Full-Text Search in a Native XML Database
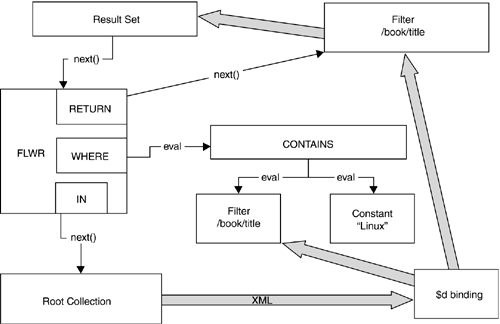
| Native XML databases need to handle any kind of XML document, from very rigidly structured, data-centric documents at one end of the spectrum, to very loosely structured, document-centric information at the other end, as well as the semi-structured information that combines both. The less predictable the structure of the data, the more users will rely on the textual content, rather than the structure, to find the information they need. As well as the structured FLWOR and path expressions of XQuery 1.0, therefore, a native XML database needs to provide facilities for text search. Full-text search is a sophisticated DBMS feature, not a simple bolt-on. Although a task force in the XQuery working group is exploring full-text search features, vendors , as a stopgap, have used their own specifications or borrowed from a past specification such as that in the SQL multimedia specification [SQLMULTI]. In XStreamDB we chose a set of requirements that met a number of simple use cases. Two techniques have been proposed for adding full-text search to XQuery. One approach is to extend the grammar of the language; the other is to add a function library, perhaps including functions that support a sublanguage oriented to text matching. In XStreamDB we decided on an approach that embedded match and rank expressions directly into the XQuery grammar. We did so to allow other XQuery expressions to be used with our full-text expressions in a freely composable fashion. As a way of illustrating these full-text expressions, consider the following example: Find all books with the word "Linux" in the title and return those titles. This is a very simple example. In practice, full-text search does not simply look for character strings. It has to break the text intelligently into words, in a way that depends on the natural language in which the text is written. It generally has mechanisms for working out which words are equivalent, either because they are lexical variants (such as plurals) or semantic variants (synonyms). It usually uses algorithms for ranking the significance of a word within the text, based on its frequency of occurrence and on where it appears. The result need not be a Boolean true/false answer; it can be a ranking of how good the match is between the document and the query. The query typically returns the most highly ranked documents, up to some threshold. The following expression, a word search using a full-text extension, is very similar to standard usage: for $doc in Root("BooksDB:Books") where match $doc using [/book/title contains "Linux"] return $doc/book/title Note that the match expression is just a Boolean XQuery expression, and the for and return clauses are essentially standard XQuery. Adding these additional full-text expression types was natural since XQuery is a functional language composed of nestable expressions. A detailed analysis of the examples above is as follows . The for clause introduces a set of bindings for $doc ; these evaluate according to the where clause, which, depending on the data in $doc , would reduce the set of $doc tuples processed by the return clause. The return clause evaluates each of the remaining $doc bindings to result in a sequence of title elements. The only non-XQuery part is the match expression. This match expression in the where clause evaluates to a Boolean for each binding of $doc . The match applies the predicate in the using clause against the $doc context to render a Boolean true/false value. The match can be read as follows: Match to true in the case where the $doc binding has a /book/title which contains the word "Linux." The first step in doing this kind of XQuery extension is to use understandable semantics; next in importance is the need to be able to optimize the expression using a full-text index. Figure 8.3 shows a query-execution plan used to execute the above query at query-execution time. A query-execution plan is a data structure that is traversed and interpreted by a query processor. The plan below is the one that results when no full-text index is present, so no index optimization is possible. In this case, the entire collection of documents is traversed, the words in the /book/title path within $doc are tokenized, and this set of words is evaluated as to whether it contains the word "Linux." The rectangles in the figure are objects that implement the next() and eval() methods . The single arrows are invocations of next() or eval() . The double arrows show the flow of XML through the plan. Figure 8.3. A Non-Optimized Query-Execution Plan To get an idea of the work undertaken by the query processor, consider the steps required to find and return one book title:
