Selecting Data
|
The richest statement in SQL is the SELECT statement, and it is used to retrieve data from ADS to the client application. This section begins with a look at simple selections involving fields and expressions. Later, you will learn how to select specific records, as well as how to sort, group, and link data from two or more tables.
Selecting and Expressions
This section demonstrates how you populate one or more columns and zero or more rows of a result set using the SELECT statement.
Selecting Fields
In its simplest form, SELECT is used to unconditionally retrieve one or more fields from a table. For example, the following statement selects the First Name field from the EMPLOYEE table:
SELECT "First Name" FROM EMPLOYEE
If you have two or more fields to select from, you enter a comma-separated list of fields you want to select. For example, this query returns the First Name and Last Name fields:
SELECT "First Name", "Last Name" FROM EMPLOYEE
If you want to select all fields, you use the * (asterisk) character, like this:
SELECT * FROM EMPLOYEE
Selecting Using Expressions
You are not limited to simple field selection in the SELECT list. You can include expressions that make use of one or more of the following: field references, literals, SQL scalar functions, and operators. For example, the following query returns the concatenation of the First Name and Last Name fields:
SELECT "First Name" + ' ' + "Last Name" FROM EMPLOYEE
If you execute this query, you will notice something interesting, as shown in Figure 10-1. There is a large space between the first-name and last-name values, even though the query concatenates these values with a single space. This is because the First Name and Last Name fields include trailing blank spaces. To produce a more normal looking full name, you need to trim these trailing values using the RTRIM function, as shown in the following query:
SELECT RTRIM("First Name") + ' ' + RTRIM("Last Name") FROM EMPLOYEE 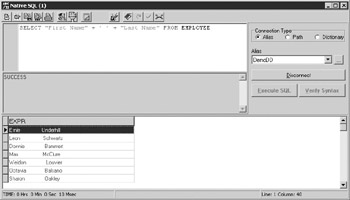
Figure 10-1: Concatenated string fields include trailing spaces.
Actually, your SELECT list doesn’t need to include any field names at all. For example, the following query returns the value 1 for each record in the CUSTOMER table:
SELECT 1 FROM CUSTOMER
Normally, the result set returned from a SELECT query will use the names of the selected columns, or a temporary name, such as EXPR, EXPR_1, EXPR_2, and so forth, for the columns that are returned. Alternatively, you can provide specific names for the columns by following the expression with the AS keyword, followed by a column name. Just as you do with field names, if the new column name begins with a number or contains special characters, you must enclose it in either double- quotation marks or square brace delimiters, as shown here:
SELECT RTRIM("First Name") + ' ' + RTRIM("Last Name") AS "Full Name" FROM EMPLOYEE | Note | The use of expressions or scalar functions in the SELECT list always produces a static cursor. |
Using CASE Statements
There is a special control structure, called CASE, that you can use to create conditional expressions in the SELECT clause. The CASE statement can evaluate two or more expressions, and always results in a single expression that will return a column in the result table.
There are two forms of the CASE statement. In the simplest form, CASE is followed by an expression that is evaluated by one or more WHEN clauses. Each WHEN clause compares a value to the CASE expression, and includes an expression following the THEN keyword that the CASE clause will evaluate to if the comparison returns a Boolean True.
If none of the WHEN clauses evaluate to True, you can include an optional ELSE clause, which returns the expression of the CASE clause. The CASE clause evaluates to the expression defined by the first WHEN clause that evaluates to True, or the value of the ELSE clause, if provided, when none of the WHEN clauses evaluate to True.
The following query demonstrates this form of the CASE statement. This example also shows connecting to a table bound to another data dictionary from within the current data dictionary, a topic described in Chapter 6, since SQL provides the only way to access tables from two or more data dictionaries with one connection:
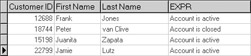
SELECT "Customer ID", "First Name", "Last Name", CASE Active WHEN True THEN 'Account is active' WHEN False THEN 'Account is closed' ELSE 'Account status unknown' //if NULL END FROM Shared.CUST
This query produces the following result set:
The second form of the CASE statement permits you to evaluate two or more different expressions. In this form, the CASE statement is not followed by an expression. Instead, it is followed by one or more WHEN clauses, each of which evaluates an expression and includes the expression that the CASE statement will return if that WHEN clause evaluates to True.
