5.1 Character Data
5.1 Character Data
Most computer systems use a 1- or 2-byte binary sequence to encode the various characters . Windows and Linux certainly fall into this category, using the ASCII or Unicode character sets, whose members can all be represented using 1- or 2-byte binary sequences. The EBCDIC character set, in use on IBM mainframes and minicomputers, is another example of a single-byte character code.
I will discuss all three of these character sets, and their internal representations, in this chapter. I will also describe how to create your own custom character sets later in this chapter.
5.1.1 The ASCII Character Set
The ASCII (American Standard Code for Information Interchange) character set maps 128 characters to the unsigned integer values 0..127 ($0..$7F). Although the exact mapping of characters to numeric values is arbitrary and unimportant, a standardized mapping allows you to communicate between programs and peripheral devices. The standard ASCII codes are useful because nearly everyone uses them. Therefore, if you use the ASCII code 65 to represent the character A , then you know that some peripheral device (such as a printer) will correctly interpret this value as the character A .
Because the ASCII character set provides only 128 different characters, an interesting question arises: 'What do we do with the additional 128 values ($80..$FF) that we can represent with a byte?' One answer is to ignore those extra values. That will be the primary approach of this book. Another possibility is to extend the ASCII character set by an additional 128 characters. Of course, unless you can get everyone to agree upon one particular extension of the character set, [1] the whole purpose of having a standardized character set will be defeated. And getting everyone to agree is a difficult task.
Despite some major shortcomings, ASCII data is the standard for data interchange across computer systems and programs. Most programs can accept ASCII data, and most programs can produce ASCII data. Because you will probably be dealing with ASCII characters in your programs, it would be wise to study the layout of the character set and memorize a few key ASCII codes (such as those for , A , a , and so on). Table A-1 in Appendix A lists all the characters in the standard ASCII character set.
The ASCII character set is divided into four groups of 32 characters. The first 32 characters, ASCII codes $0 through $1F (0 through 31), form a special set of nonprinting characters called the control characters . We call them control characters because they perform various printer and display control operations rather than displaying actual symbols. Examples of control characters include carriage return , which positions the cursor at the beginning of the current line of characters; [2] line feed, which moves the cursor down one line on the output device; and backspace , which moves the cursor back one position to the left. Unfortunately, different control characters perform different operations on different output devices. There is very little standardization among output devices. To find out exactly how a particular control character affects a particular device, you will need to consult its manual.
The second group of 32 ASCII character codes comprises various punctuation symbols, special characters, and the numeric digits. The most notable characters in this group include the space character (ASCII code $20) and the numeric digits (ASCII codes $30..$39).
The third group of 32 ASCII characters contains the uppercase alphabetic characters. The ASCII codes for the characters A through Z lie in the range $41..$5A. Because there are only 26 different alphabetic characters, the remaining six codes hold various special symbols.
The fourth and final group of 32 ASCII character codes represents the lowercase alphabetic symbols, five additional special symbols, and another control character (delete). Note that the lowercase character symbols use the ASCII codes $61..$7A. If you convert the codes for the upper- and lowercase characters to binary, you will notice that the uppercase symbols differ from their lowercase equivalents in exactly one bit position. For example, consider the character codes for E and e appearing in Figure 5-1.
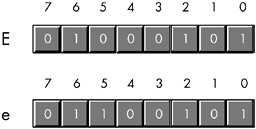
Figure 5-1: ASCII codes for E and e
The only place these two codes differ is in bit five. Uppercase alphabetic characters always contain a zero in bit five; lowercase alphabetic characters always contain a one in bit five. You can use this fact to quickly convert an alphabetic character between upper- and lowercase by simply inverting bit five. If you have an uppercase character, you can force it to lowercase by setting bit five to one. If you have a lowercase character and you wish to force it to uppercase, you can do so by setting bit five to zero.
Bits five and six determine the character's group (see Table 5-1). Therefore, you can convert any upper- or lowercase (or special) character to its corresponding control character by setting bits five and six to zero.
| Bit 6 | Bit 5 | Group |
|---|---|---|
|
|
| Control characters |
|
| 1 | Digits and punctuation |
| 1 |
| Uppercase and special |
| 1 | 1 | Lowercase and special |
Consider, for a moment, the ASCII codes of the numeric digit characters in Table 5-2. The decimal representations of these ASCII codes are not very enlightening. However, the hexadecimal representation of these ASCII codes reveals something very important - the LO nibble of the ASCII code is the binary equivalent of the represented number. By stripping away (setting to zero) the HO nibble of the ASCII code, you obtain the binary representation of that digit. Conversely, you can convert a binary value in the range 0..9 to its ASCII character representation by simply setting the HO nibble to %0011, or the decimal value 3. Note that you can use the logical AND operation to force the HO bits to zero; likewise, you can use the logical OR operation to force the HO bits to %0011 (decimal 3). For more information on string-to-numeric conversions, see Chapter 2.
