Beyond the Basics
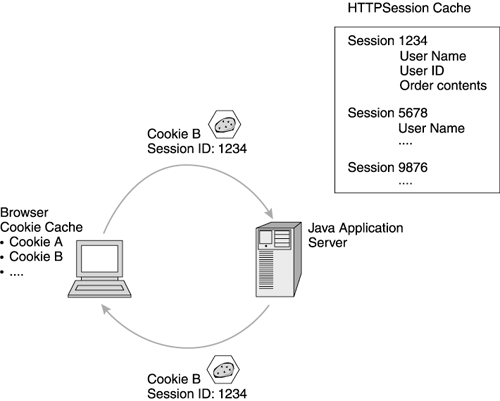
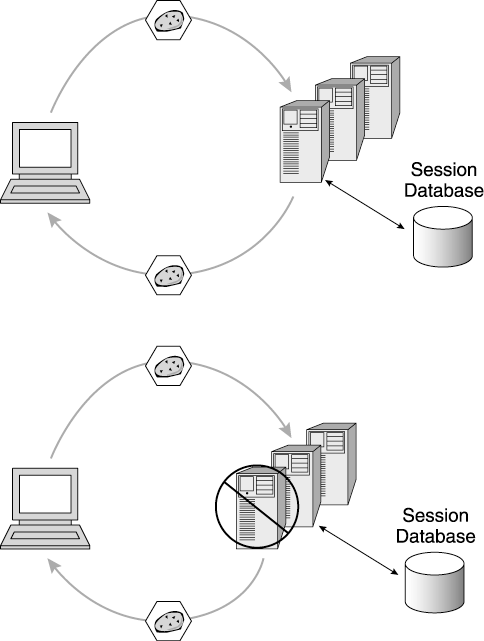
| In addition to the basic features we've discussed already, the J2EE standard provides additional features for the web application. In this section, we cover the best practices for using these features. HTTP SessionsWe discussed earlier the multi-threaded servlet model, and some of the implications this model has for your servlets. To recap, the connectionless nature of HTTP and servlet multi-threading means the servlet cannot maintain state information for the user through normal programming techniques. For example, the servlet cannot store the user 's name or account ID in an instance variable because each user does not obtain a unique instance of the servlet. Rather, multiple threads engage the same instance simultaneously . Because the usual technique for keeping state information (instance variables ) doesn't work with servlets, the servlet specification provides a different mechanism for maintaining this information. This mechanism is the javax.servlet.http.HttpSession class. A user's web site visit usually spans multiple, discrete requests , and sometimes lasts for an extended period of time (up to a day, in some cases). The HttpSession class allows the web application to keep a user's state information for the duration of the user's visit. The web application, through a servlet or JSP, requests the creation of an HTTP session for a visiting user. While the servlets and JSPs treat the HTTP session as a hash table, the application server manages the session and associates its contents repeatedly with the same user. Application servers employ several techniques to maintain the association between users and their HTTP session data. In one commonly used approach, the application server gives the visiting user a "session ID", and returns it in a cookie to the user's browser. On subsequent visits , the browser passes the cookie back to the web site, and the application server pulls the session ID from the cookie to find the user's HTTP session data. (Also, using this technique, the cookie and HTTP session management remains invisible to the programmer. The servlet programmer merely requests the current HTTP session object without directly manipulating the cookie.) See Figure 2.6 for an example of HTTP session management using cookies. Some specialized web sites also support users who cannot or will not accept cookies. In these situations, the web sites use URL-rewriting or embed state information as hidden form fields within the returned HTML. Unlike cookie-based HTTP session support, these two methods are not transparent to the developer. Developers must add code to their servlets/JSPs in order to support URL-encoding or embed hidden state information in outbound data Figure 2.6. Cookies and HTTP sessions. From "Changing Your Application Tactics: Successful Web Application Strategies for Production Websites," paper presented by Stacy Joines at Solutions 2001, San Francisco, CA. IBM Corp. 2001. Reprinted by permission of IBM Corp. While HTTP sessions solve a significant problem for your web application (how to keep state information about a user over the course of her visit), they introduce new considerations for your web site. HTTP session misuse often leads to web site performance and scalability issues. HTTP Session Memory UsageMost web application servers keep the HTTP sessions in memory. This allows the web application fast access to the user's state information. However, this also means that the HTTP sessions share memory with the running web site applications inside the JVM heap. The J2EE specification provides no mechanism for controlling the size of an individual HTTP session. Some application servers, such as the IBM WebSphere Application Server, allow the administrator to limit the number of HTTP sessions held in memory, but they do not limit the memory allocated for each of these HTTP sessions. We discussed previously how small indiscretions that might go unnoticed in a thick client application amplify to become serious issues on a high-volume web site. The HTTP session size often falls into this category. For example, thick client programmers routinely trade memory for performance. The developer might cache significant chunks of data in the client's memory to avoid repeated trips to a remote data source for retrieval. Because thick clients generally contain lots of dedicated memory (125MB or more, routinely), this approach makes sense. However, this same paradigm does not work in server-side programming. We routinely encounter web applications attempting to store 10MB of data or more into each HTTP session object. 