Chapter 5: PHP and XPath
Extensible Markup Language (XML) Path (XPath) language is a query language that you can use to retrieve selected information from an XML document. It also provides functions to manipulate strings, numbers , booleans, and nodeset values in an XML document. Using XPath, you can create XPath expressions that specify the path of an XML element to be retrieved from an XML document.
Hypertext Preprocessor (PHP) consists of XPath classes that you can use to retrieve XML elements matching specific criteria. You can use XPath expressions with the Document Object Model (DOM) and Simple Application Programming Interface (API) for XML (SAX) parsers implemented in PHP language to determine the location of the XML elements in an XML document. In addition, you can process XML documents using XPath expressions in Extensible Stylesheet Language for Transformation (XSLT) templates.
This chapter describes XPath and how to use XPath expressions in an XML document. It also describes how to use location paths to retrieve specific elements from an XML document. In addition, it explains the method to access XML elements using DOM and SAX parsers and XSLT templates implemented in PHP.
Introducing XPath
An XPath expression specifies the part of an XML document that you need to select and retrieve.
XPath selects a portion of data from an XML document by navigating the hierarchical structure of that document. This query language follows a path to point to a specific node in the XML document hierarchy. XPath searches an XML document from the starting point of the document called the context node, progresses in a specific direction, and arrives at the required point by navigating through the path described by a location path. Location steps in the location path determine the path to navigate an XML document and locate a particular XML element.
Location steps consist of three parts : an axis, node test, and predicates. The axis informs the XPath processor about the process of navigating around an XML document. The node test determines the type of node selected by the location step, along with its name . The predicate filters the set of nodes selected by the axis and the node test. If there are more than one location step in a location path, each location step uses the node in the previous nodeset as its starting point.
Creating Nodes Using XPath
An XML document consists of a succession of elements, each with a start and end tag. Various elements are nested within each other in the document. XPath uses a data model to represent all elements within an XML document as a hierarchy of nodes.
For example, you want to represent the data model in XPath for the customer.xml XML document.
Listing 5-1 shows the contents of customer.xml:
| |
<?xml version="1.0"?> <customer> <companyname>IBG, Inc.</companyname> <item>Computer</item> <itemcode>c001</itemcode> <item_quantity>20</item_quantity> <price>20000</price> </customer>
| |
The above listing shows the content of an XML document, customer.xml. The document contains information about an item that a company wants to purchase. This information includes the company name, item name, item code, item quantity, and the price.
Figure 5-1 shows the corresponding data model in XPath for the customer.xml document:
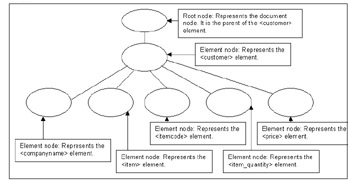
Figure 5-1: The XPath Data Model for the customer.xml Document
This model shows a root node, which is the parent of the element root. The element root is represented by the element node, which represents the <customer> element. The element node that represents the <customer> element contains five child element nodes that represent the <companyname>, <item>, <itemcode>, <item_quantity>, and <price> elements.
In XPath, a node refers to a specific part, such as an element or attribute, of an XML document. Each XML document functions as a tree and consists of a root node, which is the parent of the element node. XPath includes seven types of nodes. Of these seven nodes, only some nodes consist of an expanded name. The expanded name consists of two parts, local part and namespace Uniform Resource Identifier (URI). Local part is a string and namespace URI is either a string or a NULL value.
The namespace URI is a URI reference. An XML document that does not contain a namespace declaration contains a NULL value for the namespace URI. In these cases, the expanded name of an element is same as the element name.
The seven types of nodes available in XPath are:
-
Root: Represents the root of the XPath tree. There is only one root node for each XPath tree structure. It does not have an expanded name.
-
Element: Represents each element in the XML source document. It contains an expanded name that results from expanding the Qualified Name (QName) in the element tag. The QName is an element name with a prefix added to it. If the QName does not contain a prefix and default namespace, the value of the namespace URI for the expanded name of the element is NULL.
-
Attribute: Represents the attributes of an element in the XML source document. It can be empty. The element node is the parent of the attribute node. However, an attribute node is not a child of the parent node.
-
Namespace: Associated with an element node. A namespace node exists for each attribute on the element whose name starts with the prefix, xmlns:. A namespace node exists for each attribute on an ancestor element with names starting from xmlns:.
-
Processing instruction: Represents the processing instructions in the XML source document. It consists of an expanded name with the local part representing the application to which the processing instruction applies.
-
Comment: Represents the comments in the XML source document. It does not have an expanded name.
-
Text: Represents the character data in the XML document. Text nodes are not produced for character values that exist inside comments, attributes, and processing instructions. It does not have an expanded name.
| Note | If a location path starts with child, the resultant nodeset contains neither attribute nor namespace nodes. |
Every node other than the root node in the data model consists of one parent. For example, the XML document, customer.xml, consists of all nodes included in it.
