| The terms router and switch are often confusing because of the marketing adaptations from vendor to vendor. Original routers performed Layer 3 packet forwarding decisions on general-purpose computing devices with multiple network interface cards. The bulk of the packet processing was performed in software. The inherent design of Ethernet has limited scalability. As the number of nodes increased on an Ethernet segment belonging to one collision domain, the latency increased exponentially, hence bridges were introduced. Bridges segregated Ethernet segments by only allowing broadcasts to certain segments and learning MAC addresses. This allowed the number of nodes to increase. The next advance in network switches was introduced in the early 1990s with the introduction of the Ethernet switch, which allowed multiple simultaneous forwarding of packets based on Layer 2 MAC addresses. This increased the throughput of networks dramatically, since the single talker shared-bus Ethernet only allowed one flow to communicate at any one single instant in time. Packet switches evolved by making forwarding decisions not only on Layer 2, but also on Layer 3 and Layer 4. These higher layer forwarding packet switches are more complicated because more complex software is required to update the corresponding forwarding tables and more memory is needed. Memory bandwidth is a significant bottleneck for wirespeed packet forwarding. Another advance in network switches was due to cut-through mode, which allowed the switch to immediately make a forwarding decision even before the entire packet was read into the memory of the switch. Traditional switches were of the store-and-forward type, which needed to read the entire packet before making a forwarding decision. FIGURE 4-1 shows the internal architecture of a multi-layer switch, including a significant amount of integration of functions. Most of the important repetitive tasks are implemented in ASIC components, in contrast to the early routers described previously, which performed forwarding tasks in software on a general-purpose computer CPU card. Here the CPU mostly runs control plane and background tasks and does very little data forwarding. Modern network switches break down tasks into those that need to be completed quickly and those that do not need to be performed in real time into layers or "Planes" as follows: Control Plane the set of functions that controls how incoming packets should be processed or how the data path is managed. This includes routing processes and protocols that populate the forwarding tables that contain routing (Layer 3) and switching (Layer 2) entries. This is also commonly referred to the "slow path" because timing is not as crucial as in the data path. Data Plane the set of functions that operates on the data packets, such as Route lookup and rewrite of destination MAC address. This is also commonly referred to as the "fast path." Packets must be forwarded at wire speed, hence packet processing has a much higher priority than control processing and speed is of the essence. The following section describes various common components and features of a modern network switch.
Figure 4-1. Internal Architecture of a Multi-Layer Switch 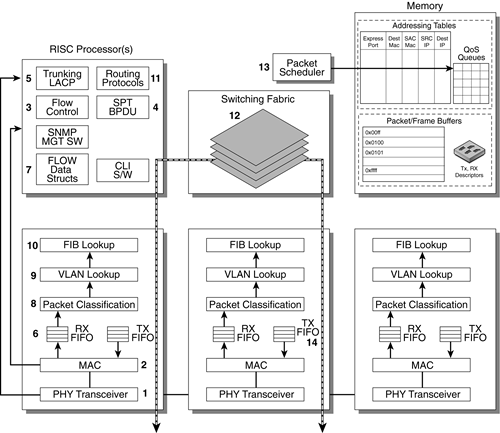
The following numbered sections describe the main functional components of a typical network switch and correlate to the numbers in FIGURE 4-1. PHY Transceiver FIGURE 4-1 shows that as a packet enters a port, the physical layer (PHY) chip is in Receive Mode (Rx). The data stream will be in some serialized encoded format, where a 4-bit nibble is built and sent to the MAC to build a complete Ethernet frame. The PHY chip implements critical functions such as collision detection, which is needed only in half-duplex mode, link monitoring to detect tpe-link-test, and auto negotiation to synchronize with the sender. Media Access Control The Media Access Control (MAC) ASIC takes the 4-bit nibble from PHY and constructs a complete Ethernet frame. The MAC chip inserts a Start Frame Delimiter and Preamble when in Transmit Mode (Tx) and strips off these bytes when in Rx mode. The MAC implements the 802.3u,z functions depending on the link speed. MAC implements functions such as collision backoff and flow control. The flow control feature prevents slower link queues from being overrun. This is an important feature. For example, when a 1 Gbit/sec link is transmitting to a slower 100 Mbit/sec link, a finite amount of buffer or queue memory is available. By sending PAUSE frames, the sender slows down, hence using fewer switch resources to accommodate the fast senders and slow receiver data transmissions. Once a frame is constructed, the MAC first checks if the destination MAC address is in the range of 01-80-C2-00-00-00 to 01-80-C2-00-00-0F. These are special reserved multicast addresses used for MAC functions such as link aggregation, spanning tree, or pause frames for flow control. Flow Control (MAC Pause Frames) When a flow control frame is received, a timer module is invoked to wait until a certain time elapses before sending out the subsequent frame. For example, a flow control frame is sent out when the queues are being overrun, so the MAC is free to catch up and allow the switch to process the ingress frames that are queued up. Spanning Tree When Bridge Protocol Data Units (BPDUs) are received by the MAC, the spanning tree process parses the BPDU, determines the advertised information, and