The Tree Model
Let's now look at the tree model used in XSLT, in a little more detail. This is a summary of the model; it is described in greater detail in Chapter 2 of XPath 2.0 Programmer's Reference .
The XSLT tree model is similar in many ways to the XML DOM. However, there are a number of differences of terminology and some subtle differences of detail. I'll point some of these out as we go along.
XML as a Tree
At a simple level, the equivalence of the textual representation of an XML document with a tree representation is very straightforward.
| |
Consider the following document.
<definition> <word>export</word> <part-of-speech>vt</part-of-speech> <meaning>Send out (goods) to another country.</meaning> <etymology> <language>Latin</language> <parts> <part> <prefix>ex</prefix> <meaning>out(of)</meaning> </part> <part> <word>portare</word> <meaning>to carry</meaning> </part> </parts> </etymology> </definition>
We can consider each piece of text as a leaf node, and each element as a containing node, and build an equivalent tree structure, which looks like Figure 2-4. It shows the tree after the stripping of all whitespace nodes: for discussion of this process, see Chapter 3, page 138. In this diagram each node is shown with potentially three pieces of information: in the top cell , the type of node; in the middle cell, the name of the node; and in the bottom one, its string value. For the root node and for elements, I show the string value simply as an asterisk: in fact, the string value of these nodes is defined to be the concatenation of the string values of all the element and text nodes at the next level of the tree.
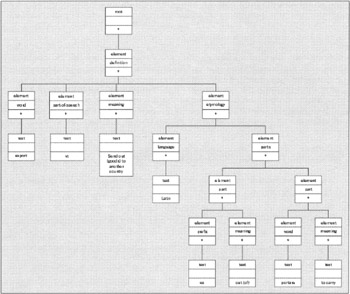
Figure 2-4
| |
It is easy to see how other aspects of the XML document, for example attributes and processing instructions, can be similarly represented in this tree view by means of additional kinds of node.
At the top of a tree that represents a well- formed XML document, there is a document node. This performs the same function as the document node in the DOM model in that it doesn't correspond to any particular part of the source document, but you can regard it as representing the document as a whole. The children of the document node are the top-level elements, comments, processing instructions, and so on.
| Important | The root node is not an element. In some specifications, the outermost element is described as the root of the document, but not in XPath or XSLT. In the XPath model, the root is the parent of the outermost element; it represents the document as a whole. In XSLT 1.0, the document node was referred to as the root node. The terminology has changed, because trees that exist temporarily in the course of stylesheet execution can now have a different kind of node (for example, an element or an attribute node) as their root node. |
The XSLT tree model can represent every well-formed XML document, but it can also represent structures that are not well formed according to the XML definition. Specifically, in well-formed XML, there must be a single outermost element containing all the other elements and text nodes; this element (the XML specification calls it the document element, though XSLT does not use this term ) can be preceded and followed by comments and processing instructions, but cannot be preceded by other elements or text nodes.
The XSLT tree model does not enforce this constraint; a document node can have any children that an element might have, including multiple elements and text nodes in any order. The root might also have no children at all. This corresponds to the XML rules for the content of an external general parsed entity, which is a freestanding fragment of XML that can be incorporated into a well-formed document by means of an entity reference. I shall sometimes use the term well balanced to refer to such an entity. This term is not used in the XSLT specification; rather, I have borrowed it from the rarely mentioned XML fragment interchange proposal ( http://www.w3.org/TR/WD-xml-fragment ). The essential feature of a well-balanced XML fragment is that every element start tag is balanced by a corresponding element end tag.
| |
Here is an example of an XML fragment that is well balanced but not well formed, as there is no enclosing element.
The <noun>cat</noun> <verb>sat</verb> on the <noun>mat</noun>. Figure 2-5 shows the corresponding XPath tree. In this case it is important to retain whitespace, so spaces are shown using the symbol — .
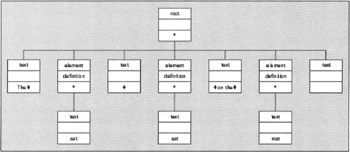
Figure 2-5
The string value of the root node in this example is simply «The cat sat on the mat. » .