Like the first form of CASE, there is also an optional ELSE clause, which includes the expression that the CASE statement will evaluate to if none of the WHEN clauses evaluate to True. The CASE statement evaluates to the expression associated with the first WHEN clause to evaluate to True; otherwise, it evaluates to the ELSE clause expression, if provided. The following is an example of this form of the CASE statement. As you can see, each of the WHEN clauses evaluates a different expression:
SELECT "Invoice No", "Customer ID", "Invoice Date", "Date Payment Received", "Invoice Due Date", CASE WHEN "Invoice Due Date" <= CURDATE() AND "Date Payment Received" IS NULL THEN 'Waiting for payment' WHEN "Invoice Due Date" > CURDATE() AND "Date Payment Received" IS NULL THEN 'Invoice is overdue' WHEN "Date Payment Received" > "Invoice Due Date" AND "Date Payment Received" IS NOT NULL THEN 'Invoice was paid late' ELSE 'Invoice was paid on time' END AS "Invoice Payment Status" FROM INVOICE
Using ROWID
You can also use the special ROWID identifier to retrieve the internal record identifier in a query. Unlike any other field in a table, the ROWID of a particular record never changes, making it the most reliable means by which you can access the same record repeatedly.
SELECT ROWID, "First Name", "Last Name" FROM CUSTOMER
Querying Free Tables and Other Dictionary Tables
In the FROM list of the preceding queries, the name of a table in the current data dictionary is listed. It is also possible to include both free tables as well as tables that are bound to another data dictionary in your SELECT statements.
If your free table is in the same directory as your data dictionary, simply include the table name as though it were bound to the data dictionary. So long as the CUST.ADT table that you created in Chapter 2 is still in the same directory as the DemoDictionary data dictionary, the following query should select all fields and all records from it:
SELECT * FROM CUST
If the free table is not in the same directory as the data dictionary, you can include a path (either a relative or a fully qualified path) to the table. For fully qualified paths, you are strongly encouraged to use UNC (universal naming convention) names. For example, if the CUST.ADT table is on the DATASERV computer in the directory named AppData in the C$ share, your SELECT statement might look something like the following:
SELECT * FROM "\\DATASERV\C$\AppData\cust.adt"
If the table you want to query is bound to another data dictionary, you have two alternative techniques that you can use to access that table. So long as the table is accessible in the other data dictionary to a user whose name and password you used to connect to your current data dictionary, you can qualify the table name with the name of the data dictionary, using dot notation. For example, if the CUST table is bound to the Share.ADD data dictionary, and Share.ADD is in the same directory as DemoDictionary, you can use the following statement:
SELECT * FROM "Share.ADD".CUST
If the Share.ADD data dictionary is not in the same directory, you still use dot notation but you must specify the path, as you did with a free table not in the same directory. For example, if Share.ADD is on the DATASERV computer in the directory named AppData in the C$ share, the following SELECT statement would access the CUST table:
SELECT * FROM "\\DATASERV\C$\AppData\Share.ADD".CUST
If the data dictionary to which the CUST.ADT table is bound does not include a user name and password that has rights to the CUST.ADT table, you must use the second alternative, which is to use a data dictionary link. For example, imagine that you have a data dictionary link named Shared in your current data dictionary, and this link specifies a user name and password in the data dictionary to which CUST.ADT is bound. You can access the CUST table from your current data dictionary using the link name in dot notation with the table name. This is shown in the following query:
SELECT * FROM Shared.CUST
If the link name includes special characters, you must enclose it in double quotation marks or square braces.
Data dictionary links are discussed in Chapter 6.
Conditional Selection
The preceding queries select all records, which is fine when your tables are small. However, in many instances, especially when you have a lot of data, you want to restrict your selections to a specific group of records. You use the WHERE clause in a SELECT statement to perform record selection. (The HAVING keyword can also influence record selection, but only when you are working with groups of records. HAVING is discussed later in this chapter.)
