4.5 Thread Models
| The purpose of a thread is to perform work on behalf of the process. If a process has multiple threads, each thread performs some subtask as part of the overall task to be performed by the process. Threads are delegated work according to a specific strategy or approach that structures how delegation is implemented. If the application models some procedure or entity, then the approach selected should reflect that model. Some common models are:
Each model has its own WBS (Work Breakdown Structure) that determines who is responsible for thread creation and under what conditions threads are created. For example, there is a centralized approach where a single thread creates other threads and delegates work to each thread. There is an assembly-line approach where threads perform different work at different stages. Once the threads are created, they can perform the same task on different data sets, different tasks on the same data set, or different tasks on different data sets. Threads can be categorized to only perform certain types of tasks . For example, there can be a group of threads that only perform computations , process input, or produce output. It may be true that what is to be modeled is not homogeneous throughout the process and it may be necessary to mix models. In Chapter 3, we discussed a rendering process. Tasks 1, 2, and 3 were performed sequentially and tasks 4, 5, and 6 can be performed simultaneously . Each task can be executed by a different thread. If multiple images were to be rendered, threads 1, 2, and 3 can form the pipeline of the process. As thread 1 finishes, the image is passed to thread 2 while thread 1 performs its work on the next image. As these images are buffered, threads 4, 5, and 6 can use a workpile approach. The thread model is a part of the structuring of parallelism in your application where each thread can be executing on a different processor. Table 4-4 lists the thread models with a brief description. Table 4-4. Thread Models
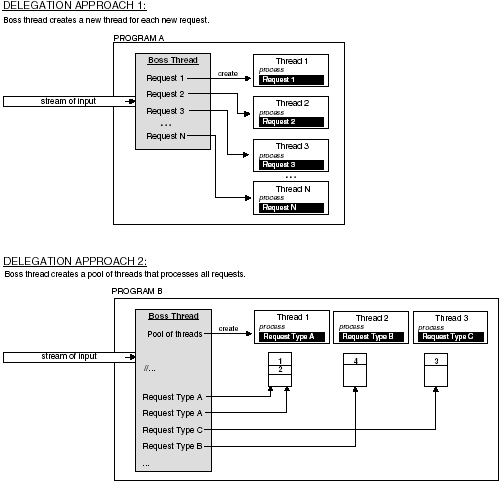
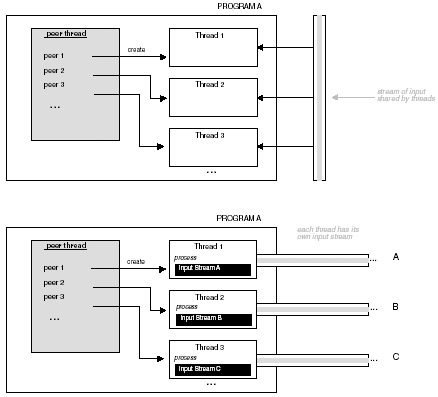
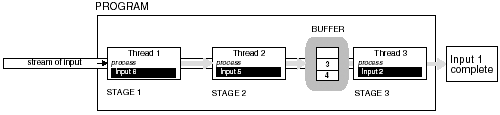
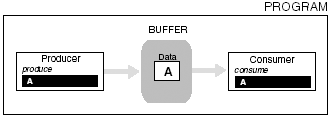
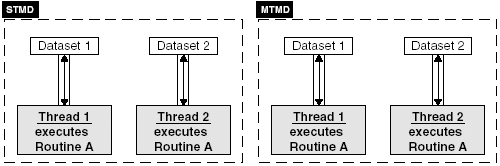
4.5.1 Delegation ModelIn the delegation model, a single thread (boss) creates the threads (workers) and assigns each a task. It may be necessary for the boss thread to wait until each worker thread completes its task. The boss thread delegates the task each worker thread is to perform by specifying a function. As each worker is assigned its task, it is the responsibility of each worker thread to perform that task and produce output or synchronize with the boss or other thread to produce output. The boss thread can create threads as a result of requests made to the system. The processing of each type of request can be delegated to a thread worker. In this case, the boss thread executes an event loop. As events occur, thread workers are created and assigned their duties . A new thread is created for every new request that enters the system. Using this approach may cause the process to exceed its resource or thread limits. Alternatively, a boss thread can create a pool of threads that are reassigned new requests. The boss thread creates a number of threads during initialization and then each thread is suspended until a request is added to their queue. As requests are placed in the queue, the boss thread signals a worker thread to process the request. When the thread completes, it dequeues the next request. If none are available, the thread suspends itself until the boss signals the thread that more work is available in the queue. If all the worker threads are to share a single queue, then the threads can be programmed to only process certain types of requests. If the request in the queue is not of the type a particular thread is to process, the thread can again suspend itself. The primary purpose of the boss thread is to create all the threads, place work in the queue, and awaken worker threads when work is available. The worker threads check the request in the queue, perform the assigned task, and suspend itself if no work is available. All the worker threads and the boss thread execute concurrently. Figure 4-6 contrasts these two approaches for the delegation model. Figure 4-6. The two approaches to the delegation model. 4.5.2 Peer-to-Peer ModelWhere the delegation model has a boss thread that delegates tasks to worker threads, in the peer-to-peer model all the threads have an equal working status. Although there is a single thread that initially creates all the threads needed to perform all the tasks, that thread is considered a worker thread and does no delegation. In this model, there is no centralized thread. The worker (peer) threads have more responsibility. The peer threads can process requests from a single input stream shared by all the threads or each thread may have its own input stream for which it is responsible. The input can also be stored in a file or database. The peer threads may have to communicate and share resources. Figure 4-7 shows the peer-to-peer thread model. Figure 4-7. Peer-to-peer thread model. 