13.5 Implementing the Blackboard Using CORBA Objects
| Recall from Chapter 8 that a CORBA object is a platform-independent distributed object. CORBA objects can be accessed between processes on the same machines or processes running on different machines connected to a network. This makes CORBA objects candidates for use in PVM environments where the program is divided into a number of processes that may or may not be running on the same computer. Ordinarily the PVM environment is used for the message-passing strengths and any shared memory approaches are secondary if used at all. The notion of a network-accessible shared object adds computational power to the PVM environment. Keep in mind that CORBA objects can model anything that nondistributed objects can represent. This means PVM tasks that have shared access to CORBA objects can access container objects, framework objects, pattern objects, domain objects, and any kind of utility object. In this case, we want the PVM tasks to have access to blackboard objects. So the message-passing model is supplemented with shared access to complex objects. In addition to PVM tasks accessing distributed CORBA objects, traditional tasks spawned by the posix_spawn() or fork- exec functions can access the CORBA objects. These tasks execute in separate address spaces on the same machine but may still connect to a CORBA object that is either located on the same machine or some different machine. So while the tasks created with the posix_spawn() and fork-exec functions will all reside on the same machine, the CORBA objects can be located on any machine. 13.5.1 The CORBA Blackboard: An ExampleTo demonstrate our notion of a CORBA-based blackboard, we'll look at a blackboard developed at Ctest Laboratories. While providing a complete implementation of the blackboard is beyond the scope of this book and subject to other restrictions, we look closely at some of the most important aspects of the blackboard and the knowledge sources as they relate to our architectural approach to parallel programming. The blackboard implements a software-based course adviser. The blackboard solves the course scheduling problems for the typical college student. Students often encounter several obstacles to the perfect schedule. During course registration there is always a competition for seats in a class. At some point important classes are closed. So there is the infamous first-come, first-serve issue. So during registration where tens of thousands of students are trying to sign up for a limited number of courses, this timeliness is a factor. The student wishes to get courses that apply directly to the degree sought. Ideally these courses will be during hours that the student can attend and has open. Also, the student would like to stay within a certain course load, and keep some time open for working and other extracurricular activities. The problem is that when the student is ready to take a given course, the course may not always be offered, so substitutes or filler classes are offered to the student instead. The substitutes and filler classes add to the cost and duration of the student's education. Adding to the cost and duration are negative outcomes from the student's vantage point. However, if the substitutes or filler classes are in some way related to the student's nonacademic interests, hobbies, or goals, then the substitutes or filler classes will be reluctantly tolerated. Also, there are a number of electives and options that can be taken under the degree sought. The student wishes to have the optimum mix of courses that will allow the student to graduate either early or on time, within budget, and with the most flexibility possible. The student uses real-time course advisement software built with blackboard technology to solve the problem. It is important to note that the blackboard has real-time access to the student's academic record, the current courses open or closed at any instant during the registration process. The blackboard has access to the student's degree plan, the university's requirements for the degree plan, the student availability schedule, the student's goals, and so on. Each of these items are modeled using C++ classes and CORBA classes and make up the components of the blackboard. To keep our blackboard example simple, we will look only at these four knowledge sources:
Example 13.1 shows an excerpt from the blackboard's CORBA interface. Example 13.1 Two CORBA declarations necessary for our blackboard class. typedef sequence<long> courses; interface black_board{ //... void suggestionsForMajor(in courses Major); void suggestionsForMinor(in courses Minor); void suggestionsForGeneral(in courses General); void suggestionsForElectives(in courses Electives); courses currentDegreePlan(); courses suggestedSchedule(); //... }; The primary purpose of the black_board interface is to provide read/write access to the knowledge sources. In this case, the blackboard's partitions will include segments for each knowledge source. [2] This will allow the knowledge sources to access the blackboard with a CRCW policy with respect to each other. That is, multiple types of knowledge sources can access the blackboard at the same time, however, two or more knowledge sources of the same type will be restricted to a CREW policy. Any method or member function the knowledge sources will access should be defined in the black_board interface class. The class courses has been declared as a CORBA type and therefore it can be used as parameter and return values between the knowledge sources and the blackboard. So the black_board class declarations such as:
courses Minor; courses Major; will be used to represent information that is either being written to or read from the blackboard. The type courses is a CORBA typedef for sequence<long> . A sequence in CORBA is a variable-length vector (array). This means that courses will be used to store an array of long s. Each long will be used to store a course code. Each course code represents a course offered at the university. Since C++ does not have a sequence type, the sequence<long> declaration is mapped to a C++ class. The class has the same name as sequence<long> typedef: courses . The mapping process from CORBA types to C++ types occurs during the idl compilation phase when building a CORBA application. The idl compiler will translate the sequence<long> declaration into C++ code. The C++ courses class will have a number of method functions automatically included: allocbuf() freebuf() get_buffer() length() operator[] release() replace() maximum() The knowledge sources will interact with these methods . The sequence<long> declaration will be transparent to the knowledge sources; they only see the class courses . Because CORBA supports datatypes such as struct s, classes, arrays, and sequences, the knowledge sources can exchange sophisticated objects with the blackboard. This allows the programmer to maintain the object-oriented metaphor when exchanging data with the blackboard. Maintaining the object-oriented metaphor where necessary is an important part of reducing the complexity of parallel programming. The ability to easily read and write complex objects or object hierarchies from the blackboard simplifies the programming in parallel applications. There is no need to perform the translation from primitive datatypes to complex objects. The complex objects may be exchanged directly. 13.5.2 The Implementation of the black_board Interface ClassNotice in Example 13.1 the interface class does not declare any variables. Recall the interface class in CORBA is restricted to only declaring the method interfaces. There are no storage components in the interface class. CORBA classes must be supplied with C++ implementations before any work can get done. The actual implementations of the methods and any variables are added to a derived class of the interface class. Example 13.2 shows the derived (implementation) class for the black_board interface class. Example 13.2 An excerpt from the implementation class for the black_board interface class. #include "black_board.h" #include <set.h> class blackboard : virtual public POA_black_board{ protected: //... set<long> SuggestionForMajor; set<long> SuggestionForMinor; set<long> SuggestionForGeneral; set<long> SuggestionForElective; courses Schedule; courses DegreePlan; public: blackboard(void); ~blackboard(void); void suggestionsForMajor(const courses &X); void suggestionsForMinor(const courses &X); void suggestionsForGeneral(const courses &X); void suggestionsForElectives(const courses &X); courses *currentDegreePlan(void); courses *suggestedSchedule(void); //... }; The implementation class is used to provide the actual implementations of the methods defined in the interface class. In addition to method implementation, the derived class may contain data components since it is not declared as an interface. Notice that the black_board implementation class in Example 13.2 does not directly inherit the black_board interface class. Instead it inherits POA_black_board , which is one of the classes that the idl compiler created on behalf of the black_board interface class. Example 13.3 contains the declaration of POA_black_board created by the idl compiler. Example 13.3 Excerpt of the POA_black_board class created by the idl compiler for the black_board interface class. class POA_black_board : virtual public PortableServer: :StaticImplementation { public: virtual ~POA_black_board (); black_board_ptr _this (); bool dispatch (CORBA::StaticServerRequest_ptr); virtual void invoke (CORBA::StaticServerRequest_ptr); virtual CORBA::Boolean _is_a (const char *); virtual CORBA::InterfaceDef_ptr _get_interface (); virtual CORBA::RepositoryId _primary_interface (const PortableServer::ObjectId &, PortableServer::POA_ptr); virtual void * _narrow_helper (const char *); static POA_black_board * _narrow (PortableServer::Servant); virtual CORBA::Object_ptr _make_stub (PortableServer:: POA_ptr, CORBA::Object_ptr); //... virtual void suggestionsForMajor (const courses& Major) = 0; virtual void suggestionsForMinor (const courses& Minor) = 0; virtual void suggestionsForGeneral (const courses& General) = 0; virtual void suggestionsForElectives (const courses& Electives) = 0; virtual courses* currentDegreePlan() = 0; virtual courses* suggestedSchedule() = 0; //... protected: POA_black_board () {}; private: POA_black_board (const POA_black_board &); void operator= (const POA_black_board &); }; Notice that the class in Example 13.3 is an abstract virtual class because it has pure virtual member functions such as: virtual courses* suggestedSchedule() = 0; This means that this class cannot be used directly. It must have a derived class that provides actual member functions for every pure virtual member function. The blackboard class in Example 13.2 provides the required definitions for each pure virtual member function. In the case of our blackboard class, C++ methods will be used to implement the functionality of the blackboard and invocation of the knowledge sources. However, the knowledge sources themselves are implemented partially in C++ and partially in the logic programming language Prolog. [3] But since C++ supports multilanguage and multiparadigm development, the advantages of Prolog can be intermixed with C++. In C++ we can either spawn Prolog executables using posix_spawn() , fork-exec functions, or we can access the Prolog through its foreign language interface that allows Prolog to talk directly to C++ and vice versa. Whether the actual implementation is in C++ or Prolog, the blackboard class only has to interact with C++ methods.
