SYSTEM MANAGEMENT ENVIRONMENT FOR ON-DEMAND ACCESS
| | ||
| | ||
| | ||
In an on-demand access environment, where information resources are centralized, the need for tools and procedures that serve to decrease the frequency of unscheduled downtime is more important than ever. The organizational mandate for on-demand computing and full, secure control of the environment dictates that the operations necessary to support a Citrix environment have more in common with the Network Operation Center (NOC) of an Internet service provider (ISP) or commercial hosting service than with a traditional, distributed corporate network. It is no longer acceptable for IT staff to discover problems after they occur, as an audit function. They must have tools and procedures in place to perform predictive analysis on potential problems and to isolate and contain problems during the troubleshooting process. An effective systems management environment will address these needs through measurement of the various systems and through the enforcement of service level agreements. The data collected during measurement can be used in troubleshooting and making corrections. For example, if a Presentation Server crashes due to an application fault, the RM package will have recorded which applications were running at the time of the crash. Without this information, it would be challenging to find the crash's exact cause. An effective SME has the following objectives:
-
– Improving the availability and performance of the Citrix resources
-
– Lowering the cost of IT maintenance and support services
-
– Providing a service-level view of Citrix resources
The "people" part of the three P s is made up not only of users and IT staff, but also any group affected by the services being delivered. For many organizations, this means external customers, business partners , and even competitors . The SLAs associated with the services being delivered, and the associated reports , are the "process" part of the three P s and are, collectively, the tool that shows whether the preceding objectives are being met. The "product" consists of all the hardware and software necessary to deliver the information needed to measure the SLAs. Any technology utilized in the SME should meet the following basic requirements:
-
– Provide a central point of control for managing heterogeneous systems A
"central point" refers to one tool or collection mechanism used to gather information from all sources. The actual data repository could be distributed to multiple locations where administrative activity takes place.
-
– Allow event management across heterogeneous systems and network devices The toolset should support all the common operating system and network hardware platforms and provide enough extensibility for custom interfaces to be configured, if necessary.
-
– Provide service-level views of any portion of the infrastructure A "service-level view" is an aggregation of lower-level events that correlate to show the impact of various failures in terms of an established SLA. A message stating "Server 110 has crashed with an unknown error" has far less meaning than "Application service capacity has decreased by 10 percent" and "Application services for users in the San Antonio region have been interrupted ."
To further refine these requirements, more detail on the exact duties to be incorporated in the SME is needed. Defining in specific terms what will be measured and how it will be measured will greatly aid in the selection of the proper technology. We will discuss SME tools later in the chapter.
Configuration Management
Arguably, the most common problem in managing distributed computer systems is configuration management. Even companies with very organized IT staffs can have complete chaos on the desktop with regard to which application or application versions are installed and which changes to the operating system are allowed. In a Citrix environment, the chaos, so to speak, is limited to the data centers, but the need for configuration management is even greater. If a user changes a setting on his PC that causes it to crash, that user experiences unscheduled downtime. If an administrator makes a change to a Presentation Server that causes it to crash, every user currently logged onto that server experiences unscheduled downtime. An effective SME must have in place controls to restrict and audit changes within the data center. A configuration management system should have the following characteristics:
-
– A clearly defined operational baseline The baseline defines the starting point for the management process.
-
– A change tracking system A process for requesting, submitting, prioritizing, approving, and testing changes to the operational baseline. Once a change has completed the process, it becomes part of the baseline.
-
– Defined categories and priorities for changes For example, some changes need to be tracked, such as changes to group membership and administrative rights, but can be safely implemented as an extension of the current baseline. Others must be implemented very quickly and may disrupt user activity, such as critical security patches. From a software management perspective, most organization configuration management systems differentiate between patches, enhancements, and major revisions, and they often employ a "release" process where any or all of these must be tested and certified in a development/test environment before implementation in production systems.
-
– Implementation procedures Necessary steps that must be taken before implementation, such as how to save the current state before a change, how to decide if a change is not working, how to back out of a change, and how to use collected information to modify the original change request and resubmit it.