You follow the WHERE keyword with a Boolean expression. In most cases, this expression will include one or more field references. For example, the following query selects all fields from the ITEMS table where the Discount field contains the value 15 or higher:
SELECT * FROM ITEMS WHERE Discount >= 15
WHERE clauses often have many expressions combined using the AND and/or OR operators. For example, the following query selects these same records, but only where the Product Code field contains the value G54039:
SELECT * FROM ITEMS WHERE Discount >= 15 AND "Product Code" = 'G54039'
| Note | The performance of queries that include WHERE clauses can be dramatically improved by the presence of one or more appropriate indexes. Also, if you use a MEMO or BLOB field in a WHERE clause, the query returns a static cursor. |
SQL also supports several keywords that can be used in the WHERE clause. These include BETWEEN, IN, and LIKE. Each of these keywords is described in the following sections.
Using BETWEEN
Use BETWEEN to test whether an expression is within a range of values. If the value is in the range, BETWEEN evaluates to a Boolean True, and False otherwise. For example, the following query selects all invoices between May 7th and June 17th, 2005:
SELECT * FROM INVOICE WHERE "Invoice Date" BETWEEN '2005-05-07' AND '2005-06-17'
You can precede the BETWEEN keyword with the NOT keyword to select records that are not in the range.
Using IN
You use IN to compare an expression to either a list of values or a single-field subquery. (Subqueries are introduced in Chapter 9.) The expression evaluates to True if the expression on the left-hand side of the comparison is in the list or subquery on the right-hand side.
Assuming that employees in the Sales and Marketing and Administration departments can initiate invoices, and that these departments have the corresponding department codes 101 and 108, the following query returns the records for employees that can initiate invoices:
SELECT * FROM EMPLOYEE WHERE "Department Code" IN (101, 108)
Although this same result could also be achieved using a series of WHERE clauses with OR operators, using IN is much simpler.
The following query performs the same task as the preceding one, but uses a subquery instead of a list of values:
SELECT * FROM EMPLOYEE WHERE "Department Code" IN (SELECT "Department Code" FROM DEPARTMENTS WHERE "Department Name" = 'Administration' OR "Department Name" = 'Sales and Marketing')
Precede the IN keyword with the NOT keyword to return records that are not in the set.
| Note | The use of a subquery with the IN operator in a WHERE clause always returns a static cursor. |
Using LIKE
You use the LIKE operator to compare an expression to a pattern that includes one or more wildcard characters. The % (match any) wildcard character matches zero or more characters, and the _ (match one) wildcard character matches any one character. For example, the following query will return all customer records where the last name begins with the letter S:
SELECT * FROM CUSTOMER WHERE "Last Name" LIKE 'S%'
By comparison, the next query will return all customer records where the last name begins with S and is exactly five characters in length (there are four underscore characters following the S):
SELECT * FROM CUSTOMER WHERE "Last Name" LIKE 'S____'
| Note | The use of trailing wildcard characters permits an appropriate index to be used for searching data, leading to faster queries. If you include a leading wildcard character (such as %s), indexes cannot be used, and ADS must search the physical records of the table. Also, the use of LIKE in a WHERE clause always produces a static cursor. |
Sorting Data
Unless you specifically request that the records returned by the SELECT statement are sorted, a query will return records in the natural order of the table. As discussed in Chapter 3, this order is affected by the order in which records are entered, and has nothing to do with the data contained in those records.
To sort the results in a result set, add an ORDER BY clause to your SQL statement. ORDER BY clauses can be constructed in one of two ways. You can specify the ORDER BY columns either by name or by number. For example, the following SELECT statement will return the records of the PRODUCTS table ordered by the Description field:
SELECT * FROM PRODUCTS ORDER BY Description
If you want to sort by two or more fields, separate the field names with commas. Also, the default order direction is an ascending sort order, from lowest to highest. You can follow your field name with DESC to sort in descending order, if you like. (You can also use the keyword ASC, but since ascending is the default order, this keyword has no effect.) The following query demonstrates a two-field sort where the Invoice Date field is sorted in descending order:
SELECT "Invoice No", "Employee ID", "Invoice Date", "Date Payment Received" FROM INVOICE ORDER BY "Employee ID", "Invoice Date" DESC
Actually, the ORDER BY clause can be any valid expression except those that use MEMO or BLOB fields. While the following example is obviously a meaningless sort order, it demonstrates the level of flexibility that you have when selecting which fields or expressions to order by:
SELECT "Invoice No", "Customer ID", "Invoice Date" FROM INVOICE ORDER BY 100 - "Employee ID"
Instead of using field names or expressions in the ORDER BY clause, if the fields or expressions that you want to sort by appear in the SELECT list, you can simply supply numerals that refer to the positions of the fields or expressions that you want to sort by. Just as you do when sorting by name, these numerals are separated by commas if you want to sort by more than one column, and can be followed by the DESC or ASC keywords. For example, the following query produces the same result set as did an earlier query in this section:
SELECT "Invoice No", "Employee ID", "Invoice Date", "Date Payment Received" FROM INVOICE ORDER BY 2, 3 DESC
You can even sort by position when using the * (select all) symbol, as shown here:
SELECT * FROM CUSTOMER ORDER BY 3, 2
| Note | The performance of queries that include ORDER BY clauses can be dramatically improved by the presence of one or more appropriate indexes. Also, you cannot use MEMO or BLOB fields in an ORDER BY clause. |
Grouping Data
Grouping data is necessary when you want to perform operations across one or more records. There are two primary types of operations that you perform across records. The first involves selecting the unique values, or combination of values, across all records in a table. The second involves calculating simple descriptive statistics.
