7.4 Discriminant Unions
7.4 Discriminant Unions
A discriminant union (or just union ) is very similar to a record. Like records, unions have fields and you access those fields using dot notation. In fact, in many languages, about the only syntactical difference between records and unions is the use of the keyword union rather than record . Semantically, however, there is a big difference between a record and a union. In a record, each field has its own offset from the base address of the record, and the fields do not overlap. In a union, however, all fields have the same offset, zero, and all the fields of the union overlap. As a result, the size of a record is the sum of the sizes of all the fields (plus, possibly, some padding bytes), whereas a union's size is the size of its largest field (plus, possibly, some padding bytes at the end).
Because the fields of a union overlap, you might think that a union has little use in a real-world program. After all, if the fields all overlap, then changing the value of one field changes the values of all the other fields as well. This generally means that the use of a union's field is mutually exclusive - that is, you can only use one field at any given time. This observation is generally correct, but although this means that unions aren't as generally applicable as records, they still have many uses.
7.4.1 Unions in C/C++
Here's an example of a union declaration in C/C++:
typedef union { unsigned int i; float r; unsigned char c[4]; } unionType; Assuming the C/C++ compiler in use allocates four bytes for unsigned integers, the size of a unionType object will be four bytes (because all three fields are 4-byte objects).
7.4.2 Unions in Pascal/Delphi/Kylix
Pascal/Delphi/Kylix use case variant records to create a discriminant union. The syntax for a case variant record is the following:
type typeName = record <<non-variant/union record fields go here>> case tag of const1 :( field_declaration ); const2 :( field_declaration ); . . . constn :( field_declaration ) (* no semicolon follows the last field *) end;
In this example, tag is either a type identifier (such as Boolean, char, or some user -defined type) or it can be a field declaration of the form identifier:type . If the tag item takes this latter form, then identifier becomes another field of the record (and not a member of the variant section - those declarations following the case ) and has the specified type. When using this second form, the Pascal compiler could generate code that raises an exception whenever the application attempts to access any of the variant fields except the one specified by the value of the tag field. In practice, though, almost no Pascal compilers do this. Still, keep in mind that the Pascal language standard suggests that compilers should do this, so some compilers out there might actually do this check.
Here's an example of two different case variant record declarations in Pascal:
type noTagRecord= record someField: integer; case boolean of true:( i:integer ); false:( b:array[0..3] of char) end; (* record *) hasTagRecord= record case which:(0..2) of 0:( i:integer ); 1:( r:real ); 2:( c:array[0..3] of char ) end; (* record *)
As you can see in the hasTagRecord union, a Pascal case-variant record does not require any normal record fields. This is true even if you do not have a tag field.
7.4.3 Unions in HLA
HLA supports unions as well. Here's a typical union declaration in HLA:
type unionType: union i: int32; r: real32; c: char[4]; endunion;
7.4.4 Memory Storage of Unions
The big difference between a union and a record is the fact that records allocate storage for each field at different offsets, whereas unions overlay each of the fields at the same offset in memory. For example, consider the following HLA record and union declarations:
type numericRec: record i: int32; u: uns32; r: real64; endrecord; numericUnion: union i: int32; u: uns32; r: real64; endunion;
If you declare a variable, n , of type numericRec , you access the fields as n.i , n.u, and n.r , exactly as though you had declared the n variable to be type numericUnion . However, the size of a numericRec object is 16 bytes because the record contains two double-word fields and a quad-word (real64) field. The size of a numericUnion variable, however, is eight bytes. Figure 7-9 shows the memory arrangement of the i, u, and r fields in both the record and union.
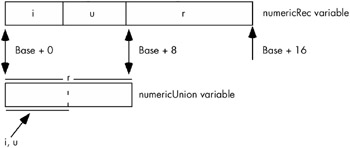
Figure 7-9: Layout of a union versus a record variable
7.4.5 Other Uses of Unions
In addition to conserving memory, programmers often use unions to create aliases in their code. As you may recall, an alias is a second name for some memory object. Although aliases are often a source of confusion in a program, and should be used sparingly, using an alias can sometimes be convenient . For example, in some section of your program you might need to constantly use type coercion to refer to a particular object. One way to avoid this is to use a union variable with each field representing one of the different types you want to use for the object. As an example, consider the following HLA code fragment:
type CharOrUns: union c:char; u:uns32; endunion; static v:CharOrUns;
With a declaration like this one, you can manipulate an uns32 object by accessing v.u . If, at some point, you need to treat the LO byte of this uns32 variable as a character, you can do so by simply accessing the v.c variable, as follows:
mov( eax, v.u ); stdout.put( "v, as a character, is '", v.c, "'" nl );
Another common practice is to use unions to disassemble a larger object into its constituent bytes. Consider the following C/C++ code fragment:
typedef union { unsigned int u; unsigned char bytes[4]; } asBytes; asBytes composite; . . . composite.u = 1234576890; printf ( "HO byte of composite.u is %u, LO byte is %u\n", composite.u[3], composite.u[0] ); Although composing and decomposing data types using unions is a useful trick every now and then, be aware that this code is not portable. Remember, the HO and LO bytes of a multibyte object appear at different addresses on big endian versus little endian machines. This code fragment works fine on little endian machines, but fails to display the right bytes on big endian CPUs. Anytime you use unions to decompose larger objects, you should be aware that the code might not be portable across different machines. Still, disassembling larger values into the corresponding bytes, or assembling a larger value from bytes, is usually much more efficient than using shift lefts, shift rights, and AND operations. Therefore, you'll see this trick used quite a bit.
EAN: 2147483647
Pages: 144
- Using SQL Data Definition Language (DDL) to Create Data Tables and Other Database Objects
- Working with Queries, Expressions, and Aggregate Functions
- Working with SQL JOIN Statements and Other Multiple-table Queries
- Monitoring and Enhancing MS-SQL Server Performance
- Writing Advanced Queries and Subqueries