In practice, the input and output of the transformation will usually be well-formed documents, but it is very common for temporary trees constructed in the course of processing to have more than one element as a child of the root.
| |
Nodes in the Tree Model
An XPath tree is made up of nodes. There are seven kinds of nodes, corresponding fairly directly to the components of the source XML document.
| Node Type | Description |
|---|---|
| Document node | The document node is a singular node; there is one for each document. Do not confuse the document node with the document element, which in a well-formed document is the outermost element that contains all others. |
| Element node | An element is a part of a document bounded by start and end tags, or represented by a single empty-element tag such as <TAG/> . |
| Text node | A text node is a sequence of consecutive characters in a PCDATA part of an element. Text nodes are always made as big as possible: there will never be two adjacent text nodes in the tree, because they will have been merged together. In DOM terminology, the text nodes are normalized. |
| Attribute node | An attribute node includes the name and value of an attribute written within an element start tag (or empty-element tag). An attribute that was not present in the tag, but which has a default value defined in the Document Type Definition (DTD), is also represented as an attribute node on each separate element instance. A namespace declaration (an attribute whose name is xmlns or whose name begins with xmlns: ) is, however, not represented by an attribute node in the tree. |
| Comment node | A comment node represents a comment written in the XML source document between the delimiters «< ! - - » and «--> » . |
| Processing instruction node | A processing instruction node represents a processing instruction written in the XML source document between the delimiters «? » and «?> » . The PITarget from the XML source is taken as the node's name and the rest of the content as its value. Note that the XML declaration <?xml version="1.0"?> is not a processing instruction, even though it looks like one, and it is not represented by a node in the tree. |
| Namespace node | A namespace node represents a namespace declaration, except that it is copied to each element that it applies to. So each element node has one namespace node for every namespace declaration that is in scope for the element. The namespace nodes belonging to one element are distinct from those belonging to another element, even when they are derived from the same namespace declaration in the source document. |
Each node can have a number of properties. Some of these are applicable to some kinds of nodes and not others (for example, elements and attributes have names , but text nodes do not), but for simplicity, the model is defined so that all properties are defined for all nodes, using a default value where nothing else makes sense.
The following table summarizes the properties of a node. There is more information on all these properties in Chapter 2 of XPath 2.0 Programmer's Reference .
| Property | Description |
|---|---|
| Name | Elements and attributes have namespace-qualified names. The name is in two parts: a namespace URI (which may be null) and a local name. These can be obtained separately, using the functions namespace-uri() and local-name(), or together, in the form of an xs:QName value, using the function node-name(). The name() function attempts to reconstruct the node's name in the form of a lexical QName, by finding a prefix that is associated with the node's namespace URI. Processing instruction and namespace nodes also have names; in these cases this consists of a local name only. The name of a namespace node represents the namespace prefix. Document nodes, comment nodes, and text nodes are unnamed. |
| String value | Every node has a string value.
The string value of a node can be obtained using the string() function in XPath. |
| Typed value | The typed value of a node represents the value after schema validation. For example, if the value of an element or attribute is described in the schema as a list of integers, then the typed value will be a sequence whose items are integers. For nodes other than elements and attributes, the typed value is the same as the string value. The typed value of a node can be obtained using the data() function in XPath, but this is rarely used explicitly because most operations that need access to the typed value extract it from the node automatically, through a process called atomization. |
| Type annotation | Element and attribute nodes have a type annotation, which is set by a schema processor when the node is validated, and indicates the schema type definition that the value conforms to. This may be a simple type or a complex type. For nodes that have not been validated , the type is set to xdt:untyped in the case of elements and xdt:untypedAtomic in the case of attributes. The type annotation of a node is not available directly to applications, but many operations on nodes depend on it. |
| Base URI | Document nodes, element nodes, and processing instructions have their own base URI, derived from the URI of the XML entity in which they were originally contained. Other nodes inherit their base URI from that of their parent node. The base URI may be overridden using the xml:base attribute. The base URI of a node is used when resolving a relative URI contained in that node (such as an «href » attribute in XHTML). |
| Parent | Every node except a document node can have a parent. In the XPath 2.0 model, however, other node kinds are not required to have a parent; any kind of node can also exist without a parent. |
| Children | Document nodes and element nodes can have children. In both cases, the children may be any sequence of elements, text nodes, comments, and processing instructions. The attributes of an element are not considered to be children of the element, even though the element is considered to be the parent of the attributes. For other nodes, this property is always an empty sequence. |
| Attributes | Element nodes can have attributes. For elements, this property is a sequence of zero or more attribute nodes; for other kinds of node, the property is always empty. The namespace declarations on an element are not considered to be attributes, and are not accessible via this property. The order in which attributes appear is not predictable. |
| Namespaces | Element nodes always have one or more namespace nodes. This property defines all the namespaces that are in scope for an element, whether they were declared on this element or on an outer element. There is always at least one namespace node, because the XML namespace is in scope for every element. For nodes other than elements, the set of namespace nodes is always empty. |
Let's look in more detail at one particular feature of this model, the handling of names and, in particular, the use of namespaces.