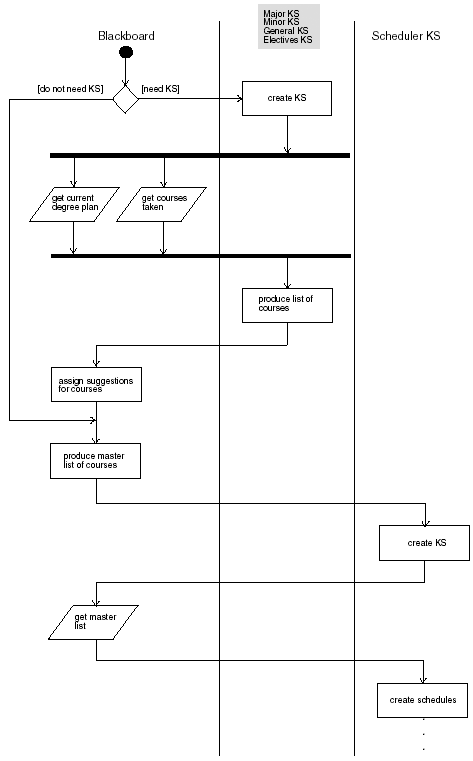
13.5.3 Spawning the Knowledge Sources in the Blackboard's ConstructorThe blackboard is implemented as a distributed object using the CORBA protocol. One of the primary functions of the blackboard in this case is to spawn the knowledge sources. This is important because the blackboard will need access to the process ids of the tasks. The initial state of the blackboard is set in the constructor. The initial state includes information about the student, the student's academic record, the current semester, degree requirements and so on. The blackboard decides which knowledge sources to begin based on the initial state. As the blackboard evaluates the initial problem and state of the system it decides on a list of knowledge sources to invoke. Each knowledge source has an associated binary file. The blackboard uses a container called Solvers to store the names of the binaries of the knowledge sources. Later during the construction process, a function object and the for_each() algorithm are used to spawn the knowledge sources. Recall that any class that has the operator() defined can be used as a function object . Function objects are used with the standard algorithms in place of functions or in addition to functions. Usually where a function can be used a function object may be used instead. To define your own function object you must define the operator() with the appropriate meaning, parameter list, and return type. Our CORBA blackboard implementation can support knowledge sources implemented within PVM tasks, traditional UNIX/Linux tasks, or within separate threads using the POSIX thread libraries. The type of task spawned in the constructor determines whether the blackboard will be working with POSIX threads, traditional UNIX/Linux processes, or PVM tasks. 13.5.3.1 Spawning Knowledge Sources Using PVM TasksPart of the constructor contains the call: for_each(Solve.begin(),Solve.end(),Task); The for_each() algorithm applies the function object operator for the task class to each element of the Solve container. This technique is used to spawn knowledge sources in a MIMD model, which is used when the knowledge sources each have a different speciality working on different data. Example 13.4 contains the declaration of the task class. Example 13.4 The declaration of the task class. class task{ int Tid[4]; int N; //... public: //... task(void) { N = 0; } void operator()(string X); }; void task::operator()(string X) { int cc; pvm_mytid(); cc = pvm_spawn(const_cast<char *>(X.data()),NULL,0,"",1, &Tid[N]);N++; } blackboard::blackboard(void) { task Task; vector<string> Solve; //... // Determine which KS to invoke //... Solve.push_back(KS1); Solve.push_back(KS2); Solve.push_back(KS3); Solve.push_back(KS4); for_each(Solve.begin(),Solve.end(),Task); } This Task class encapsulates a process that has been spawned. It will contain the task ids in the case of PVM. In the case of standard UNIX/Linux processes or Pthreads, it will contain the process ids and thread ids. This class acts as an interface to the created thread or process and the blackboard. The blackboard acts as the primary control component. It can manage the PVM tasks through their task ids. Also, the blackboard can use the PVM group operations to synchronize the PVM tasks with barriers, organize the PVM tasks into logical groups that will work on certain aspects of the problem, and to signal group members with certain message tags. Table 13-2 contains the PVM group routines and their descriptions. The pvm_barrier() and the pvm_joingroup() routines in Table 13-2 are of particular interest to our blackboard because there are situations where the blackboard does not want to launch new knowledge sources until a certain group of knowledge sources has finished their work. The pvm_barrier() routine can be used to block the