Modern computing environments are far too complex for an automated tool to check and restrict any change. A combination of an effective automated tool and "best practice" procedures for change management is the key to a successful configuration management function.
Security Management
Security management serves to ensure that users have access to only the applications, servers, and other computing resources they are authorized to use. Again, a combination of automated tools and employee policies are called for. The implementation of an Internet firewall to prevent unauthorized external access will do nothing to prevent a disgruntled employee from accessing and publishing confidential information. Only the combination of automated internal system limitations, effective monitoring, published "acceptable use" policies, and committed enforcement of those policies can serve to deter such unforeseen incidents.
Alerting
As we discussed in Chapter 8, it is not enough simply to log attempts to bypass security within the Citrix environment. An effective SME should include a network management tool that will actively alert the appropriate personnel if a security breach of sufficient severity is detected . For example, say an employee discovers the Registry settings where his group information is stored and figures out how to change that value to Admin without using the management console. First, the Registry should not allow the change to be made by that user because it has been locked against changes by anyone not currently in the Admin group. However, if the change is somehow made, the system should log an event in the event log (auditing). The management agent program on that system should watch the event log, detect the event, and send a page to the security administrator. Alternatively, the offending user's account could be locked, as shown in Figure 9-3.
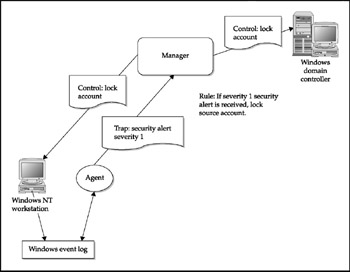
Figure 9-3: A security alert within an SME
IP Address and Host Name Management
In a large enterprise network, managing the identity of each node on the network can be a daunting task. Many network management tools will " autodiscover " nodes on the network, but this task can be laborious and chew up processing and network bandwidth unless the addressing and naming schemes are well ordered. An effective SME will include policies for standard naming practices as well as an efficient IP addressing scheme. There are several common attributes for host naming that must be considered :
-
– The namespace must be self-documenting . If you need to refer to a cross-reference chart to decode the host name, the namespace is not administratively usable. At a minimum, the namespace should self-document the server, client, and peripheral (printer) pieces of the network infrastructure.
-
– For Windows environments that use Active Directory and DNS:
-
– Ensure only valid characters are used (no underscores).
-
– Keep it short. DNS, and hence Active Directory, namespace prepends data to the root namespace. A fully qualified host named "CitrixServer01-Win-Seattle.ChildDomain.ParentDomain.com" may be self-documenting, but it is unmanageable (and nearly un-typeable). A host name of "CTX01W-SEA. ChildDomain.ParentDomain.com" is far more usable.
-
-
– For Windows environments that also use WINS:
-
– NETBIOS host names are limited to 15 characters (a Microsoft specification).
-
– Observe the limitations on allowable characters (\ * + = : ; ? < > , are prohibited ). Some " allowable " NETBIOS name characters (@ # $ % ˆ & () ˜ { } . ~ !) are incompatible with the DNS character set and should not be used.
-
– Try to match the NETBIOS name to the DNS host name.
-
Here are some ideas we have seen used effectively:
-
– Create host names based on department and geographic location, followed by a numerical value. For example, a user's Windows terminal in the Seattle accounting division might have SEAWBT-ACC16 as a host name.
-
– Create host names incorporating the type of device. (To extend the preceding example, an LPR printer might be named SEALPR-ACC4 or SEAP-ACCHP8100.)