| Character | Decimal | Hexadecimal |
|---|---|---|
|
| 48 | $30 |
| 1 | 49 | $31 |
| 2 | 50 | $32 |
| 3 | 51 | $33 |
| 4 | 52 | $34 |
| 5 | 53 | $35 |
| 6 | 54 | $36 |
| 7 | 55 | $37 |
| 8 | 56 | $38 |
| 9 | 57 | $39 |
Despite the fact that it is a 'standard,' simply encoding your data using ASCII characters does not guarantee compatibility across systems. While it's true that an A on one machine is most likely an A on another system, there is very little standardization across machines with respect to the use of the control characters. Indeed, of the 32 control codes in the first group of ASCII codes, plus the delete code in the last group, there are only 4 control codes commonly supported by most devices and applications - backspace (BS), tab, carriage return (CR), and line feed (LF). Worse still, different machines often use these 'supported' control codes in different ways. End-of-line is a particularly troublesome example. Windows, MS-DOS, CP/M, and other systems mark end-of-line by the two-character sequence CR/LF. The Apple Macintosh, and many other systems, mark end-of-line by a single CR character. Linux, BeOS, and other Unix systems mark end-of-line with a single LF character.
Attempting to exchange simple text files between such different systems can be an experience in frustration. Even if you use standard ASCII characters in all your files on these systems, you will still need to convert the data when exchanging files between them. Fortunately, such conversions are rather simple, and many text editors automatically handle files with different line endings (there are also many available freeware utilities that will do this conversion for you). Even if you have to do this in your own software, all that the conversion involves is copying all characters except the end-of-line sequence from one file to another, and then emitting the new end-of-line sequence whenever you encounter an old end-of-line sequence in the input file.
5.1.2 The EBCDIC Character Set
Although the ASCII character set is, unquestionably, the most popular character representation, it is certainly not the only format available. For example, IBM uses the EBCDIC code on many of its mainframe and minicomputer lines. Because EBCDIC appears mainly on IBM's big iron and you'll rarely encounter it on personal computer systems, we'll only consider it briefly in this book.
EBCDIC (pronounced EB-suh-dic) is an acronym that stands for Extended Binary Coded Decimal Interchange Code . If you're wondering if there was an unextended version of this character code, the answer is yes. Earlier IBM systems and keypunch machines used a character set known as BCDIC (Binary Coded Decimal Interchange Code) . This was a character set based on punched cards and decimal representation (for IBM's older decimal machines).
The first thing to note about EBCDIC is that it is not a single character set; rather, it is a family of character sets. While the EBCDIC character sets have a common core (for example, the encodings for the alphabetic characters are usually the same), different versions of EBCDIC (known as code pages ) have different encodings for punctuation and special characters. Because there are a limited number of encodings available in a single byte, different code pages reuse some of the character encodings for their own special set of characters. So, if you're given a file that contains EBCDIC characters and someone asks you to translate it to ASCII, you'll quickly discover that this is not a trivial task.
Before you ever look at the EBCDIC character set, you should first realize that the forerunner of EBCDIC (BCDIC) was in existence long before modern digital computers. BCDIC was born on old-fashioned IBM key punches and tabulator machines. EBCDIC was simply an extension of that encoding to provide an extended character set for IBM's computers. However, EBCDIC inherited several peculiarities from BCDIC that seem strange in the context of modern computers. For example, the encodings of the alphabetic characters are not contiguous. This is probably a direct result of the fact that the original character encodings really did use a decimal (BCD) encoding. Originally (in BCD/decimal), the alphabetic characters probably did have a sequential encoding. However, when IBM expanded the character set, they used some of the binary combinations that are not present in the BCD format (values like %1010..%1111). Such binary values appear between two otherwise sequential BCD values, which explains why certain character sequences (such as the alphabetic characters) do not use sequential binary codes in the EBCDIC encoding.
Unfortunately, because of the weirdness of the EBCDIC character set, many common algorithms that work well on ASCII characters simply don't work with EBCDIC. This chapter will not consider EBCDIC beyond a token mention here or there. However, keep in mind that EBCDIC functional equivalents exist for most ASCII characters. Check out the IBM literature for more details.
5.1.3 Double-Byte Character Sets
Because of the encoding limitations of an 8-bit byte (which has a maximum of 256 characters) and the need to represent more than 256 characters, some computer systems use special codes to indicate that a particular character consumes two bytes rather than a single byte. Such double-byte character sets (DBCSs) do not encode every character using 16 bits - instead, they use a single byte for most character encodings and use two-byte codes only for certain characters.
A typical double-byte character set utilizes the standard ASCII character set along with several additional characters in the range $80..$FF. Certain values in this range are extension codes that tell the software that a second byte immediately follows . Each extension byte allows the DBCS to support another 256 different character codes. With three extension values, for example, the DBCS can support up to 1,021 different characters. You get 256 characters with each of the extension bytes, and you get 253 (256 - 3) characters in the standard single-byte set (minus three because the three extension byte values each consume one of the 256 combinations, and they don't count as characters).
Back in the days when terminals and computers used memory-mapped character displays, double-byte character sets weren't very practical. Hardware character generators really want each character to be the same size , and they want to process a limited number of characters. However, as bitmapped displays with software character generators became prevalent (Windows, Macintosh, and Unix/XWindows machines), it became possible to process DBCSs.