4.5.3 Pipeline ModelThe pipeline model is characterized as an assembly line in which a stream of items are processed in stages. At each stage, work is performed on a unit of input by a thread. When the unit of input has been through all the stages, then the processing of the input has been completed. This approach allows multiple inputs to be processed simultaneously. Each thread is responsible for producing its interim results or output, making them available to the next stage or next thread in the pipeline. The last stage or thread produces the result of the pipeline. As the input moves down the pipeline, it may be necessary to buffer units of input at certain stages as threads process previous input. This may cause a slowdown in the pipeline if a particular stage's processing is slower than other stages, causing a backlog. To prevent backlog, it may be necessary for that stage to create additional threads to process incoming input. The stages of work in a pipeline should be balanced where one stage does not take more time than the other stages. Work should be evenly distributed throughout the pipeline. More stages and therefore more threads may also be added to the pipeline. This will also prevent backlog. Figure 4-8 shows the pipeline model. Figure 4-8. The pipeline model. 4.5.4 Producer-Consumer ModelIn the producer-consumer model, there is a producer thread that produces data to be consumed by the consumer thread. The data is stored in a block of memory shared between the producer and consumer threads. The producer thread must first produce data, then the consumer threads retrieve it. This process will require synchronization. If the producer thread deposits data at a much faster rate than the consumer thread consumes it, then the producer thread may at several times overwrite previous results before the consumer thread retrieves it. On the other hand, if the consumer thread retrieves data at a much faster rate than the producer deposits data, then the consumer thread may retrieve identical data or attempt to retrieve data not yet deposited. Figure 4-9 shows the producer-consumer model. The producer-consumer model is also called the client-server model for larger-scaled programs and applications. Figure 4-9. The producer “consumer model. 4.5.5 SPMD and MPMD for ThreadsIn each of the previous thread models, the threads are performing the same task over and over again on different data sets or are assigned different tasks performed on different data sets. These thread models utilize SIMD (Single Instruction Multiple Data) or MPMD (Multiple Programs Multiple Data). These are two models of parallelism that classify programs by instruction and data streams. They can be used to describe the type of work the thread models are implementing in parallel. For our purposes, MPMD is better stated as MTMD (Multiple Threads Multiple Data). These models describe a system that executes different threads processing different sets of data or data streams. SPMD means Single Program Multiple Data or, for our purposes, STMD (Single Thread Multiple Data). This model describes a system that executes a single thread that processes different sets of data or data streams. This means several identical threads executing the same routine are given different sets of data to process. The delegation and peer-to-peer models can both use STMD or MTMD models of parallelism. As described, the pool of threads can execute different routines processing different sets of data. This utilizes the MTMD model. The pool of threads can also be given the same routine to execute. The requests or jobs submitted to the system could be different sets of data instead of different tasks. In this case, a set of threads implementing the same instructions but on different sets of data thus utilizes STMD. The peer-to-peer model can be threads executing the same or different tasks. Each thread can have its own data stream or several files of data that each thread is to process. The pipeline model uses the MTMD model of parallelism. At each stage different processing is performed so multiple input units are at different stages of completion. The pipeline metaphor would be useless if at each stage the same processing was performed. Figure 4-10 contrasts the STMD and MTMD models of parallelism. Figure 4-10. The STMD and MTMD models of parallelism. |
EAN: 2147483647
Pages: 133