calling process until the appropriate knowledge sources have finished their processing. For instance, the course advisor blackboard does not want to activate the scheduler knowledge source until the knowledge sources that focus on major requirements, general requirements, minor requirements, and electives are through making their suggestions. So the blackboard will use the pvm_barrier() routine to wait on the PVM task group that focuses on requirements. Figure 13-5 shows a UML activity diagram that shows how the knowledge sources and the blackboard are synchronized. Table 13-2. PVM Group Routines
Figure 13-5. UML activity diagram showing the synchronization of the blackboard and the knowledge sources. In Figure 13-5, the synchronization barrier is implemented with the help of the pvm_barrier() and pvm_joingroup() routines. Example 13.5 contains the function operator of the task object. Example 13.5 The function operator of the task object. void task::operator()(string X) { int cc; pvm_mytid(); cc = pvm_spawn(const_cast<char *>(X.data()),NULL,0,"",1, &Tid[N]);N++; } The function operator is used to spawn PVM tasks. The name of the task is contained in X.data() . The call to the pvm_spawn() routine in Example 13.5 creates one task and stores the task id of the task in Tid[N] . The pvm_spawn() routine and the invocation of PVM tasks are discussed in Chapter 6. The task class is used as a function object . The algorithm: for_each(Solve.begin(),Solve.end(),Task); will cause the operator() to execute for the Task object. This operation will cause a knowledge source in the Solve container to be activated. The for_each() algorithm ensures that each knowledge source will be activated. If the SIMD model is used, then the for_each() algorithm is not necessary. Instead we use a PVM spawn call directly in the constructor of the blackboard. Example 13.6 shows how a set of PVM tasks using a SIMD model can be launched from the blackboard constructor. Example 13.6 Launching PVM tasks from the task class constructor. void task::operator()(string X) { int cc; pvm_mytid(); cc = pvm_spawn(const_cast<char *>(X.data()),NULL,0,"",1, &Tid[N]);N++; } 13.5.3.2 Connecting Blackboard and the Knowledge SourcesIn Example 13.6, 20 knowledge sources are spawned. Initially they will each execute the same code. After they are spawned, the blackboard will send messages to them representing what part they are to play in the problem-solving process. With this configuration the knowledge sources and the blackboard are part of the PVM. After the knowledge sources are created, they will be able to interact with the blackboard by connecting to the port that the blackboard is located on, or to the address the blackboard is at on an intranet or the Internet. The knowledge sources will need the object reference for the blackboard. These references may be coded within the knowledge sources, or the knowledge sources might read them from a configuration file, or get them from a naming service. Once the knowledge source has the reference the knowledge source interacts with the ORB (Object Request Broker) to locate the actual knowledge and activate it. For our example, we will assign the blackboard a specific port. We start the CORBA blackboard with a command: blackboard -ORBIIOPAddr inet:porthos:12458 This command executes our blackboard program and assigns it to listen on port 12458 on host porthos . Starting a CORBA object will differ depending on the CORBA implementation used. Here we are using Mico, [4] an open-source implementation of CORBA. When the blackboard program executes, it instantiates the blackboard that in turn spawns the knowledge sources. When the knowledge sources are spawned by the blackboard they will have the port number hard-coded. Example 13.7 shows an excerpt from a knowledge source that connects to the CORBA-based blackboard.