Names and Namespaces
XSLT and XPath are designed very much with the use of XML Namespaces in mind, and although many source documents may make little or no use of namespaces, an understanding of the XML Namespaces Recommendation (found in http://www.w3.org/TR/REC-xml-names ) is essential.
Expanding on the description in Chapter 1 (page 22), here's a summary of how namespaces work:
-
A namespace declaration defines a namespace prefix and a namespace URI. The namespace prefix needs to be unique only within a local scope, but the namespace URI is supposed to be unique globally. Globally, here, really does mean globally: not just unique in the document, but unique across all documents around the planet. To achieve that, the advice is to use a URI based on a domain name that you control, for example http://www.my-domain.com/namespace/billing . XSLT doesn't impose any particular rules on the URI syntax, though it's a good idea to stick to a standard URI scheme in case this ever changes; in most of our examples we'll use URIs beginning with «http:// ».
-
To avoid any ambiguity, it's also best to avoid relative URIs such as «billing.dtd ». After a fierce debate on the issue, W3C issued a belated edict deprecating the use of relative namespace URIs in XML documents, and stating that the effect of using them is implementation defined. What this actually means is that they couldn't get everyone to agree. However, as far as most XSLT processors are concerned , the namespace URI does not have to conform to any particular syntax. For example, «abc », «42 », and «?!* » are all likely to be acceptable as namespace URIs. It is just a character string, and two namespace URIs are considered equal if they contain the same sequence of Unicode characters.
-
The namespace URI does not have to identify any particular resource, and although it is recommended to use a URL based on a domain name that you own, there is no implication that there is anything of interest to be found at that address. The two strings «c:\this.dtd » and «C:\THIS.DTD » are both acceptable as namespace URIs, whether or not there is actually a file of this name; and they represent different namespaces even though when read as filenames they might identify the same file.
The fact that every stylesheet uses the namespace URI http://www.w3.org/1999/XSL/Transform doesn't mean that you can't run a transformation if your machine has no Internet connection. The name is just an elaborate constant: it's not the address of something that the processor has to go and fetch.
-
A namespace declaration for a non-null prefix is written as follows. This associates the namespace prefix my-prefix with the namespace URI http://my.com/namespace .
<a xmlns:my-prefix="http://my.com/namespace"> -
A namespace declaration may also be present for the null prefix. This is known as the default namespace. The following declaration makes http://your.com/namespace the default namespace URI.
<a xmlns="http://your.com/namespace"> -
The scope of a namespace declaration is the element on which it appears and all its children and descendants, excluding any subtree where the same prefix is associated with a different URI. This scope defines where the prefix is available for use. Within this scope, any name with the given prefix is automatically associated with the given namespace URI.
-
A name has three properties: the prefix, the local part, and the namespace URI. If the prefix is not null, the name is written in the source document in the form prefix:local part: for example in the name xsl:template, the prefix is xsl and the local part is template. This format is referred to as a lexical QName. The namespace URI of the name is found from the innermost element that carries a namespace declaration of the relevant prefix. (In theory this allows you to use the same prefix with different meanings in different parts of the document, but the only time you'll ever need to do this is if you assemble a document from pieces that were separately authored .)
-
The XML Namespaces Recommendation defines two kinds of names that may be qualified by means of a prefix: element names and attribute names. The XSLT Recommendation extends this to many other kinds of name that appear in the values of XML attributes, for example variable names, function names, template names, names of keys, and so on. All these names can be qualified by a namespace prefix.
