Understanding the Fundamentals of QoS
In order to fully understand QoS, there are a few changes we need to apply to our common mindset regarding network traffic. We need to consider the mechanisms behind our existing traffic forwarding, usually comprising a combination of connectionless and connection-oriented delivery, per-hop router/switch forwarding, and FIFO (first in, first out) queuing. We need to review what we know about networks where no QoS features are added to the basic protocol activity. These networks are called best efforts networks.
Best Efforts Networks
In a best efforts network, as illustrated in Figure 9.5, data is transmitted in the hope (an expectation) that it will be delivered. It's similar to the mail system. You write your letter, address it, and put it in the mailbox. And that's it. You hope (and expect) that it will be delivered, but it's out of your control. If something goes wrong with the system, your mail is undelivered. And you may not even know that it failed to get through!
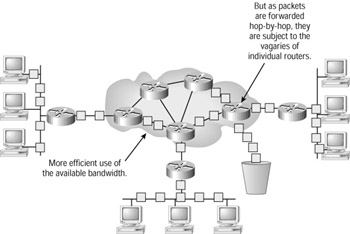
Figure 9.5: Best efforts packets
Of course, if the mail system were truly unreliable, you would complain loudly, and eventually stop using it, so it can't be all that bad. But because there is no reliability built in, we refer to it as unreliable.
Under these circumstances, there are two choices open to us. We can either live with the unreliability, or try to do something about it.
Connection-Oriented Transport
One thing we could do is ask for a receipt to be signed at the far end so that we know it got through. This would make our system more reliable, but obviously the service would not be free, because there is greater overhead and therefore greater cost. In IP networks, we use TCP (Transport Control Protocol) to handle that receipting process for us, and we call those receipts acknowledgments. And it isn't free, because we have to wait for a packet to be acknowledged before we can send the next one, and that slows down the data throughput.
So in order to work properly, both the sequence number and the acknowledgment numbers must be synchronized at the start of the data transfer. In fact, other additional parameters also need to be set at this time, and so TCP has a complex process to initiate the data transfer, called the connection sequence.
In a way, this puts us on the road to QoS-based networks, because we have at least guaranteed that our data will be delivered. Now we have to deal with all of the other issues surrounding how it will be delivered.
Connectionless Transport
Sometimes the need for reliable data transfer is overridden by another, more pressing requirement. If the protocol in question uses broadcasts to deliver its data, then we cannot reasonably expect acknowledgments. It's bad enough that every station on the segment is disturbed by the original broadcast, without compounding the felony! Protocols such as RIP (the ubiquitous routing protocol) operate like this, resending their data at regular intervals to ensure that data gets through.
Another family of protocols that remain connectionless are the multicasts. Multicast traffic (as we know from Chapter 8, 'Understanding and Configuring Multicast Operation') is delivered to stations that have joined a particular multicast group. Once again, it would be unreasonable to expect acknowledgments from such a potentially large receiver group, but there are additional factors.
Multicast streams often contain either time-sensitive or streaming information. In either case, the delays associated with acknowledgments would be unacceptable, interfering with the flow of the data.
Streaming Transport
There is one other option. Multicast traffic may not be acknowledged, but that is no reason for us to abandon all efforts to deliver the data in the sequence in which it was transmitted.
Real Time Protocol (RTP) is one option to assist us here. RTP runs over UDP and provides both sequence information and a timestamp for each datagram. Although this in itself doesn't provide any service guarantees, it does mean that the receiver can make adjustments by changing the order of packet arrival to restore simple out-of-sequence deliveries, and packets arriving too late for insertion into the stream decoders can be ignored.
Common Problems in Best Efforts Networks
Best efforts networks attempt to deliver packets, but are characterized by a variety of conditions that interfere in some way with forwarding data.
Simple Delay
Simple delay causes packets to arrive later than might be expected. There are several contributing factors to simple delay:
Laws of Physics Delay Laws of physics delay is caused by the fact that data cannot be propagated through either copper or fiber instantaneously, or even at anything like the speed of light. In fact, about 60 percent of light speed in copper, and not much faster in fiber, is the norm. The good news is that this delay is standard.
| Note | Data traveling across copper for a distance of 100 meters takes about 0.5 microseconds to arrive. This might seem very small, almost insignificant. But for data traveling at 100Mbits/second, this is a delay of about 50 bits! |
Serialization Delay Serialization delay is caused by store-and-forward devices such as switches and routers having to read the frame or packet into the buffers before any decision- making process can be implemented. This is obviously unpredictable, as varying frame/packet sizes will result in different delays.
Processing Delay Processing delay is caused by the router or switch having to make a forwarding decision. This is again variable and unpredictable, because it may depend upon the processing overhead on that device at the moment of search, the internal buffer architecture and load, internal bus load, and the searching algorithm in use. There may be some statistically measurable average, but that's no good for individual packets.
Output Buffer Priorities Output buffer priorities are the final stage of the delay. Should a buffer become full, then the mechanism for discarding may be simple tail-drop, or something more complex such as Random Early Discard. And if the queuing method is FIFO, then that favors larger frames/packets, whereas if we implement sophisticated queuing, we must always remember that putting one data stream at the front of the queue is bound to result in another stream being at the back.
Jitter
Jitter is what happens when packets arrive either earlier or later than expected, outside established parameters for simple delay. The effect is to interfere with the smooth playback of certain types of streaming traffic (voice, video, and so on), because the playback buffers are unable to cope with the irregular arrival of successive packets. Jitter is caused by variations in delay, such as the following:
Serialization Delay Serialization delay can cause jitter, with subsequent packets being of different sizes. One technique that might be used to standardize this delay would be to make all frames the same size, irrespective of their data content. This is the method used by Frame Relay using the FRF.11 (for voice) recommendation, and by ATM. This solution is good for voice but bad for data, because of the overhead created by increasing the number of frames per packet.
Queue Disposition Queue disposition can affect delay, because while packets at the front of the queue may have constancy of delay, packets further back are behind an unknown number of frames/packets at the front, giving rise to variability. Cisco provides a number of different queuing options, allowing the most appropriate to be selected on a case-by-case basis.
Per-Hop Routing Per-hop routing behavior can affect delay variably, because subsequent packets may travel to the same destination via different paths due to routing changes.
Packet Loss
Packet loss may seem to be the most important issue, but that is often not the case. If packet loss occurs in connection-oriented services, then the lost packet will be requested and retransmitted. This may be annoying if it slows down the data transfer too much, but connection-oriented applications are built to manage this problem.
In a connectionless network, once lost, the data is gone forever. If the loss exceeds certain parameters (different for each application), then the application will be deemed unusable and terminated either by the user (quality too poor) or by the application itself. In either case, the user and application are exposed to the poor quality with the resulting dissatisfaction regarding the network. Packet loss can occur in a number of places, with each location introducing loss in a different way:
Line Loss Line loss is usually caused by data corruption on unacknowledged links. Corrupted packets may fail a checksum and are discarded, but are not scheduled for retransmission. In a well-designed Ethernet network, this should be a rare occurrence.
Buffer Overflows Buffer overflows occur when network devices are too busy internally, or when the output network is congested. The key to managing buffer overflows lies in early detection of the problem and careful application throttling.
Discard Eligible Discard eligible packets are flagged to be deliberately dropped when congestion occurs on Frame Relay and ATM networks. There is no exactly comparable process with Ethernet LANs, but if we establish traffic classes in order to create priorities, then it follows that those frames in the lowest priority traffic streams run the risk of being dropped more frequently as network congestion occurs.
EAN: 2147483647
Pages: 174