Although DBCSs can compactly represent a large number of characters, they demand more computing resources in order to process text in a DBCS format. For example, if you have a zero- terminated string containing DBCS characters (typical in the C/C++ languages), then determining the number of characters in the string can be considerable work. The problem is that some characters in the string consume two bytes while most others consume only one byte. A string length function has to scan byte-by-byte through each character of the string to locate any extension values that indicate that a single character consumes two bytes. This extra comparison more than doubles the time a high-performance string length function takes to execute. Worse still, many common algorithms that people use to manipulate string data fail when they apply them to DBCSs. For example, a common C/C++ trick to step through characters in a string is to either increment or decrement a pointer to the string using expressions like ++ptrChar or --ptrChar . Unfortunately, these tricks don't work with DBCSs. While someone using a DBCS probably has a set of standard C library routines available that work properly on DBCSs, it's also quite likely that other useful character functions they've written (or that others have written) don't work properly with the extended characters in a DBCS. For this and other reasons, you're far better off using the Unicode character set if you need a standardized character set that supports more than 256 characters. For all the details, keep reading.
5.1.4 The Unicode Character Set
A while back, engineers at Apple Computer and Xerox realized that their new computer systems with bitmapped displays and user -selectable fonts could display far more than 256 different characters at one time. Although DBCSs were a possibility, those engineers quickly discovered the compatibility problems associated with double-byte character sets and sought a different route. The solution they came up with was the Unicode character set. Unicode has since become an international standard adopted and supported by nearly every major computer manufacturer and operating system provider (Mac OS, Windows, Linux, Unix, and many other operating systems support Unicode).
Unicode uses a 16-bit word to represent each character. Therefore, Unicode supports up to 65,536 different character codes. This is obviously a huge advance over the 256 possible codes we can represent with an 8-bit byte. Furthermore, Unicode is upward compatible from ASCII; if the HO 9 bits [3] of a Unicode character's binary representation contain zero, then the LO 7 bits use the standard ASCII code. If the HO 9 bits contain some nonzero value, then the 16 bits form an extended character code (extended from ASCII, that is). If you're wondering why so many different character codes are necessary, simply note that certain Asian character sets contain 4,096 characters (at least, in their Unicode character subset). The Unicode character set even provides a set of codes you can use to create an application-defined character set. At the time of this writing, approximately half of the 65,536 possible character codes have been defined; the remaining character encodings are reserved for future expansion.
Today, many operating systems and language libraries provide excellent support for Unicode. Microsoft Windows, for example, uses Unicode internally. [4] So operating system calls will actually run faster if you pass them Unicode strings rather than ASCII strings. (When you pass an ASCII string to a modern version of Windows, the OS first converts the string from ASCII to Unicode and then proceeds with the OS API function.) Likewise, whenever Windows returns a string to an application, that string is in Unicode form; if the application needs it in ASCII form, then Windows must convert the string from Unicode to ASCII before returning.
There are two big disadvantages to Unicode, however. First, Unicode character data requires twice as much memory to represent as ASCII or other single-byte encodings do. Although machines have far more memory today (both in RAM and on disk where text files usually reside), doubling the size of text files, databases, and in-memory strings (such as those for a text editor or word processor) can have a significant impact on the system. Worse, because strings are now twice as long, it takes almost twice as many instructions to process a Unicode string as it does to process a string encoded with single-byte characters. This means that string functions may run at half the speed of those functions that process byte- sized character data. [5] The second disadvantage to Unicode is that most of the world's data files out there are in ASCII or EBCDIC form, so if you use Unicode within an application, you wind up spending considerable time converting between Unicode and those other character sets.
Although Unicode is a widely accepted standard, it still is not seeing widespread use (though it is becoming more popular every day). Quite soon, Unicode will hit 'critical mass' and really take off. However, that point is still in the future, so most of the examples in this text will continue to use ASCII characters. Still, at some point in the not-too- distant future, it wouldn't be unreasonable to emphasize Unicode rather than ASCII in a book like this.
[1] Back before Windows became popular, IBM supported an extended 256-element character set on its text displays. Though this character set is 'standard' even on modern PCs, few applications or peripheral devices continue to use the extended characters.
[2] Historically, carriage return refers to the paper carriage used on typewriters. A carriage return consisted of physically moving the carriage all the way to the right so that the next character typed would appear at the left-hand side of the paper.
[3] ASCII is a 7-bit code. If the HO 9 bits of a 16-bit Unicode value are all zero, the remaining 7 bits are an ASCII encoding for a character.
[4] The Windows CE variant only supports Unicode. You don't even have the option of passing ASCII strings to a Win CE function.
[5] Some might argue that it shouldn't take any longer to process a Unicode string using instructions that process words versus processing byte strings using machine instructions that manipulate bytes. However, high-performance string functions tend to process double words (or more) at one time. Such string functions can process half as many Unicode characters at one time, so they'll require twice as many machine instructions to do the same amount of work.
EAN: 2147483647
Pages: 144