-
If a name has no prefix, then its namespace URI is considered to be the default namespace URI in the case of an element name, or a null URI in the case of an attribute name or any other kind of name (such as XSLT variable names and template names). Within an XPath expression, the default namespace URI is not used to qualify unprefixed names, even if the name is an element name. However, there is an attribute xpath-default-namespace that you can set on the <xsl:stylesheet> element, or on other elements, to qualify such names. This is described in Chapter 5 on page 442.
-
Two names are considered equal if they have the same local part and the same namespace URI. The combination of the local part and the namespace URI is called the expanded QName. The expanded QName is never actually written down, and there is no defined syntax for it; it is a conceptual value made up of these two components.
The JAXP Application Programming Interface, described in Appendix D , allows expanded QNames to be written in the form «{namespace. uri} local-name » . This is sometimes referred to as Clark notation.
-
The prefix of a name is arbitrary in that it does not affect comparison of names; however, it is available to applications, so it can be used as the default choice of prefix in the result tree, or in diagnostic output messages.
In the XPath tree model, there are two ways namespace declarations are made visible:
-
For any node such as an element or attribute, the three components of the name (the prefix, the local part, and the namespace URI) are each available via the functions name(), local-name() , and namespace-uri() . The application doesn't need to know, and cannot find out, where the relevant namespace was declared. Technically, the prefix is not actually stored as part of the element or attribute name in the tree, but is reconstructed when the name() function is called. In some situations (for example, if your document uses more than one prefix to refer to the same namespace URI) the system might not use the original prefix, but another prefix that identifies the same namespace URI. In a few cases, typically where the source document uses the same prefix to refer to more than one namespace, it may be necessary for the processor to invent an arbitrary prefix.
-
For any element, it is possible to determine all the namespace declarations that were in force for that element, by retrieving the associated namespace nodes. These are all made available as if the namespace declarations were repeated on that specific element. Again, the application cannot determine where the namespace declaration actually occurred in the source document. The name of a namespace node is the namespace prefix that was originally written in the source document; unlike the prefix returned by the name() function, the system is not free to change this.
Although the namespace declarations are originally written in the source document in the form of XML attributes, they are not retained as attribute nodes on the tree, and cannot be processed by looking for all the attribute nodes. Similarly, it is not possible to generate namespace nodes on the result tree by writing attributes with the names «xmlns: * » reserved for namespace declarations.
What Does the Tree Leave Out?
Many newcomers to XSLT ask questions like "How can I get the processor to use single quotes around attribute values rather than double quotes?" or "How can I get it to output « » instead of «& # 160; »?" -and the answer is that you can't, because these distinctions are considered to be things that the recipient of the document shouldn't care about, and they were therefore left out of the XPath tree model. The principal output of an XSLT stylesheet is a tree, not a serialization.
Generally , the features of an XML document fall into one of three categories: definitely significant, definitely insignificant, and debatable. For example, the order of elements is definitely significant; the order of attributes within a start element tag is definitely insignificant; but the significance of comments is debatable.
Figure 2-6 illustrates this classification: the central core is information that is definitely significant; the "peripheral" ring is information that is debatable; while the outer ring represents features of an XML document that are definitely insignificant.
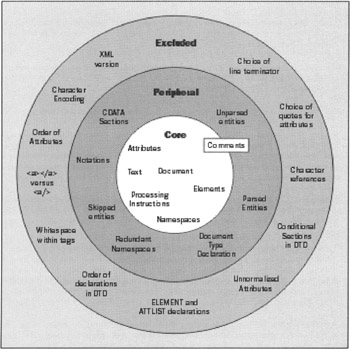
Figure 2-6
The choice of information items that are present in the XSLT/XPath tree model, and that therefore are accessible to an XSLT stylesheet follows the "core" as shown in the previous diagram fairly closely, but there are some very small differences of detail:
-
The XSLT model includes comments. However, XML parsers aren't required to retain comments, so they can sometimes be lost before the stylesheet gets to see them.