10MB of application data on a thick client presents no real problem, but 10MB spells disaster on a high-volume web site. Let's look at the math. If the HTTP session contains 10MB of data, and we have 10,000 users arriving on the site during the HTTP session timeout period, these users would require the following memory to hold their HTTP session data: 10,000 users * 10MB/user = 100GB Since our optimum JVM heapsize often lies between 256MB and 512MB, one JVM cannot support this web site alone. In fact, if we assume a 512MB maximum heap size for each JVM, we need almost 200 JVMs to support this application! Also, keep in mind that the objects you store in your HTTP session often contain other objects. Your actual HTTP session size depends on every object you store, including deeply nested objects. Make sure you understand the full extent of everything you place in the HTTP session. HTTP session bloat clearly demonstrates why you need a web site performance test before you enter production. This problem frequently goes undetected in both the programming phase as well as the functional test phase of your application's development. HTTP session bloat impacts your web site only under load, because it deprives the web site of memory resource as the user burden increases . Therefore, you need to introduce load from many unique users to your web site before you enter production to flush out problems of this nature. HTTP Session Memory-Management TipsSo how do you defeat the engorged HTTP session problem? A few techniques are explained below. Preserve Data That Must PersistIf you are using the class HttpSession to store things that will later go into a database, consider putting them into a database in the first place. For example, some programmers put all of a user's shopping cart data into HTTP session and then store this information into a database as well, "just in case." For these situations, consider just keeping keys in HTTP session and looking up the rest of the state information in the database if and when needed. (This technique is especially handy if the state information is referenced infrequently.) Perform Code ReviewsReview the web application code for excessive HTTP session storage. Also, go over this problem with your web site team, especially programmers new to the web application space. Ideally, use the HTTP session to hold a few thousand bytes of data (under 2KB is ideal for most applications). If data is rarely used, and inexpensive to look up, then just leave it in the database and load it as needed. Use Code-Profiling ToolsMany tools are available for profiling Java applications. Consider using these tools to get a handle on how much data the HTTP session uses. (See Appendix C for a list of popular code-profiling tools available for Java.) Serialize the HTTP Session to a StreamMany web sites use a specialized servlet to write a user's HTTP session data to a stream and then measure the size of the stream to determine the size of the HTTP session. This allows you to check the HTTP session size easily in a production environment without introducing specialized tools into the environment. It also allows you to check the contents of the HTTP session to be sure everything it holds implements the serializable interface. (If an HTTP session contains non-serializable elements, this restricts your ability to share it in a clustered environment.) In addition to reducing the data kept in the average HTTP session, we also need to monitor how many HTTP sessions your web application keeps in memory at any given time. Optimizing this HTTP session cache reduces the total memory required by your HTTP sessions. Let's discuss a few techniques for managing the HTTP session cache. Reduce HTTP Session TimeoutMost application servers allow the administrator to reduce the HTTP session timeout interval, which specifies how long the HTTP session exists after the user's last interaction with the web site. This interval gives the user an opportunity to read pages returned from the web site without losing their state information. The interval also allows the web application server to recognize stale HTTP sessions. If the user does not return to the web site before the interval expires , the web application considers the user inactive and purges his corresponding HTTP session. Of course, the longer the timeout interval, the more unused HTTP sessions your site contains at any given point. Usually the application server sets the timeout interval to a reasonably generous period of time. (The IBM WebSphere Application Server sets HTTP session timeout to 30 minutes by default.) Reducing the timeout might help the HTTP session pressure in your JVM, but avoid setting the timeout too low. You'll anger users if you drop their HTTP sessions while they're still using your web site. Also, setting the timeout very low sometimes negatively impacts performance. An extremely low timeout period may cause the application server's HTTP session management routines to run frequently. Often these