-
– Using octets within an IP address to map a host identity should be avoided. Although some limited identity can be established, this invariably leads to an IP address scheme that is neither hierarchical nor extensible.
| Note | Many large organizations use Dynamic Host Control Protocol (DHCP) and Dynamic Domain Name Service (DDNS) to dynamically assign IP addresses and host names, respectively, to network nodes. These services have several advantages, including automated host name standardization and reduction of the number of IP addresses in use at one time by assigning temporary ones from a pool. If you utilize these services in your organization, be aware that it may complicate the SME if the NMS you choose is not compatible with, or not aware of, these services. An NMS must be able to discover and manage dynamically assigned hosts , or you will have the problem of all of these nodes going unmanaged. |
Using Service Level Agreements
As we mentioned earlier, a service level agreement defines the policies and procedures that will be used within the SME. The execution of those policies and procedures will rely in equal parts on automated tools and "acceptable use" policies that the employees within the organization must abide by. Employing SLAs within the SME will have the following effects:
-
– User expectations will be much closer to the reality of how a particular service is delivered . Many users see the network as a public utility that has 100 percent uptime. This is a good goal but often is not realistic. Publishing an SLA will show the users what is realistic and what their options are if the service delivery doesn't conform to the SLA. After all, very few public utilities can show a track record of sustained 100 percent uptime.
-
– IT staff growth will slow . IT organizations without SLAs tend to spend an inordinate amount of time "fighting fires" because service personnel don't know where the boundaries are for the service they are providing. Users don't know where those boundaries are either. The cumulative effect is that users will inevitably try to get as much service as they can, and the service staff will try to satisfy the users by delivering as much as they can. This serves to increase the number of service personnel needed.
-
– IT service quality will increase . When the service is well-defined and understood by users and service personnel alike, the delivery of that service will be more consistent. This happens for a couple of reasons. First, the people trained to administer the systems have more time to pay attention to their effective management, since they spend less time fighting fires. Second, the users' expectations of the service will be more in line with its delivery, which will reduce the number of complaints. A relatively new concept, Application Quality of Service (Application QoS), is a measure of how effectively applications are delivered to the user and thus can be one measure of IT service quality in a Citrix environment. Application QoS service-level views can be found in some of the network management tools we will discuss later in the chapter.
System Management Environment Architecture
With what has been defined so far, we can now look in detail at some specific duties covered by an effective SME for the data center. The overall architecture should include, at a minimum, the functions described in the following sections for the entire Citrix infrastructure.
Network Discovery
It would be incredibly tedious if you had to enter information about each node before it could be managed. Fortunately, nearly every modern NMS tool provides the ability to actively discover information about nodes on the network. Though most polling is TCP/ IP-based, an effective NMS uses a variety of other methods to discover nodes, including NetBIOS and SAP broadcasts. The basic philosophy is "anything that will work." The majority of nodes will respond somehow , and those that don't can be handled as an exception and entered manually. Network discovery is a function shared by both the agent and the manager, as is shown in Figure 9-4.
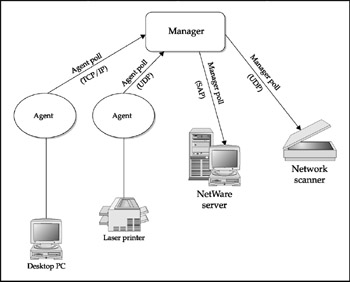
Figure 9-4: Network Discovery
Hardware and Software Inventory
This function is similar to node discovery in design but is much more detailed. Once a node is discovered and is identified, the discovery process will interrogate the device to find out about the software and hardware configuration. If fat clients must be used, this can be an invaluable tool to "meter" softwarethat is, to find out if the number of licenses purchased matches the number of licenses in use. It can also aid in creating inventories of hardware that need to be upgraded for a particular project. Similar functionality is available for peripheral and network devices. Hardware and software inventory data is usually rolled into the overall configuration management process.
Monitoring and Messaging
The most common agent function is to "watch" the system and look for problems as defined in a rule base. Ideally, this rule base is administered centrally and shared by all similar agents . The agent's job is to send an appropriate message whenever an item in the rule base is triggered, as illustrated in Figure 9-5. These items can consist of both errors, or traps, and collections of information such as traffic thresholds, disk utilization, and log sizes.