Selecting Unique Values
You select unique values using the DISTINCT keyword. For example, if you want to know which employees are responsible for one or more sales appearing in the ITEMS table, you follow the SELECT keyword with the DISTINCT keyword, which you then follow with the list of fields or expressions you want unique values for. For example, consider the following query:
SELECT DISTINCT "Employee ID" FROM INVOICE
This query produces a table that has only one instance of each Employee ID that appears in the table, as shown here:

You can use DISTINCT with any combination of fields or expressions, in which case the result set will contain one column for each field or expression, and one record for each unique combination of those field values. For example, the following query selects each unique combination of the Employee ID and Customer ID fields:
SELECT DISTINCT "Employee ID", "Customer ID" FROM INVOICE
Of course, you can use WHERE clauses like those shown earlier in this chapter to select the distinct data from some subset of records from one or more tables.
| Note | You cannot use MEMO or BLOB fields in the SELECT list of DISTINCT queries, although you can use them in the WHERE clause. Also, queries that use the DISTINCT keyword always return a static cursor. |
Using TOP
The TOP keyword permits you to select some, but not all, of the records associated with the SELECT. You use TOP by immediately following the SELECT keyword by the TOP keyword. TOP is followed by an integer, which will either define the number of records you want returned or the percent of the overall number of records that you want returned. When selecting a percent of the records, follow the integer with the PERCENT keyword.
The following query returns only the first five of the records from the INVOICE table:
SELECT TOP 5 * FROM ITEMS
This next query returns the top five percent of the records from the ITEMS table:
SELECT TOP 5 PERCENT * FROM ITEMS
The TOP keyword is often associated with queries that calculate statistics across records (described next). For example, using TOP you can calculate which employees are responsible for the top ten percent of sales, or which five customers are responsible for the most purchases.
Calculating Simple Descriptive Statistics
Another operation that you can perform across records is the calculation of simple statistics. Advantage SQL, like most other SQL languages, supports five descriptive statistics: average (AVG), count (COUNT), maximum (MAX), minimum (MIN), and total (SUM).
Each of these statistical functions takes a single parameter, which can be any field or expression that can appear in the SELECT list. These functions return an expression appropriate for the function. For example, the following query returns a result set that calculates the sum of the Quantity field in the ITEMS table:
SELECT SUM(Quantity) FROM ITEMS
In this query, the sum of a single field was requested. However, there is no reason why you cannot perform the operation on an expression, as shown in the following query, which calculates the total value of items purchased in the ITEMS table:
SELECT SUM(Quantity * Price) FROM ITEMS
The COUNT function is slightly different from the other functions in that it can accept either a field or expression, or the * character. When passed the * character as an argument, COUNT calculates the number of records. For example, the following query returns the number of records in the INVOICE table:
SELECT COUNT(*) FROM INVOICE
| Note | A query that includes one or more aggregate functions always returns a static cursor. |
Using GROUP BY
Instead of calculating the preceding statistics across all records, you might want to calculate the statistic separately for groups of records. For example, rather than calculating the number of records in the invoice table, you might want to calculate the number of invoice records for each employee. In order to do this, you need to group by employee.