routines incur a significant overhead, thus diminishing any benefit of frequently cleaning the HTTP session cache. Before you change the timeout interval, however, check with the web application's development team. The J2EE specification also provides a method on the HttpSession class for modifying its timeout interval. The timeout set via this method overrides any value set administratively, so be aware of any timeout intervals set by the programming staff, and, of course, encourage them to externalize these interval values for tuning purposes. Support a Logout FunctionConsider supporting a logout function for your web site as either a button or menu item on your web pages. This lets users indicate when they've completed their visit, and allows your web application to immediately invalidate the user's corresponding HTTP session. (The web application invalidates the HTTP session via a method. Invalidation destroys the HTTP session right away rather than waiting for the timeout interval to elapse.) One caution regarding HTTP session invalidation : Earlier versions of the servlet standard allow web applications to share HTTP sessions. Don't remove HTTP session objects potentially in use by other web applications, if your application server supports the earlier spec level and your application uses this capability. While we recommend a logout feature, we don't really expect it to solve HTTP session management for your web site. Sadly, most users never touch the logout buttons on web sites they visit. Most users just move to the next web site without formally logging out of yours. So, while it provides some benefits, the logout function is only a part of an overall HTTP session management strategy. If your web application handles sensitive data (such as financial information) and may be accessed from a shared workstation or kiosk, consider a logout function to be a requirement. Logging out prevents subsequent users from obtaining a previous visitor's information via an existing HTTP session. Naturally, these applications generally support a very short HTTP session timeout interval and may force a logout after completing certain tasks . Keep the HTTP Session Working Set in MemoryThe working set of HTTP sessions belongs to the users currently engaged in using our web site. We want to keep these HTTP sessions available for fast access as the active users make requests. These HTTP sessions, therefore, need to remain in memory. In the next section, we discuss in detail some techniques for sharing HTTP sessions and keeping them in persistent storage. At this point, however, let's discuss the most common improper use of a persistent HTTP session store. Sometimes web sites desperate for memory reduce their HTTP session cache size and off-load most of their HTTP session data to persistent storage. This works like an operating system paging scheme: As the web application needs an HTTP session, the application server retrieves it from the persistent store. After use, the application server stores the updates to the HTTP session back to the database. While this sounds like a good idea at first, in practice it does not perform well. Accessing remote HTTP sessions takes time and increases network traffic. Particularly for web sites serving high request volumes or supporting large HTTP sessions, the remote HTTP session "retrieve on demand" approach quickly degenerates into abysmal performance. (Of course, these web sites are usually the most eager to try this technique.) Always keep your working set of HTTP sessions in the memory cache. Use any persistence or sharing mechanism only to store/share HTTP sessions as an outage precaution. Do not try to use these mechanisms as an extension of the in-memory HTTP session cache. You may need to configure multiple application server instances (see Multiple Instances: Clones later in this chapter) to get enough total heap size to hold all the HTTP session data. Sharing HTTP SessionsMany application servers support sharing HTTP session data among many instances of the application server functioning in a cluster (see Clones below in this chapter, and Web Site Topologies in Chapter 3). Strategies for sharing session data vary. Sharing HTTP session data allows the cluster to failover a visiting user. If the web application server handling the user's requests fails, the web site may route the user's request to another application server in the cluster. If the user's HTTP session data resides in a common store, this application server pulls in the user's state data and continues the user's visit to the site without interruption. Figure 2.7 demonstrates HTTP session failover using database persistence. Figure 2.7. Failover with a persistent HTTP session database. From "Changing Your Application Tactics: Successful Web Application Strategies for Production Websites," paper presented