-
XSLT retains all the information derived from namespace declarations, unless the namespace declaration is redundant. It doesn't retain the actual namespace prefix used as part of an element or attribute name, but it will usually be possible to reconstitute the original prefix unless there are several prefixes declared for the same namespace.
-
The XSLT model retains the base URI as a property of a node, unless you use the xml:base attribute; this property is not actually present in the original XML document, but is derived from the URI of the file or other resource containing the original document. As a result, this property will often not survive when documents are copied or moved, which can give problems when the document contains relative URIs.
Controlling Serialization
The transformation processor, which generates the result tree, generally gives the user control only over the core information items and properties (plus comments) in the output. The output processor or serializer gives a little bit of extra control over how the result tree is converted into a serial XML document. Specifically, it allows control over the following:
-
Use of CDATA sections
-
XML version
-
Character encoding
-
The standalone property in the XML declaration
-
DOCTYPE declaration
Some of these things are considered peripheral in our classification given earlier and some are in the excluded category. The features that can be controlled during serialization do not include all the peripheral information items (for example, it is not possible to generate entity references), and they certainly do not include all the excluded features. For example, there is no way of controlling the order in which attributes are written, or the choice of <a/> versus < a >< /a> to represent empty elements, the disposition of whitespace within a start tag, or the presence of a newline character at the end of the document.
Although you get some control over these features during serialization, one thing you can't do is copy them from the source document unchanged through to the result. The fact that text was in a CDATA section in the input document has no bearing on whether it will be represented in as a CDATA section in the output document. The tree model does not provide any way for this extra information to be retained.
To underline all this, let's list some of the things you can't see in the input tree and some of the things you can't control in an XML output file.
Invisible Distinctions
In the following table, the constructs in the two columns are considered equivalent, and in each case you can't tell as a stylesheet writer which one was used in the source document. If one of them doesn't seem to have the required effect, don't bother trying the other because it won't make any difference.
| Construct | Equivalent |
|---|---|
| <item/> | <item></item> |
| > | > |
| <e>"</e> | <e>"</e> |
| <![CDATA[ a < b ]]> | a < b |
| <a xmlns="one.uri"> <b/> </a> | <a xmlns="one.uri"> <b xmlns="one.uri"/> </a> |
| <rectangle x="2" y="4"/> | <rectangle y='4' x='2' /> |
In all these cases, except CDATA , it's equally true that you have no control over the format of the output. Because the alternatives are equivalent, you aren't supposed to care which is used.
Why make a distinction for CDATA on output? Perhaps because where a passage of text contains a large number of special characters, for example in a book where you want to show examples of XML, the use of character references can become very unreadable. It is after all one of the strengths of XML, and one of the reasons for its success, that XML documents are easy to read and edit by hand. Also, perhaps, because there is actually some controversy about the meaning of CDATA : there have been disputes, for example, about whether «<![CDATA[]] > » is allowed in circumstances where XML permits whitespace only.
DTD and Schema Information
The XPath designers decided not to include all the DTD information in the tree. Perhaps they were already anticipating the introduction of XML Schemas, which are widely expected to replace DTDs.
The XSLT processor (but not the application) needs to know which attributes are of type ID , so that the relevant elements can be retrieved when the id() function is used. It is part of the tree model that a particular element has a particular ID value, and this information will generally be available whether it comes from a DTD or from a schema. For other attribute types defined in a DTD, the specification is a little fuzzy. It does say that unless you use a schema-aware processor, the type annotations on all attributes will be xdt:untypedAtomic . But with a schema-aware processor, the system may take notice of DTD types as if they were defined in a schema rather than a DTD.
The information contained in the schema (for example, the type hierarchy) is not officially part of the data model, but there are implications that it is available to the XSLT processor in some form. In the formal data model, all you get is the type annotation property of element and attribute nodes, which is a reference to a type (a simple or complex type) defined in a schema. The specification doesn't say exactly how the information about this type is modeled , and there is no way for an application to access the type information directly (unlike languages such as SQL or Java, which offer this capability through a feature known as reflection or introspection ). However, the implication is that internally the XSLT processor has access to any schema information needed to interpret a type annotation on a node in the tree.
We will be looking at the relationship between XSLT processing and XML schemas much more closely in Chapter 4.
EAN: 2147483647
Pages: 324