Defining groups within a table is performed using the GROUP BY keywords. You follow the GROUP BY keywords with a list of one or more fields or expressions. The statistic is then calculated once for each unique combination of the values within the group. For example, the following query returns the number of invoices associated with each employee:
SELECT COUNT(*) FROM INVOICE GROUP BY "Employee ID"
There is one problem with this query, however. As you can see from the result set that this query returns, although the statistics were calculated, there is no way to know for which employee each calculation applies:

In order to display which employee each count is associated with, you need to include the “Employee ID” field in the SELECT list.
Another problem with this query is that the values that are calculated appear using a default name in the result set, which in this case is EXPR. As you learned earlier in this chapter, you can assign a name to a column returned in the result set using the AS keyword. Using AS to assign a meaningful name to calculated columns is especially important when you are calculating both statistics and expressions. The following is an improved version of the preceding query:
SELECT COUNT(*) AS "Count of Invoices", "Employee ID" FROM INVOICE GROUP BY "Employee ID"
This query produces the following result set:

When you include fields or expressions in the SELECT list, other than the statistical operator, you must also include those fields and expressions in the GROUP BY list. This requirement is obvious if you consider the following illegal SQL statement:
//The following query is illegal, and generates an error SELECT COUNT(*) AS "Invoice Count", "Employee ID", "Customer ID" FROM INVOICE GROUP BY "Employee ID"
Consider what this query is asking. It is instructing ADS to calculate the number of invoices for each Employee ID, and to include the Customer ID in the result set. The problem is that each employee likely made sales to two or more customers. Since the result set will have only one record for each employee (by virtue of Employee ID being the only field in the GROUP BY clause), there isn’t any way to include the one or more Customer IDs. If you want to see the customer that each employee made a sale to, you must also include the Customer ID field in the GROUP BY clause, as shown in the following query:
SELECT COUNT(*) AS "Invoice Count", "Employee ID", "Customer ID" FROM INVOICE GROUP BY "Employee ID", "Customer ID"
This query produces the following result set:

Similar to ORDER BY, you can also use the column ordinal numbers instead of column names in the GROUP BY clause:
SELECT COUNT(*) AS "Invoice Count", "Employee ID", "Customer ID" FROM INVOICE GROUP BY 2, 3
| Note | You cannot use MEMO or BLOB fields in the GROUP BY clause, although you can use them in the WHERE clause. Also, queries that include GROUP BY always return a static cursor. |
All of the preceding examples calculate the resulting statistic based on all of the records in the table. If you want to calculate the statistic across some, but not all of the records, you have two options. One option is to use a WHERE clause.
As you learned earlier in this chapter, WHERE clauses limit the SELECT operation to those records for which the WHERE Boolean expression evaluates to True. For example, the following query counts the number of invoices entered between January 1st and December 31st, 2004, assuming that your date format is set to mm/dd/ccyy:
SELECT COUNT(*) FROM INVOICE WHERE "Invoice Date" BETWEEN '1/1/2004' AND '12/31/2004'
Using HAVING
Another way to limit which records are considered is to use a HAVING clause. Unlike a WHERE clause, which is used to select records based on values and expressions related to individual records, you use a HAVING clause to base the selection on statistics calculated across records, as defined by the GROUP BY clause. For example, consider the following query:
SELECT Count("Invoice No") AS "Count of Invoices", "Employee ID" FROM INVOICE GROUP BY "Employee ID" HAVING COUNT("Invoice No") > 10 This query calculates the total number of invoices associated with each employee, but only for those employees responsible for ten or more invoices. Employees with ten or fewer sales are ignored.
| Note | Queries that employ a HAVING clause always return a static cursor. |
Multitable Queries
The queries covered so far in this chapter have all involved a single table. However, in the world of relational databases, your data is typically distributed across two or more related tables. Queries that include two or more tables make use of joins or unions. When data in two or more tables is compared, the query is called a join. When data in two or more results sets is combined, the query is called a union. The following sections describe joins and unions.