by Stacy Joines at Solutions 2001, San Francisco, CA. IBM Corp. 2001. Reprinted by permission of IBM Corp. Some vendors share the sessions through a shared network update, either to all other servers in the cluster or from a "primary" server to a "secondary" server. In this strategy, the session data resides in the memory of one or more application servers in the cluster. Another technique places all the HTTP sessions in the cluster in a shared, persistent datastore (usually a relational database). Yet another sharing method involves using flat files on a shared file system to store the session data. Each strategy generates its own performance issues. Clustered network updates potentially generate lots of network traffic and spread the memory burden of the HTTP sessions throughout the cluster. Likewise, persistent session storage requires transfer of data between the application server instances and the datastore. Serializing HTTP session data and writing it to disk is also slow. HTTP Session Sharing TipsIf you share HTTP session data within your application server cluster, keep the following performance pointers in mind. Keep HTTP Sessions SmallMoving HTTP session data across the network increases the need for small HTTP sessions. Small HTTP sessions reduce the database burden for persistent session storage and keep the clusterwide memory requirements manageable for a networked HTTP session sharing system. Small HTTP sessions also use less network bandwidth during their transfers. Keep HTTP Session Data SerializableObjects placed in the HTTP session should implement the java.io.Serializable interface. (This includes the objects themselves , as well as anything they include or from which they inherit.) The application server serializes the HTTP session data onto the network when transferring the data. If the data does not implement the Serializable interface, the web application server throws an exception when it tries to transfer it to a shared database or other store. These serialization exceptions often take the web site team by surprise. HTTP session sharing, in theory, requires no programming changes to implement. (The application server administrator determines whether to enable this feature.) However, if the application developers did not prepare their code for HTTP session sharing, the first attempt by the administrator to use this feature often fails. While enabling HTTP session sharing may seem as easy as "flipping a switch" in load testing or production, objects placed in the HTTP session actually determine whether HTTP session sharing works. Check the content of your HTTP sessions during code reviews to avoid encountering this problem in testing or production. Avoid Nontransferable DataSometimes HTTP session data does not transfer in a meaningful way to another web application server instance. For example, if your application programmers stuff the HTTP session with things like thread handles, this data provides no value to another web application server instance on failover. (Remember, each server instance lives in its own Java Virtual Machine.) Mark nontransferable variables in your HTTP session objects with the transient keyword, so they won't be serialized. Of course, you must write your code to handle failover by recreating the transient data within the context of the new web application server instance, as needed. This leads to a programming issue for your web application. Avoid using information specific to a machine or web application server instance whenever possible. In addition to thread handles and the like, avoid depending on a machine's IP address and similar data that make it difficult for your application to failover. Again, rigorous code reviews and programmer education provide your best protection for these scenarios. Enterprise JavaBeans (EJBs)Enterprise JavaBeans (EJBs) allow your web site applications and other traditional applications to gain access to centralized business logic contained in distributed components . They provide a layer of abstraction between your applications and your database. In fact, your EJBs may consist of data assembled from various datastores. This section covers the EJB basics so that we can discuss some of their performance characteristics. If you need more information about EJBs, we list several excellent books in the Bibliography. EJBs exist inside an EJB container, which controls the life cycle of the Beans under its care. This management includes instantiating and destroying EJBs, managing EJB pools, and even interacting directly with databases on behalf of certain types of EJBs. EJBs come in two basic flavors: Session Beans and Entity Beans. Session Beans live a transient existence inside the container. They contain business logic and may contain state for a specific client. Session Beans are either Stateful or Stateless .