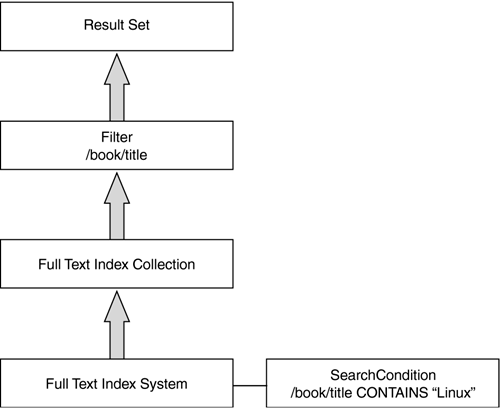
Evaluating this query for a collection of a hundred thousand documents would be time-consuming . Fortunately, the presence of a full-text index optimizes the query. With a full-text index the query plan looks quite different, as shown in Figure 8.4. Figure 8.4. An Optimized Query-Execution Plan The main advantage of the plan in Figure 8.4 is that traversal of the collection and the repeated comparisons are replaced with use of the full-text index. In the optimized plan, the only work that is done, after the full-text index is used, is to project the results using /book/title with the filter node above. Depending on the storage plan, this projection could be optimized as well. Since the full-text index only selects those documents matching /book/title CONTAINS "Linux" , this query can be very fast when run on a hundred thousand documents, assuming that only a small percentage of the titles contain the word "Linux." The above match optimization is fairly standard for most types of where- clause optimization in a query, with most of the work being pushed onto the indexin this case a full-text index. Optimization with document ranking, however is more complicated and is not covered here in any detail. In fact, supporting ranking as an extension to XQuery is more difficult than doing a match. To perform a ranking means to do a match as above, but to return a value as to how relevant the document is with respect to other documents according to the predicates applied against it. For example, the rank expression below returns a value between 0 and 1 inclusive that scores the individual document with respect to how much it has to do with the term "Linux" as compared to all other documents in the collection. A simple ranking algorithm would count "Linux" words contained within a certain document and give those documents with high counts a higher rank. A slightly more sophisticated algorithm takes into consideration how common the term is. A common scoring algorithm developed by Gerard Salton follows: W( d,t ) = TF( d,t ) * IDF( t ) In English, the weight or score of a document for a given term t is equal to the term frequency within the current document d , times the inverse of the term frequency across all documents in the collection. This is a simple algorithm, but vendors use their own algorithms to improve the precision of their ranking algorithms. (An important consequence of this is that two full-text systems will give different answers to the same query.) Below is the ranking query used in XStreamDB, which asks for a rank-ordered list of titles from the Books collection which contain the word "Linux": for $doc in Root("BooksDB:Books") let $rank := rank $doc using [//* contains "Linux"] where $rank > 0 order by $rank return $doc/book/title The rank expression rank $doc using [//* contains "Linux"] returns the ranking of $doc on the word "Linux" relative to other documents in the same collection. Then the documents with $rank equal to zero (that is, those where the word does not occur) are dropped by the where clause, and remaining documents are ordered by $rank . The titles of the books are then returned. Note that the order by expression above orders the tuples of the FLWOR expression by $rank . Ranking is more complicated than a Boolean match, but it can greatly increase the effectiveness of full-text searching. In the above extended XQuery expression, the for , let , where , and order by expressions are rewritten by the optimizer to use the full-text index. Once this essential optimization is done, the rest of the flow of the documents is similar to the optimized execution plan shown in Figure 8.4. Obviously, full-text search requires many more features than these examples illustrate . Among the popular features are the following:
Full-text search is a complex subject. The technology has been under development for forty years , and many books have been written on the subject. Many simple and advanced full-text features will probably find their way into XQuery in one form or another. Full-text search is very compelling for a native XML databasemuch more so than for a relational DBMSbecause for many document-centric XML applications, the only reliable way to find the document you want is a search against the textual content. |
EAN: 2147483647
Pages: 102