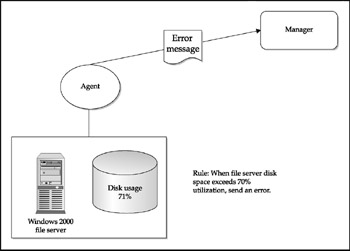
Figure 9-5: Agent monitoring
With SNMP-based systems, the agent processes events and sends messages with little to no filtering or processing on the local system. This is acceptable because SNMP messages are typically small and not likely to flood the network. In systems with more intelligent agents, where much more detailed information can be collected, the agent has the added task of collating or summarizing the data before sending it to the manager. Otherwise, the added traffic caused by unsummarized messages could cause a bandwidth utilization problem.
| Note | SNMP uses standard UDP ports 161 and 162. Port 162 is reserved for traps only. As a result, it can be made subject to bandwidth utilization rules in a router (queuing) or in a device such as the Packeteer PacketShaper. Similarly, CMIP reserves UDP and TCP ports 163 for the agent and 164 for the manager. These ports are common, but your platform may use different ones. |
Management by Exception or Negative Monitoring This can be a function of an agent or a manager. Sometimes not receiving a piece of information from a system is just as critical as receiving one. A system may become unresponsive without ever sending a trap. In cases like this, it is useful to have a periodic "heartbeat"a small message that says nothing more than, "I'm here." If the agent or manager does not receive this heartbeat, an alert is generated for follow-up. We have found this type of monitoring to be a crucial part of the SME, since not all platforms send alerts when they are supposed to.
Network Monitoring and Tracking The NETMON program, which ships with versions of Windows, can track network traffic at a very detailed level, but its scope is limited to the data streams coming into and going out of the server it is running on, or the similar nodes it can recognize. An SME must measure network traffic and problems between any two arbitrary points. It should follow established rules to do detailed monitoring on critical paths, such as between data centers, on an Internet router, or between Citrix servers and back-end database servers. Thresholds can be established that serve to guarantee acceptable performance and send alerts if those thresholds are reached. In many ways, a Citrix environment's heavy reliance on network performance makes this one of the most crucial monitoring functions. Effective monitoring in the SME can provide critical data for predictive analysis about when the network is approaching saturation before it ever happens. Figure 9-6 shows how agents at multiple sites can feed data to a centralized manager.
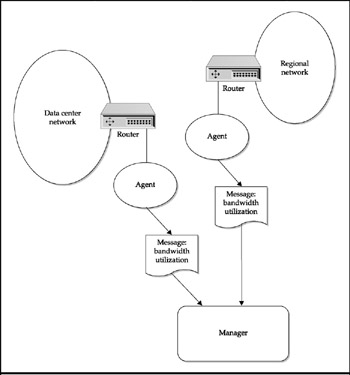
Figure 9-6: Multisite network monitoring
Remote Diagnostics By using the Citrix's shadowing function, administrators can attach to and run a user's session anywhere on the network from a central location. Similarly, an SME should offer the ability to attach to network equipment and perform basic operations, such as uploading and downloading configurations and rebooting. If a particular node cannot be reached, the SME should provide enough data from surrounding nodes to determine what is wrong with the unresponsive equipment.
Data Collection
While monitoring is the primary duty of the agent, data collection is the primary responsibility of the manager. The manager must record all incoming information without filtering, or auditing could be compromised. Relevant information can be easily extracted from the manager's database using query and reporting tools.
Data Collation and Event Correlation
There should be a function above the level of the manager or managers (see Figure 9-7) that collates data from all sources and compares this data with established patterns and rules. This type of collation is called event correlation . When the events have been correlated, the result can be expressed in terms of an SLA.
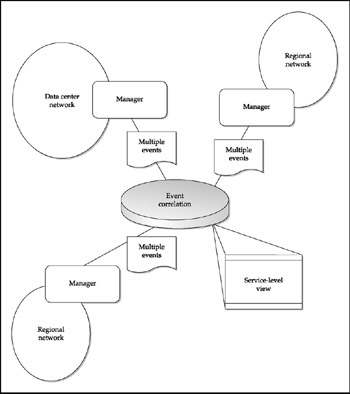
Figure 9-7: Event correlation
For example, a large enterprise network has a router failure between a large regional office and the main data center. The router sends a trap saying that the memory stack has been corrupted. Immediately after the router goes down, several other traps indicating that the regional office cannot be reached are sent from surrounding nodes at the data center. The manager in the data center collects several hundred messages in only a few minutes. At the point the first critical message is received by the manager, an automatic page is sent to the system administrator on duty. When the system administrator logs on and begins investigating the problem, he sees the hundreds of messages in the database. Fortunately, the event correlation function has categorized the different messages for him. He checks the display of service-level views and sees that the SLAs for network connectivity and application services to the regional office are not being met. His reaction to these issues is defined in the SLA for the associated service. Now he can use filtered queries to examine the detailed messages from across the network in order to solve the problem.