compares it with stored state. This allows the process to compute the spanning tree and control which ports to block or unblock. Trunking When a Link Aggregation Control Protocol (LACP) frame is received, a link aggregation sublayer parses the LACP frame, processes the information, and configures the collector and distributor functions. The LACP frame contains information about the peer trunk device such as aggregation capabilities and state information. This information is used to control the data packets across the trunked ports. The collector is an ingress module that aggregates frames across the ports of a trunk. The distributor spreads out the frames across the trunked ports on egress. Receive FIFO If the MAC frame is not a control frame, then the MAC frame is stored in the Receive Queue or Rx FIFO (first in, first out), which are buffers that are referenced by Rx descriptors. These descriptors are simply pointers, so when moving packets around for processing, small 16-bit pointers are moved around instead of 1500-byte frames. Flow Structures The first thing that occurs after the Ethernet frame is completely constructed is that a flow structure is looked up. This flow structure will have a pointer to an address table that will be able to immediately identify the egress port so that the packet can be quickly stored, queued, and forwarded out the egress port. On the first packet of a flow, this flow data structure will not exist, so the lookup will return a failure. The CPU must be interrupted to create this flow structure and return to caller. This flow structure has enough information about where to store the packet in a region of memory used for storing entire packets. There are associated data structures called Tx or Rx descriptors; these are handles to the packet itself. As with FIFO descriptors, the reason for these data structures is speed. Instead of moving around large 1500-byte packets for queuing up, only 32-bit pointers are moved around. Packet Classification A switch has many flow-based rules for firewalls, NAT, VPN, and so on. The packet classification performs a quick lookup for all the rules that apply to this packet. There are many algorithms and implementations that basically inspect the IP header and try to find a match in the table that contains all the rules for this packet. VLAN Lookup The VLAN module needs to identify the VLAN membership of this frame by looking at the VLAN ID (VID) in the tag. If the frame is untagged, then depending on whether the VLAN is port based or MAC address based, the set of output ports needs to be looked up. This is usually implemented by vendors in ASICs due to wirespeed timing requirements. Forwarding Information Base (FIB) Lookup After a packet has passed through all the Layer 2 processing, the next step is to determine the egress ports that this packet must be forwarded to. The routing tables determine the next hop, which is populated in the control plane. There are two approaches to implementing this function: The distributed implementation is much faster. It will be discussed further later in this chapter. Routing Protocols All routing packets are sent to the appropriate routing process, such as RIP, OSPF, or BGP, and this process populates the routing tables. This process is performed in the control plane or slow path. The routing tables are used to populate the Forwarding Information Base (FIB), which can be in a central memory area or downloaded to each port's local memory, providing faster data path performance in the FIB lookup phase. The next step occurs when the packet is ready to be scheduled for transmission by the packet scheduler by pulling out the descriptor out of the appropriate QoS queue. Finally, the packet is sent out the egress port. Switch Fabric Module (SFM) Once the FIB lookup is completed, the packet scheduler must queue the packet onto the output queues. The output queues can be implemented as a set of multiple queues, each with a certain priority, to implement different classes of services. The SFM links the ingress processing to the egress processing. SFM can be implemented using Shared Memory or CrossPoint Architectures. In a shared memory approach, the packets can be written and read to a shared memory location. An arbitrator module controls access to the shared memory. In a CrossPoint Architecture, there is no storage of packets; instead, there is a connection from one to another. CrossPoint further requires that the packet be broken into fixed-sized cells. CrossPoint usually has very high bandwidth used only for backplanes. The bandwidths must be higher because of the extra overhead and padding required in the construction and destruction of fixed-sized cells. Both approaches suffer from Head of Line Blocking (HOL), but usually use some form of virtual output queue workaround to mitigate the effects. HOL occurs when a large packet holds up smaller packets farther down the queue when being scheduled. Packet Scheduler The packet scheduler simply chooses packets that need to be moved from one set of queues to another based on some algorithm. The packet scheduler is usually implemented in an ASIC. Instead of moving entire frames, sometimes 1500 bytes, only 16-bit or 32-bit descriptors are moved. Transmit FIFO The transmit queue or Tx FIFO is the final store before the frame is sent out the egress port. The same functions are performed as those described on the ingress (Rx FIFO) but in the opposite directions.
|