Listing 5-2 shows the customer.xml document that contains different types of nodes:
| |
<?xml version="1.0"?> <customer><!Denotes the element node--> <companyname company="IBG, Inc."><!company is the child attribute node.--> The name of the company is IBG, Inc.!<!The string denotes the child text node.--> <customer xmlns=http://www.xmml.com/><!Denotes the namespace node--> </companyname> <item>Computer</item> <?customer SELECT * FROM item?><!Denotes the processing instruction node.--> </customer>
| |
The above listing shows the content of the customer.xml document with a root node, which is the parent of the comment node, <companyname> element node, <item> element node, and the processing instruction node. The root node is not visible in the document. The <companyname> element node consists of a child attribute node, which is the company with the value, "IBG, Inc.". The <companyname> element node also contains a child text node with the value, "The name of the company is IBG, Inc.". The comment node starts with <! ”and ends with -->.
| Note | Two expanded names are equal if they have the same local part, regardless of the value of the namespace URI. |
Implementing the XPath Syntax
XPath does not use the XML-based syntax. You cannot include XPath expressions in the URIs or attributes of XML elements. The XPath syntax is the same as file system addressing and enables querying the data in an XML document. XPath uses a pattern expression to:
-
Identify the nodes within an XML document.
-
Select unknown elements.
-
Select the branches of an element.
-
Select several paths along the axis.
-
Select attributes.
An XPath pattern expression describes a path that contains a list of child element names separated by a slash. The pattern selects those elements from an XML document that matches the path.
Listing 5-3 shows a sample XML document:
| |
<?xml version="1.0"?> <customer> <item itemcode="01"> <itemprice price="15.00"></itemprice> <quantity value="20"></quantity> </item> <item itemcode="02"> <itemprice price="30.00"></itemprice> <quantity value="10"></quantity> </item> </customer>
| |
The above XML document contains information about items purchased by a customer. The document contains item information, such as the item code, item price, and the quantity.
The following pattern expression selects all <itemprice> element nodes of all <item> element nodes of the <customer> element node:
/customer/item/itemprice
In the above pattern expression, <itemprice> element is the child element node of the <item> element node, which is the child element of the <customer> element.
| Note | If a path expression starts with a double slash (//), the resultant nodeset contains all elements described by the path expression. |
For example, the path expression //customer selects all customer elements in the customer.xml document.
XPath uses wild card characters , such as *, to select unknown elements in an XML document. The * wild card character selects all elements defined by the preceding path. For example, the expression to select all child element nodes of all <item> element nodes of the <customer> element node is:
/customer/item/*
Similarly, the expression to select all <itemprice> elements that are grandchild elements of the <customer> element is:
/customer/*/itemprice
The pattern expression to select all elements that have two ancestors is:
/*/*/itemprice
The pattern expression to select all elements in an XML document is:
//*
You can specify branches on a location step using additional patterns. As a result, these additional patterns further describe an element. For example, the expression that selects the first node representing the <item> element child of the <customer> element node is:
/customer/item[1]
In the above syntax, the numeric value in the square brackets represents the position of the element in the selected element set. The expression to select the last <item> element belonging to the <customer> element is:
/customer/item[last()]
The expression that selects all <itemprice> element nodes of the <customer> element node with the <price> attribute value 15.00 is:
/customer/itemprice[price=15.00]
You can select several paths in a document using the pipe () operator in XPath. For example, the expression to select all <quantity> and <itemprice> elements of the <item> element of the <customer> element is:
/customer/item/quantity/customer/item/itemprice
Similarly, the expression to select all <quantity> and <itemprice> elements in the XML document is:
//quantity//itemprice
Using XPath, you can also select attributes in an XML document. The at (@) symbol prefixes all attributes in an XPath expression. The @ symbol signifies that selected elements represent the attributes of an element. For example, the expression that selects all attributes named as price is:
//@price
The expression that selects all <item> elements with an attribute named itemcode is:
//item[@itemcode]
XPath syntax can be either abbreviated or unabbreviated. The unabbreviated syntax for a location step consists of an axis name and node test separated by a double colon . The syntax may or may not include predicates in square brackets. The child axis includes the child nodes of the context node. This axis is the default axis, and you can eliminate it from the location step. For example, you can write the abbreviated form of an XPath expression as:
/customer
The above syntax is the same as the following unabbreviated XPath expression:
/child::customer
The descendant axis consists of nodes that are descendants of the context node. The descendants can be a child node or a grandchild node. For example, an XPath expression that selects descendant nodes is:
/descendant::*
In the above syntax, XPath selects all descendant nodes of the root element node.
| Note | The descendent axis cannot include the attribute and namespace nodes. |