| Note | Though having service-level views into problems is extremely useful, sometimes getting the information as soon as it is sent by an agent is more desirable. It is perfectly acceptable to define certain key events from key agents so that they travel the entire escalation path directly to an administrator for follow-up. It is even possible to define some agents so that they send a page at the same time that a trap is sent across the network. (Sometimes bad news needs to travel faster than good news for an SLA to be met.) |
Other SME Functions
A few additional functions common to an SME take on slightly different roles when applied to the Citrix infrastructure. We discuss these next .
Software Distribution/Unattended Install When thinking in terms of a thin client, Presentation Servers perform the function of software distribution. There is no reason to distribute an application any further than the server farm when nothing is running on the desktop except the ICA client. Thus, the need for unattended installation of desktop software loses its importance (security updates and core OS updates remain important). Even with a server farm containing 50 servers, it is not that difficult to install applications manually if necessary. This would be a far different proposition with 5,000 desktops.
| Note | Fortunately, it is not necessary to install applications manually on your server farm. We will discuss methods for streamlining this process in Chapters 12 and 13. |
If you don't have the luxury of taking the entire enterprise to thin-client devices, software distribution and installation are more important and should be considered a critical part of the SME. We will discuss this function as part of the tools discussion later in the chapter. Figure 9-8 shows software distribution in a thin-client network, while Figure 9-9 shows the same function in a traditional distributed, or fat-client, network. For enterprises that need remote security and core OS updates, Microsoft has rebuilt the Software Update Service (SUS) as Windows Server Update Services (WSUS), which links to Windows update and allows administrators to apply a subset of Microsoft's Systems Management Server (SMS) capabilities to Windows 2000 clients and servers, Windows Server 2003, and Windows XP.
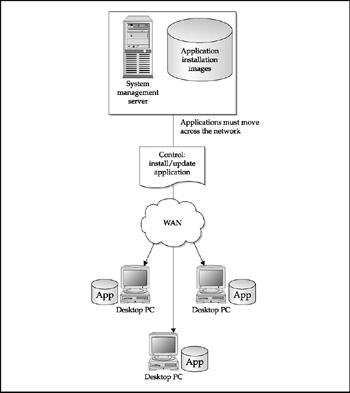
Figure 9-8: Software distribution in a Citrix environment
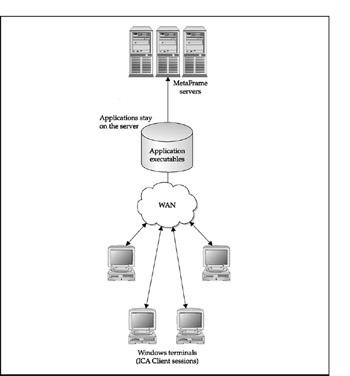
Figure 9-9: Software distribution in a distributed network
Software Metering Similarly, software metering becomes far simpler in an on-demand access environment. All the applications are running on the server farm, and administrators can use Citrix RM to determine which users are running which applications. Furthermore, scripting techniques can be used to assign application access to user groups and to lock down the desktop to the point where users cannot run unauthorized applications. PowerFuse, one of the "security" tools mentioned in Chapter 8, has an added benefit of allowing an application to be published to a large number of users while restricting concurrency to stay within licensing limitations. We will discuss these methods in Chapters 12, 13, 15, and 20.
In a distributed client network, software metering becomes much more complex and difficult to manage. Typically, an agent running locally on the desktop takes on the task of conversing with a manager and determining whether a user is authorized to run a particular application. It also takes any punitive measures necessary.