Entity Beans represent a persistent entity. The data contained by an Entity Bean generally originates from a single database row, although it could consist of an assemblage of data. Likewise, EJBs most commonly store persistent data in a database, although other persistence mechanisms also exist. The J2EE specification defines two types of Entity Beans: Container-managed Persistence (CMP), or Bean-managed Persistence (BMP).
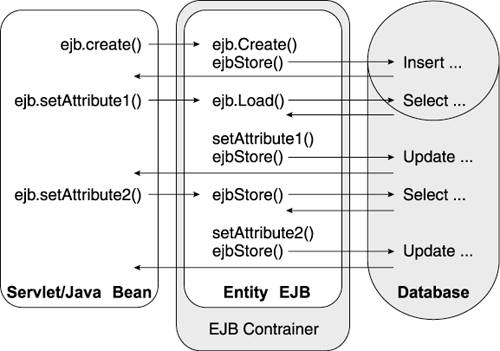
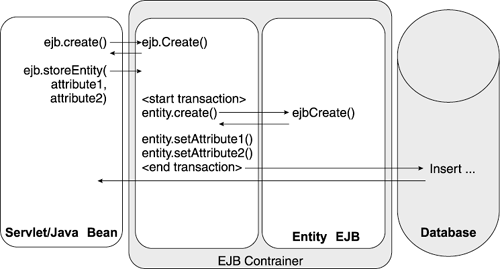
EJB Performance TipsEJBs give you excellent support for sharing your business logic between your web applications and thick client applications. EJBs also perform and scale very well in web applications if you plan ahead for performance and scalability. Let's discuss some of the best practices to ensure good EJB performance. Use Stateless Session Beans as Fa §adesServlet or JavaBean programmers often interact directly with Entity Beans. On a typical user request, the servlet makes several calls to Entity Beans to gather the data required to satisfy the request. This, however, is not the best strategy for high performance. Direct interaction with Entity Beans from a servlet usually results in several remote method calls. These calls tend to be performance expensive, so reducing the number of remote calls in your code path makes sense. Direct interaction also stresses the transactional boundary between the servlet and the EJB. Entity Beans synchronize their state after each transaction, often needing two database calls for each method called. When a servlet accesses the Bean directly, each "getter" method becomes a transaction. This usually means a database call to get the current data from the database and then another to update the database at the end of the method, as shown in Figure 2.8. Figure 2.8. Enterprise JavaBean transactions without a fa §ade Bean To circumvent these problems, use a Session Bean as a fa §ade to Entity Beans. The Session Bean contains the logic to gather data from one or more Entity Beans and return this information to the calling application, which yields several advantages. The programming interface becomes much simpler: The client calls only one method on a single EJB to perform complex interactions. This reduces the remote method calls for these complex interactions (the Session Bean doesn't require a remote call to Entity Beans in the same EJB container as itself). Likewise, if the Session Bean shares an EJB container with the Entity Beans, it also controls the transactional boundary for the entire interaction. The Session Bean controls the transaction for all other EJBs involved in implementing the function. The Entity Bean only synchronizes its state when the Session Bean reaches a transactional boundary (such as the completion of the Stateless Session Bean's method). Figure 2.9 shows an example of transactional boundaries using fa §ade Beans. Figure 2.9. Enterprise JavaBean transactions using a fa §ade Bean Also, fa §ade Beans prove useful when coordinating transactions across multiple Entity Beans, as well as other Session Beans performing direct JDBC calls. This requires the Entity Beans involved to implement the correct transaction setting, usually TX_SUPPORTS or TX_REQUIRED. Use Direct JDBC CallsIf you manipulate multiple rows of your database when retrieving an Entity Bean, consider using direct JDBC calls from within a Stateless Session Bean to perform a "read" of the Bean's data. Later, if you need to update or delete the data (or create new data), use an Entity Bean to control these tasks. This approach sometimes saves time by reducing expensive "finder" overhead. It also provides performance benefits to applications that perform lots of read activity, but few updates, on a complex database table structure. Avoid Fine-Grained EJB Data ModelsDon't overdo it with the Entity Beans. In some cases, we've seen a simple application request use literally hundreds of different Entity Beans. Obviously, your web site cannot handle high volumes if you load hundreds of EJBs on each call. Simplify the model and consolidate your data into larger Beans. Also, reduce the Beans involved by letting your SQL and the database do more work for you. Use database joins to consolidate your data at the database. Mark Methods as Read-OnlyThis setting reduces the database interactions required to execute your EJB methods and provides performance benefits to your application. Check with your application server vendor for the implementation of this J2EE feature. Consider Scalability Issues of Stateful Session and Entity BeansSince these Beans have identity and state, each instance only exists in one EJB container in your web site. Stateless Beans, on the other hand, exist in any convenient container (often, the EJB container running in the same JVM