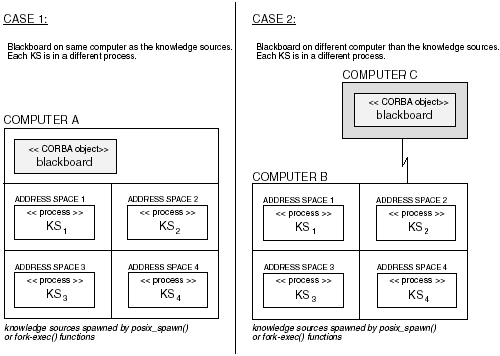
Example 13.7 A knowledge source that connects to the CORBA blackboard. 1 #include "pvm3.h" 2 using namespace std; 3 #include <iostream> 4 #include <fstream> 5 #include <string.h> 6 #include <strstream> 7 #include "black_board_impl.h" 8 9 int main(int argc, char *argv[]) 10 { 11 CORBA::ORB_var Orb = CORBA::ORB_init(argc,argv, "mico-local-orb"); 12 CORBA::Object_var Obj =Orb->bind("IDL:black_board:1.0", "inet:porthos:12458"); 13 courses Courses; 14 //... 15 //... 16 black_board_var BlackBoard = black_board::_narrow(Obj); 17 18 int Pid; 19 //... 20 //... 21 22 cout << "created the knowledge source" << endl; 23 Courses.length(2); 24 Courses[0] = 255551; 25 Courses[1] = 253212; 26 string FileName; 27 strstream Buffer; 28 Pid = pvm_mytid(); 29 Buffer << "Result." << Pid << ends; 30 Buffer >> FileName; 31 ofstream Fout(FileName.data()); 32 BlackBoard->suggestionsForMajor(Courses); 33 Fout.close(); 34 pvm_exit(); 35 return(0); 36 } 37 In line 11 in Example 13.7, the ORB runtime is initalized. Line 12 associates the black_board object name with the port 12458 and returns a reference to the CORBA object in the Obj variable. Line 16 performs a kind of cast operation so that the Blackboard variable is referring to the right size object. Once the knowledge source has instantiated the Blackboard object, any method declared in the black_board interface shown in Example 13.1 may be invoked. Notice on line 13 that the object Courses is instantiated. Recall that courses was originally defined as a CORBA sequence type. Here, the knowledge source is using the class courses created during the idl compilation. The elements are added to this class as they would be for an array. Lines 24 and 25 add two courses to the Courses object and line 32 contains the method invocation: BlackBoard->suggestionsForMajor(Courses) This call writes the courses on the blackboard. Similarly, the: courses currentDegreePlan(); courses suggestedSchedule(); methods can be used to read information from the blackboard. So all that is needed by the knowledge source is a reference to the Black_board object. The Black_board object may be located anywhere within an intranet or the Internet. It is the ORB's responsibility to actually locate the object. (Chapter 8 discusses the process of locating and activating CORBA objects.) Because the Black_board object has the PVM task ids, it may perform task management and send and receive messages directly from the knowledge sources. Likewise the knowledge sources may communicate directly with each other using the more traditional PVM messaging. It is important to note that the destructor for the Black_board object will call pvm_exit() and each knowledge source should call pvm_exit() after there are no more PVM system calls. This will remove them from the PVM environment, although other processing may continue. 13.5.3.3 Activating Knowledge Sources Using POSIX spawn()Implementing the knowledge sources or problem solvers within PVM tasks is especially useful when the tasks will run on separate computers. Each knowledge source can take advantage of any special resource that a particular computer may have. These resources can include processor speed, databases, special peripherals, processor architectures, and numbers of processors. The PVM tasks may also be used on a single computer that has multiple processors. However, since our blackboard can be implemented by connecting to ports, we can just as easily use traditional UNIX/Linux processes to contain our knowledge sources. When the knowledge sources are created in standard UNIX/Linux processes and the computer has multiple processors, then the knowledge sources may run concurrently on the processors available. Obviously if there are more knowledge sources than there are processors, then multitasking will be necessary. Figure 13-6 shows two simple architectures that can be used with the CORBA-based blackboard and UNIX/Linux processes. Figure 13-6. Two architectures that can be used with the CORBA-based blackboard and UNIX/Linux processes. In Case 1, the CORBA object is located on the same computer as the knowledge sources