Desktop Lockdown A common function of SME tools has historically been to lock down the desktop so that users cannot install unauthorized applications or make changes to the local operating system that would make it unstable or affect performance. Chapter 15 discusses desktop lockdown of the Presentation Servers using Group Policies and profiles as well as third-party applications like RES PowerFuse, AppSense, and triCerat. In a distributed environment, these same tools, in addition to other major SME tools from Microsoft and HP, provide this functionality for each desktop.
Desktop Remote Diagnostics In the past, remote control tools such as PCAnywhere from Symantec were used to connect to a user's desktop and allow an administrator to see what the user sees. With Presentation Server, the session shadowing feature built into the ICA session protocol provides this functionality from a central location in an efficient manner.
Management Reporting
The parts of the SME architecture presented so far have dealt mainly with collecting information and controlling the environment. Publishing and sharing the collected information and the results of those efforts for control are just as important. The value of management information increases the more it is shared. The IT staff should adopt a policy of "no secrets" and share information in terms of measured SLAs with users and management. That being said, it is also important to present the information formatted appropriately for the audience. Management typically is most interested in bottom-line information and would not find a detailed network performance graph very useful. A one- or two-page report listing each service level and the key metrics used to show whether that service level is being met would likely be more appropriate. Users make up a diverse group in most large organizations, making it prudent to err on the side of showing too much information. We have found that publishing the user SLA reports on a corporate intranet is a convenient method, since it provides a central location for the information. If a more proactive method for distributing the information is desired, the URL for the intranet page can be e-mailed to the users.
| Note | The format of your reports should not be determined by the capabilities of the measurement and reporting tools. The report should reflect the results of business-driven service level agreements in order to be useful to their recipients. If your SME tools can produce the reports using this format, so much the better. If they cannot, don't be afraid to process some of the reporting data manually until an automated system can be worked out. |
Communication Plan Part of effective reporting is establishing a communication plan. A communication plan can also be thought of in this context as a "reporting SLA." You must decide who is to receive the reports, at what frequency, and at what level of detail. If interaction between individuals or groups for review or approval is needed, define how this is going to happen and document it as part of the plan. For enterprises with an intranet built on Microsoft SharePoint, Citrix Presentation Serve Web Interface for Microsoft SharePoint may be the easiest way to create a one-stop -shop for internal access and information.
On the subject of what to publish, we have found the following reports to be very useful.
Daily Reports The idea behind a daily report is to provide users and management with a concise view of performance against SLAs. The report should show only key indicators for each SLA. Sometimes called a hot sheet , this report should only be one or two pages in length. Figure 9-10 shows an example of such a report. The ideal delivery mechanism for such a report is on an intranet site (such as an MSAM site, as discussed earlier) or through e-mail. Enterprises often combine the hot sheet with other pertinent information that may affect user service over the next 24 to 72 hours, such as downtime or approved configuration changes from the configuration management process.
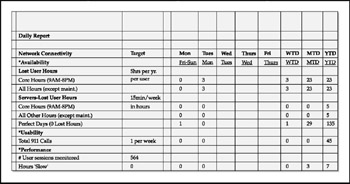
Figure 9-10: A daily report or hot sheet
Periodic Reporting Periodic reports should have more detail than daily reports. At whatever interval is defined in the communication plan, detailed performance information should be published to users and management. This type of report should show all indicators used to measure SLA performance. The data used to generate this type of report is also used for predictive analysis or trending . For example, periodic views of disk space utilization will show how fast new disk space is consumed and when new storage should be put online. Trend reports allow you to stay ahead of demand and avoid resource-based outages.
EAN: 2147483647
Pages: 137
- Enterprise Application Integration: New Solutions for a Solved Problem or a Challenging Research Field?
- Data Mining for Business Process Reengineering
- A Hybrid Clustering Technique to Improve Patient Data Quality
- Relevance and Micro-Relevance for the Professional as Determinants of IT-Diffusion and IT-Use in Healthcare
- Development of Interactive Web Sites to Enhance Police/Community Relations