as the web container), or in the container with the most processing power available. This flexibility often makes Stateless Session Beans more scalable than other EJB choices. Cache Bean Contents in Custom FindersCustom finders returning an Entity Bean collection make n + 1 database calls: one to perform the "find" and one call per Entity Bean instance to instantiate the Entity Bean's contents. Depending on the number of Entity Beans returned, their size, and the frequency with which you access them, you may decide to cache the results of a custom finder. Before you implement a custom-finder cache, consider how much memory the cache requires. Again, caching at your server only works to your advantage if it does not consume excessive amounts of memory. Likewise, caching only works if the data retrieved does not change while cached. Avoid EJB PassivationWe discussed earlier the inefficiencies of the file system in high-volume web sites. EJB containers passivate inactive Stateful Session Beans if the container begins to run out of room when creating new Beans. Passivation dumps the state of the Bean to a file. If a subsequent request needs the passivated Bean, the container must interact with the file system to reload it. To avoid passivation, remove unneeded Stateful Session Beans as soon as possible. Of course, eventually the container times out and removes old Stateful Session Beans, but if your web site moves high volumes, the container may be forced to passivate the Bean before the time-out. Use the EJB remove() method to remove unneeded Stateful Session Beans from the container. Also, consider shortening the timeout period for the Stateless Session Beans. Cache Homes for EJBsAs stated earlier in the discussion on servlets, avoid expensive JNDI lookups whenever possible. As we discussed in the servlet section, you should use caching techniques to reduce or eliminate repeated JNDI lookups. Consider Broker objects or other design patterns to manage JNDI lookups, as well as any other cacheable operations. (Caching EJB homes is always a good idea.) Tuning EJB ContainersEJB containers from different vendors often include some unique settings that affect their performance, but some settings span all vendor implementations . Let's take a quick look at some of the more important EJB container settings. Of course, you should check your application server vendor's documentation for other tuning settings. Pool SizeContainers maintain pools of EJB instances. You may configure the maximum size for these pools, which determines how many instances your EJB container controls at any point in time. (Some containers support a "per pool" setting, while others use a grosser measurement for the total EJB instances managed by the container.) Configure your pool size to contain the working set of EJBs your web application requires. Your pool should at least accommodate the EJB instances required to satisfy your maximum simultaneous requests. (Keep in mind that these requests may originate from multiple web containers in a large, distributed web site.) At the same time, you must prevent the EJB container from exhausting its JVM heap with excessive EJB instances. Thus, the size of the EJB pool really depends on two factors: demand and data size. Use your performance test to help define an optimal setting for your EJB pool. Understanding how many EJB instances you need at peak loading, as well as the size of these instances, also gives you significant insight in setting an optimal EJB pool size. (Also, as with web containers, some EJB containers permit unbounded pool growth, which you should avoid because it eventually leads to memory exhaustion. Instead, enforce a hard maximum on the EJB pool size based on your testing. Different vendors support setting this hard maximum in different ways, so check the vendor's documentation for details.) Cleanup IntervalSome containers allow you to specify how frequently the container sweeps its pool for old objects. Reducing the interval between sweeps reduces the number of old objects left in your pool and gives you more room to create new objects as needed. However, running the sweeping routine too frequently may degrade performance, depending on the "weight" of the sweeping routine. Consider adjusting this interval during your performance testing to find an adequate setting for your application. Transaction Isolation LevelThe transaction isolation level controls the visibility of uncommitted changes within the underlying database. You may specify the application level at the EJB or EJB method level. (Additional rules apply if your application calls multiple methods with differing transaction isolation levels.) For best performance, use as liberal an isolation level as possible. However, this really depends on the application as well as the other