| Note | Any time you execute a query that contains a join of any type, the result is a static cursor. |
Creating Table Joins in the WHERE Clause
The simplest mechanism for defining a join is to define the relationship between two or more fields in two or more tables in the WHERE clause. For example, consider the following query:
SELECT Count(INVOICE."Invoice No") AS "Count of Invoices", INVOICE."Employee ID", RTRIM(EMPLOYEE."First Name") + ' ' + RTRIM(EMPLOYEE."Last Name") FROM INVOICE, EMPLOYEE WHERE INVOICE."Employee ID" = EMPLOYEE."Employee Number" GROUP BY 2, 3
This query joins records in the EMPLOYEE table to those in the INVOICE table based on the fields that uniquely identify the employee. Those fields are the Employee ID field in the INVOICE table and the Employee Number field in the EMPLOYEE table. By selecting those records where these fields match in the WHERE clause, we effectively produce a join. The following is the result set produced by this query:
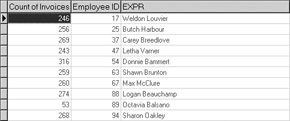
This type of join is called an inner join. With an inner join, the result set only includes records for which the same values appear in both tables for those fields involved in the join. With respect to this query, it means that only employees associated with at least one invoice in the INVOICE table, and whose Employee Number appears in the EMPLOYEE table, will be selected to the result set. Any employee whose number does not appear in the INVOICE table will not appear in the result set, nor will employees whose Employee ID appears in the INVOICE table, but whose Employee ID does not appear in the Employee Number field of the EMPLOYEE table.
| Note | Any time you join data from two or more tables using either the WHERE clause or the JOIN keyword (described next), appropriate indexes can have a dramatic impact on query performance. |
Using JOIN
In addition to using a WHERE clause to produce an inner join, you can join data from two or more tables in records of your result using the JOIN keyword. With JOIN, you can create both inner and outer joins.
You create an inner join by preceding the JOIN keyword by the keyword INNER, followed by a table that you want to JOIN, and then listing the field associations following the ON keyword. For example, the following query creates the same inner join as that shown in the preceding query using a WHERE clause:
SELECT Count(INVOICE."Invoice No") AS "Count of Invoices", INVOICE."Employee ID", RTRIM(EMPLOYEE."First Name") + ' ' + RTRIM(EMPLOYEE."Last Name") FROM INVOICE INNER JOIN EMPLOYEE ON INVOICE."Employee ID" = EMPLOYEE."Employee Number" GROUP BY INVOICE."Employee ID", RTRIM(EMPLOYEE."First Name") + ' ' + RTRIM(EMPLOYEE."Last Name")
Because inner joins defined in the WHERE clause tend to be shorter in length, those queries tend to be used more often than those that employ the INNER JOIN keywords. By comparison, outer joins cannot be accomplished using the WHERE clause. Instead, you use the OUTER JOIN keywords.
When you define an outer join, all records from the left-side table of the ON clause are included in the result set, even if no corresponding records appear in the table listed on the right side of the ON clause. Consider the following query:
SELECT Count(INVOICE."Invoice No") AS "Count of Invoices", EMPLOYEE."Employee Number", RTRIM(EMPLOYEE."First Name") + ' ' + RTRIM(EMPLOYEE."Last Name") FROM EMPLOYEE LEFT OUTER JOIN INVOICE ON INVOICE."Employee ID" = EMPLOYEE."Employee Number" GROUP BY EMPLOYEE."Employee Number", RTRIM(EMPLOYEE."First Name") + ' ' + RTRIM(EMPLOYEE."Last Name")
This query counts the number of invoices found in the INVOICE table for all employees, not just those employees whose employee numbers appear in the INVOICE table. A count of 0 is returned for those employees listed in the EMPLOYEE table for whom no corresponding records appear in the INVOICE table, as seen in the following result set:
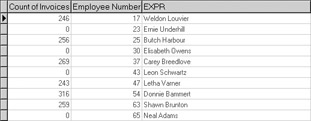
Using UNION
You use UNION to combine records from two result sets with a similar structure (same number of fields and similar data types at the corresponding fields) into one result set. Each result set is produced by a SELECT statement that may be from one or more tables. When using UNION, only distinct records are retrieved to the result set. If you use UNION ALL, duplicate records are not suppressed. Consider the following query:
SELECT "Employee ID", 'Has Sales' AS "Sales Status" FROM INVOICE UNION SELECT "Employee Number", 'No Sales' AS "Sales Status" FROM EMPLOYEE WHERE "Employee Number" NOT IN (SELECT "Employee ID" FROM INVOICE)
This query will return the employee identification number from both the INVOICE and the EMPLOYEE tables. Those employees associated with at least one invoice in the INVOICE table will have the string “Has Sales” associated with their records in the result set, while those without corresponding entries in the INVOICE table will display the string “No Sales.” The following is the result set returned by this query:

| Note | You cannot use MEMO or BLOB fields in queries that use the UNION keyword, except in the case of UNION ALL. |
Full Text Search Queries
Full text search (FTS) was added to ADS in version 7.0. With this capability, you can search string and BLOB (binary large object) fields for specific strings and patterns.
