, Extreme Networks, Lucent, and 3Com.
Weighted Fair Queuing (WFQ)
WFQ uses a flow-based queuing algorithm based on Time-Division Multiplexing (TDM) techniques to divide the available bandwidth among flows that share the same interface. WFQ is an open technology and is implemented in several commercial switching and routing products (note that an algorithm called Packet by Packet Generalized Processor Sharing [PGPS] is identical but was developed independently, so we will simply use the term WFQ). One of the chief aims of WFQ is to avoid bandwidth starvation for low-priority traffic (a problem with most other priority-based scheduling strategies in times of congestion).
WFQ works by computing the time a packet would require to complete if a GPS server had been used, and then tags packets with these data (the finish number). This tag determines the priority order for scheduling. WFQ is designed to ensure that response times are consistent for both high-and low-volume traffic by allocating a time slice for each flow and processing them in a round-robin fashion. For example, if there are 30 active FTP sessions (high volume) and 50 active Telnet sessions (low volume), each flow identified will receive the same time slice of processor activity in turn, regardless of the arrival rate. Additional bandwidth for specific flow types is assigned by adjusting weights based on criteria such as the IP precedence/ Type-of-Service (ToS) bits. Flows with higher weights are processed more frequently. The use of weights allows time-sensitive traffic to obtain additional bandwidth, so a consistent response time is guaranteed under heavy traffic.
WFQ provides an algorithm to classify data streams dynamically and then sort them into separate logical queues. The algorithm uses discriminators based on the network layer information available (e.g., IP source and destination address, protocol type, port numbers, and ToS bits). Using this information WFQ could differentiate two Telnet sessions, for example, and then assign them to different queues. Note that some non-IP protocols are much harder to classify; for example, SNA sessions cannot be differentiated, since in DLSw+ SNA traffic is multiplexed onto a single TCP session (similar to IBM's Advanced Peer to Peer Networking [APPN], SNA sessions are multiplexed onto a single LLC2 session). The WFQ algorithm treats such sessions as a single conversation. For this reason, this algorithm is not generally recommended for SNA environments either with DLSw+ TCP/IP encapsulation or APPN.
With WFQ, round-trip delays for the interactive traffic are predictable. WFQ also has many advantages over priority queuing and custom queuing. Priority queuing and custom queuing require the use of access lists; the bandwidth must be preallocated, and priorities have to be predefined. WFQ classifies individual traffic streams automatically without these administrative overheads. For the interested reader, WFQ and two other variations of WFQ: Self-Clocked Fair Queuing (SCFQ) and Start-Time Fair Queuing (SFQ) are more formally described in [13]. WFQ is implemented in commercial products from Cabletron, Extreme Networks, and 3Com.
Class-Based Queuing (CBQ)
Class-Based Queuing (CBQ) is an open technology defined by leading members of the Internet community. CBQ works by classifying received traffic and then shaping that traffic prior to dispatch according to user criteria. Once traffic has been classified, it is shaped according to user-defined criteria. Traffic shaping is where specific resources such as bandwidth and burst times are allocated to traffic based on classification, as follows:
-
For Web-surfing applications a traffic class could be defined with a maximum bandwidth and the ability to burst above this bandwidth only if spare capacity is available, as illustrated in Figure 7.7. Without some form of traffic shaping at the application level, the only way to deal with this issue is to overprovision the network by adding more bandwidth.
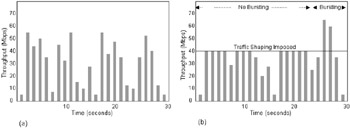
Figure 7.7: The effects of an applied CBQ class to a Web-browsing application. In (a) the traffic is unconstrained and has regular bursts above 50 Mbps, affecting other services. In (b) the traffic class applied limits the maximum available bandwidth to 40 Mbps. -
A router could allocate specific wide area circuit bandwidth to different classes of traffic. Classes could be constructed for TCP and UDP traffic, multicast traffic, and for traffic originating from particular sites. The multicast traffic class could be configured to use more than its allocated bandwidth in periods where there is spare circuit capacity available.
In the absence of reservation protocols such as RSVP, network designers can use fields in the packet headers to manually classify traffic. For example, we could use the IP source and destination address, protocol field, and ToS bits. We might also use criteria such as groups of addresses, subnets, domain names, interface data, or even individual applications (e.g., by TCP/UDP port). If reservation protocols are used with CBQ, then flows could dynamically request reservations for higher-priority service (in fact, CBQ has been shown to work well with RSVP [14]).
One of the major strengths of CBQ is its ability to dedicate bandwidth to classes while independently assigning priorities to those classes. For example, a router could have a high-priority real-time class and a lower-priority non—real-time class, each with a different bandwidth allocation. Packets in the real-time class will receive priority scheduling as long as sufficient bandwidth is available and as long as the arrival rate for that class does not exceed its allocated bandwidth. CBQ is a powerful and extremely flexible traffic management tool. For example, one possibility would be to have a single high-priority class for controlled load traffic; for flows to use RSVP as the reservation protocol; and for the router to use admission control algorithms, statistical multiplexing of controlled load traffic in a single class, and FIFO queuing within the controlled load class. This scenario is discussed in [15]. Another possibility would be to use CBQ with RSVP for guaranteed service, with a new CBQ class created at the router for each flow that is granted guaranteed service. This scenario is discussed in [16]. The interested reader is referred to [14] for further information. CBQ is implemented in commercial products from Cabletron and 3Com.