objects and applications sharing the underlying database. Too low a setting may result in unexpected side-effects such as multiple, simultaneous updates to the same data row. (Obviously, performance considerations take a back seat to data correctness issues.) Likewise, too high a setting results in application deadlocks. Local versus Remote InterfacesAs more vendors implement the EJB 2.0 specification, the features of this specification level become more important. For example, you may decide to call your EJBs via local interfaces , rather than remote interfaces . Local interfaces work when the calling client (such as a servlet or JavaBean) shares the same JVM as the called EJB. By avoiding a remote method call, this protocol provides significant performance benefits. However, you cannot use local interfaces with widely distributed web sites. If your EJBs reside in a remote JVM, you must use remote interfaces to access them. (See the discussion on clones later in this chapter.) Relying on local interfaces for performance limits your web site scalability. If you anticipate scaling your web site in the future, develop a performance strategy that assumes the possibility of remote interfaces. Message-Oriented Middleware (MOMs)The EJB 2.0 specification also introduces message-driven Beans . This feature enables Message-Oriented Middleware (MOMs) like IBM's MQ-Series, to call functions implemented within EJBs. Because this technology is so new, very few performance guidelines exist regarding it. However, the reverse practice, where EJBs access a MOM for data, is quite common. The best practice for accessing MOMs via an EJB, or from any other object in web application (servlet, JavaBean, etc.), for that matter, is the following. First, be aware that MOMs operate asynchronously, while web applications operate synchronously. Many web sites try to mask the asynchronous nature of a MOM within the synchronous operation of their web application by placing the web application in a wait state until the MOM completes the requested task. However, MOMs do not guarantee delivery within a particular time frame; they only guarantee eventual delivery. Therefore, you cannot count on the responsiveness of a MOM. Be very careful accessing an asynchronous MOM inside your synchronous web application. As noted earlier, indefinite wait within a web application often leads to disaster. Plan ahead for long response times and outages within the MOM system. Just because your MOM normally responds quickly, don't assume that it always will. Database Connection Pool ManagementDatabase connection management in the servlet world proves difficult for former thick client developers. Thick client best practices encourage the programmer to obtain a database connection once and cache it inside the client for all future requests. This works well inside a thick client because it costs a lot of time to obtain a new connection; however, it is not practical on a web site. Your web site may support thousands of logged-in users at any given time and may run dozens of different servlets over the course of a minute. Obviously, assigning a database connection to a given user, or even to a given servlet, isn't practical. Instead, most web applications use pooled database connections. The most common pooling mechanisms are the javax.sql.ConnectionPoolDataSource or the javax.sql.XADataSource. The JDBC specification defines the DataSource class, which is in turn implemented by the vendors. Many early application servers also supported their own implementations of data sources, or similar pooling constructs, prior to the JDBC standard. The data source allows the administrator to define the number of database connections available to the running web applications. An example flow using a data source goes as follows :
By "immediately," we mean within the method that gets the connection. Don't pass a result set around to various layers (JSPs, other servlets, and so on) in order to manipulate the data from the database. Loop through the result set, pulling the data out into your own collection, and then close the result set, statement, and connection. (Failing to close the statement object before returning the connection to the pool sometimes results in an error for the next application reusing the connection.) Database Connection Management TipsThe data source and its database connection pool make managing database connections trivial. However, many programmers fail to use the database connection pool properly, if at all. Let's discuss some of the best practices for database connection management. Return the Database Connection to Its Pool QuicklyMany servlet writers return the database connection to the connection pool as an afterthought when all the processing inside the servlet completes. This makes the connection