Queries that perform full text searches make use of either the CONTAINS scalar function, the SCORE or SCOREDISTINCT scalar functions, or both.
Using CONTAINS
You use the CONTAINS scalar function in the WHERE clause of your query. CONTAINS is passed two parameters, and evaluates to a Boolean expression. CONTAINS returns True for each record where the search criteria is found in the index or fields being searched, and False otherwise.
The first parameter of CONTAINS is either the name of a field or * (asterisk). If you pass the name of the field in the first parameter, only the named field will be searched. Depending on the size of the table, this search can be significantly improved if the field already has an FTS index. If you pass * in the first parameter, CONTAINS will search all of the available FTS indexes for the table being queried for the search criteria.
The second parameter is a string containing the search criteria. The search criteria can include one or more strings, and can include the AND, OR, NOT, and NEAR operators. For example, the following query selects all records for which the Notes FTS index contains the word “birthday”:
SELECT * FROM CUSTOMER WHERE CONTAINS(Notes, 'birthday')
| Note | These queries assume that you created an FTS index on the s field in the CUSTOMER table, as described in Chapter 3. |
The following query returns all records where any of the FTS indexes (though there is only one FTS index on the CUSTOMER table) contain either the word “birthday” or the word “card”:
SELECT * FROM CUSTOMER WHERE CONTAINS(Notes, 'birthday OR card')
The next example returns all records from the CUSTOMER table where the Notes index contains the words “birthday” and “card,” but only if they are located in close proximity to one another using the NEAR(x) operator where x specifies the number of words. If you do not include (x), the default for NEAR is eight words.
SELECT * FROM CUSTOMER WHERE CONTAINS(Notes, 'birthday NEAR card')
Using SCORE and SCOREDISTINCT
You use the SCORE and SCOREDISTINCT integer functions in the SELECT list, WHERE clause, or ORDER BY clause of a query. These functions return the number of matches to the search criteria located during the search.
There are two syntax options for both SCORE and SCOREDISTINCT functions. The first option accepts the same parameters as does the CONTAINS scalar function. SCORE will return the total number of matches to the values specified in the search criteria, and SCOREDISTINCT returns the number of unique matches.
For example, consider the following query:
SELECT RTRIM("First Name") + ' ' + RTRIM("Last Name") AS "Full Name", SCORE(Notes, 'birthday OR card') AS "Count" FROM CUSTOMER WHERE CONTAINS(Notes, 'birthday OR card') This query will return the customer name as well as the total number of instances of either birthday or card in the Notes field. By comparison, the following query, which uses the SCOREDISTINCT function, will return a count of either 1 or 2. When you use SCOREDISTINCT, multiple instances of either birthday or card will be counted only once.
SELECT RTRIM("First Name") + ' ' + RTRIM("Last Name") AS "Full Name", SCOREDISTINCT(Notes, 'birthday OR card') AS "Count" FROM CUSTOMER WHERE CONTAINS(Notes, 'birthday OR card') Instead of passing the same parameters to SCORE and SCOREDISTINCT as you would to CONTAINS, you can pass a single integer parameter. When you pass an integer, that integer refers to one of the CONTAINS functions in the same query. If you pass 1, SCORE or SCOREDISTINCT will use the parameters of the first CONTAINS function call, while passing 2 means that there are at least two CONTAINS function calls, and SCORE or SCOREDISTINCT should use the arguments of the second instance.
For example, the following query returns the same result set at the preceding one:
SELECT RTRIM("First Name") + ' ' + RTRIM("Last Name") AS "Full Name", SCOREDISTINCT(1) AS "Count" FROM CUSTOMER WHERE CONTAINS(Notes, 'birthday OR card')
|
EAN: 2147483647
Pages: 129