7.2.4 Congestion avoidance
So far we have discussed techniques for classifying and scheduling packets that are received by a network system. These techniques work well only if congestion-control mechanisms are in place to avoid overloading the system. Of particular interest are a number of congestion-avoidance techniques [17], as follows:
-
DECbit is a binary feedback scheme for congestion avoidance [18]. DECbit is an early example of congestion detection at the gateway (i.e., router); DECbit gateways give explicit feedback when the average queue size exceeds a certain threshold.
-
Random Early Detection (RED) is a selective discard technique similar to DECbit. Some aspects of RED gateways are specifically targeted at TCP/IP networks, where a single marked or dropped packet is sufficient to indicate congestion to the Transport Layer. This differs from the DECbit, where the Transport Layer protocol computes the fraction of arriving packets that have the congestion indication bit set [19].
-
Source-based congestion avoidance is a technique applicable to end systems (including ICMP source Quench and TCP Vegas).
In the following text, we discuss the application of RED, which is used commercially in routers and switches for TCP/IP internetworks.
Taildrop
Although scheduling techniques work well in managing packet flows through a network system, they suffer a common problem during periods of congestion. Since buffer space is a finite resource, under very heavy loads all space will be allocated and new arrivals must be discarded indiscriminately (i.e., without regard for different classes of service). This phenomenon is referred to as taildrop. The problems associated with taildrop are potentially serious, especially for TCP/IP networks; they are as follows:
-
All mission- or business-critical traffic is dropped at the input port regardless of whether or not lower-priority traffic is currently enqueued.
-
When packets are discarded, TCP goes into a slow-start phase. Since packets are dropped indiscriminately, many sessions are affected. While this relieves the congestion, it is effectively like pulling on the emergency break every time you approach a red light.
-
Since many TCP sessions may be affected, and all go into slow-start, this results in a situation called global synchronization, where dramatic oscillations of both congestion and low utilization occur, rather than a graceful easing off.
-
Congestion is likely to be caused by one or more bursty traffic sources. Since packets are discarded during congestion periods, these sources are unfairly penalized. Taildrop is effectively biased against bursty senders.
For TCP this kind of bursty packet loss is particularly damaging, leading to overall inefficiency in TCP throughput for all network users. Furthermore, this problem cannot be addressed by simply increasing the memory available for queues, especially if the traffic profile is self-similar. The chaotic nature of self-similar traffic means that traffic is likely to burst beyond resource limits regardless [1]. We therefore need a way to intelligently preempt congestion that backs off senders gracefully.
RED gateways
Random Early Detection (RED) is a technique designed to address the problems associated with taildrop in TCP/IP networks and provide a mechanism for controlling average delay. It is modeled on the simple FIFO queue and can be implemented with most routing or switching nodes. The term RED gateway is generally applied to a router running the RED algorithm ([19, 20], although in practice other devices could just as easily implement the technique.
RED works by monitoring the queue length, and when it senses that congestion is imminent, senders are notified to modify their congestion window. Since there is no way to explicitly inform all senders that congestion is pending (since senders may be using a variety of protocol stacks) and some senders cannot be trusted to back off, RED notifies senders implicitly by discarding packets at random sooner than they would normally need to be. Note that this is not the same as dropping all packets during congestion; the result is that some senders are forced to retransmit lost packets and back off. For example, this forces TCP to decrease its congestion window sooner than it would normally have to. Note that other protocols may respond less well to packet loss (e.g., Novell NetWare and AppleTalk are not sufficiently robust in this regard); therefore, you should not use RED if a high proportion of the traffic is composed of these protocols.
Operation
RED drops packets from the queue based on the queue length and a discard probability. Whenever the queue length exceeds a drop level and the next packet arriving has a drop probability greater than some predefined threshold, the packet is dropped (this is called a random early drop). RED computes the average queue length, Qavg, using a weighted running average, as follows:
-
Qavg = (1 - W) × (Qavg + Weight × Qlast
where
-
0< W< 1
-
Qlast is the length of the queue when last measured.
In practice W (i.e., weight) is set to 0.002, and the queue length is measured at every new packet arrival. RED uses two queue length thresholds (THmin and THmax) to determine whether or not to queue a packet, according to the following logic:
if (Qavg <= THmin) queuePkt (); else if ((Qavg > THmin) && (Qavg < THmax) ) { P = dropProbability(); if ( dropArrival(P) ) discardPkt (); else queuePkt(); } else if (Qavg >= THmax) discardPkt (); So, if the average queue length is lower than the minimum threshold, all new arrivals are queued as normal, and if the average queue length exceeds the maximum threshold then all new arrivals are dropped. Packets arriving when the queue length is between the two thresholds are dropped with probability P, where P is calculated as follows:
-
Ptmp = Pmax ×(Qavg- THmin)/(THmax - THmin)
-
P=Ptmp/(l-Narr×TempP)
Narr represents the number of new arrivals that have been successfully queued while Qavg was between the two thresholds. Pmax is typically set to 0.02 [19], so when the average queue length is midway between the two thresholds the router starts to drop 1 in every 50 packets. The difference between the two thresholds should ideally be greater than the increase in the average queue length in one RTT, and THmin should be set sufficiently high to enable high link utilization to be sustained in bursty traffic conditions. In practice the probability of dropping a packet for a particular flow is roughly proportional to the amount of bandwidth that flow is consuming at the router.
The RED algorithm is implemented in a number of commercial products, including those from Cabletron and Cisco. Cisco implements variations of RED, such as Weighted Random Early Discard (WRED) in its edge routing products (where WRED generally drops packets selectively based on IP precedence) and VIP-Distributed WRED for high-speed backbone platforms. Note that there may be performance issues when mixing different queuing and congestion avoidance schemes. For further details about RED, the interested reader is referred to [19, 21].
|
|