unavailable to other servlets for significant periods of time (a half second or more, in some cases). Return the connection as soon as possible to the connection pool. Also, consider optimizing your code to use database connections more efficiently . Return Connections No Matter What HappensMake sure you close everything within finally clauses in your code. Otherwise, if an exception occurs, you may "leak" a database connection or leave a statement open . While the connection pool may eventually "reap" the lost connection (discard it and create a new one), this process only starts after a generous timeout interval. Too many lost connections may consume all of the connections in your database connection pool, and this may result in a frozen web site. Try to return connections to their pools even in the event of an exception. Also, try to close statements to avoid returning a connection to the pool in an unusable state. Use the Connection Pooling FeatureA few servlet writers refuse to use the data source at all. They continually obtain and release database connections inside their servlets. The performance overhead of this approach is breathtaking. Use a connection pool, even if you need to make some changes in your existing code. The extra effort almost always pays for itself in enormous performance benefits. "Custom" Connection Pool Managers versus Data SourcesSometimes we may encounter shops using custom connection pools. Often, these shops wrote their own pooling logic prior to the adoption of the DataSource object in the JDBC standard. Connection pools contain surprisingly complex logic for things such as recognizing and reaping dead connections, growing and shrinking the pool in accordance with demand, and refreshing connections after a database outage. Often home-grown data sources require considerable tuning, and they may not scale as the site continues to grow. Take advantage of the tuning and expertise built into your vendor's implementation and convert to the JDBC standard data source. Web ServicesAnother relative newcomer to the web application space is the concept of web services. Regrettably, the web services technology lacks a body of performance expertise at this point. (Performance guidelines usually follow some number of practical experiences with a new technology.) Nonetheless, based on what we do know about web services in general, we tentatively offer some rough advice. Again, these touch web services performance at a high level. Use solid performance testing of your implementation to better understand your specific performance profile. Use UDDI (Universal Description, Discovery and Integration) with CareRepeatedly locating a web service, parsing the interface description, and mapping parameters to the interface seriously degrades the performance of your web application. For better performance, consider selecting the services you plan to use during the development of your web application. Directly code interactions with these services rather than repeatedly using UDDI at runtime. Of course, hard-coding services may result in some flexibility restrictions on your applications, but it may make sense as performance trade-off for heavily used web application functions. Minimize SOAP Data TransfersSOAP (Simple Object Access Protocol) is relatively slow. Web services applications often spend most of their time parsing and generating the XML used by SOAP rather than executing logic. [8] Reduce the parsing overhead by keeping the data transferred via SOAP to a minimum.
Monitor Changing Web Site Usage PatternsProviding web services functions often changes the usage patterns of your web site. Most web site designs focus on direct interactions with a web user. However, web sites providing web services functions often find themselves playing the role of "middleware" for other web applications using their functions. For example, a search engine or sports site often handles more requests for information actually displayed by other web sites than direct requests from web users. This new role as middleware often shifts the priorities of the web site providing the web services function. For example, key features such as the web site's home page become less important. However, other features, such as returning the high school basketball scores for all teams in a particular zip code become heavily used through the web services function. If your web site provides web services functions, monitor the usage patterns of your web site. You may discover a need for additional resources, such as database connections, to support increased demand for certain web application functions. Also, this increased demand may require performance improvements in previously underperforming (but seldom-accessed) functions now receiving considerably more traffic. |
EAN: 2147483647
Pages: 126