5.2 Synchronizing Access to Data
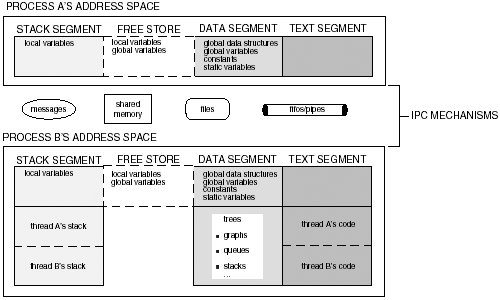
| There is a difference between data shared between processes and data shared between threads. Threads share the same address space. Processes have separate address spaces. If there are two processes, A and B, then data declared in process A is not available to process B and vice versa. Therefore, one method used by processes to share data is to create a block of memory that is then mapped to the address space of the processes that are to share the memory. Another approach is to create a block of memory that exists outside the address space of both processes. These are types of IPC (interprocess communication) that include: pipes, files, and message passing. It is the block of memory shared between threads within the same address space and the block of memory shared between processes outside both address spaces that requires data synchronization. Figure 5-3 contrasts memory shared between threads and processes. Figure 5-3. The memory shared between threads and processes. Data synchronization is needed in order to control race conditions and allow concurrent threads or processes to safely access a block of memory. Data synchronization controls when a block of memory can be read or modified. Concurrent access to shared memory, global variables , and files must be synchronized in a multithreaded environment. Data synchronization is needed at the location in a task's code when it attempts to access the block of memory, global variable, or file shared with other concurrently executing processes or threads. This block of code is called the critical section . The critical section can be any block of code that changes the file pointer's position, writes to the file, closes the file, and reads or writes global variables or data structures. Classifying the tasks as read or write tasks is one step in managing concurrent access to the shared memory. 5.2.1 PRAM ModelThe PRAM (Parallel Random-Access Machine) is a simplified theoretical model where there are N processors, labeled as P 1 , P 2 , P 3 , ... P n , share one global memory. All the processors have simultaneous read and write access to shared global memory. Each of these theoretical processors can access the global shared memory in one uninterruptible unit of time. The PRAM model has concurrent read and write algorithms and exclusive read and write algorithms. Concurrent read algorithms are allowed to read the same piece of memory simultaneously with no data corruption. Concurrent write algorithms allow multiple processors to write to the shared memory. Exclusive read algorithms are used to ensure that no two processors ever read the same memory location at the same time. Exclusive write ensures that no two processors write to the same memory at the same time. The PRAM model can be used to characterize concurrent access to shared memory by multiple tasks. 5.2.1.1 Concurrent and Exclusive Memory AccessThe concurrent and exclusive read-write algorithms can be combined into the following types of algorithm combinations that are possible for read-write access:
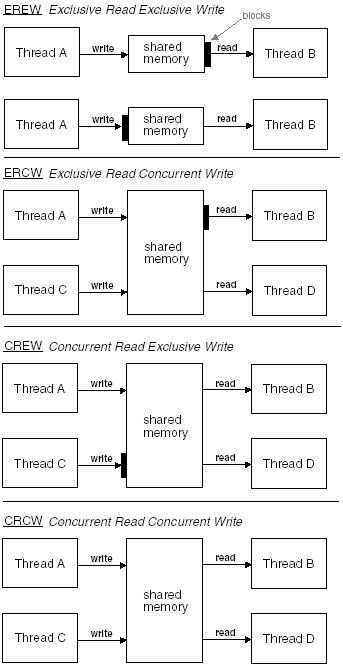
These algorithms can be viewed as the access policy implemented by the tasks sharing the data. Figure 5-4 illustrates these access policies. EREW means access to the shared memory is serialized. Only one task at a time is given access to the shared memory. An example of EREW access policy is the producer-consumer example discussed in Chapter 4. Access to the queue that contained the filenames was restricted to exclusive write by the producer and exclusive read by the consumer. Only one task was allowed access to the queue at any given time. CREW access policy allows multiple reads of the shared memory and exclusive writes. This means there are no restrictions on how many tasks can read the shared memory concurrently but only one task can write to the shared memory. Concurrent reads can occur while an exclusive write is taking place. With this type of access policy, each reading task may read a different value. As a task reads the shared memory, another task modifies it. The next task that reads the shared memory will see different data. The ERCW access policy is the direct reverse of CREW. With ERCW, concurrent writes are allowed but only one task at a time is allowed to read the shared memory. CRCW access policy allows concurrent reads and concurrent writes. Figure 5-4. EREW, CREW, ERCW, and CRCW access policies. Each of these four algorithm types requires different levels and types of synchronization. They can be analyzed on a continuum with the access policy that requires the least amount of synchronization to implement on one end and the access policy that requires the most amount of synchronization at the other end. The goal is to implement these policies and maintain data integrity and satisfactory system performance. EREW is the policy that is the simplest to implement. This is because EREW essentially forces sequential processing. At first blush, you may consider CRCW is the simplest but it presents the most challenges. It may appear as if it has no policy. The memory can be accessed without restriction. But this is the furthest from the truth. This is the most difficult to implement and requires the most synchronization in order to meet our goal. |
EAN: 2147483647
Pages: 133