and each knowledge source has its own address space. That is, each knowledge source has been spawned using either the posix_spawn() routine or the fork-exec routines. In Case 2, the CORBA object is located on a different computer and the knowledge sources are each located on the same computer but in different address spaces. In both Case 1 and Case 2, the CORBA object acts as a kind of shared memory for the knowledge sources because they each have access to it and they may exchange information through the blackboard. But there is a major advantage of the CORBA object ”it is far more sophisticated than a simple block of memory locations. The blackboard is a complete object that may consist of any type of data structure, object, or even other blackboards . This kind of sophistication cannot be easily implemented using the basic shared memory routines. So the CORBA gives us an ideal method for implemented complex shared objects between processes. In section 13.5.3.1 we spawned PVM tasks that implemented the knowledge sources. Here we change the constructor to contain calls to the posix_spawn() routine or we can use our for_each() algorithm and the task function object to call the posix_spawn() routine. In Case 1 in Figure 13-6, the blackboard can spawn the knowledge sources from its constructor. However, in Case 2, this is not possible because the blackboard is located on a separate computer. In Case 2, the blackboard will use some intermediary to cause the posix_spawn() routine to be executed. There are several options available such as the blackboard calling another CORBA object on the computer that contains the knowledge sources, or RPC, or using a MPI or PVM task that will call a program containing a call to posix_spawn() . Chapter 3 contains a discussion of how to set up a call to posix_spawn() . Example 13.8 shows how the posix_spawn() routine can be used to activate one of the knowledge sources. Example 13.8 Using posix_spawn() to launch knowledge sources. #include <spawn.h> blackboard::blackboard(void) { //... pid_t Pid; posix_spawnattr_t M; posix_spawn_file_actions_t N; posix_spawn_attr_init(&M); posix_spawn_file_actions_init(&N); char *const argv[] = {"knowledge_source1",NULL}; posix_spawn(&Pid,"knowledge_source1",&N,&M,argv,NULL); //... } In Example 13.8, the spawn attributes and the spawn file actions are initialized and then the posix_spawn() routine is used to create a separate process that will execute knowledge_source1 . Once this process is created the blackboard has some access to the process through the process's id stored in Pid . In addition to the blackboard as a means of communication, the standard IPC communication is available if the blackboard is located on the same computer as the knowledge sources. While sockets are available in the configuration where the blackboard is on a separate computer, the blackboard is the simplest means of communication between the knowledge sources. When using this configuration, the control that the blackboard has over the knowledge sources will be governed more strictly by the content of the blackboard at any given time as opposed to sending messages directly to the knowledge sources. Sending messages directly is more easily accommodated using the blackboard in conjunction with PVM tasks. Here the knowledge sources regulate themselves based on the content of the blackboard. However, the blackboard does have some level of control over the knowledge sources because the blackboard has the process ids for each process containing a knowledge source. Both the MPMD (MIMD) and SPMD (SIMD) models are also supported using the posix_spawn() routine. Example 13.9 shows a class that will be used as a function object with the for_each() algorithm. Example 13.9 The child_process will be used as a function object when launching knowledge sources. class child_process{ string Command; posix_spawnattr_t M; posix_spawn_file_actions_t N; pid_t Pid; //... public: child_process(void); void operator()(string X); void spawn(string X); }; void child_process::operator()(string X) { //... posix_spawnattr_init(&M); posix_spawn_file_actions_init(&N); Command.append("/tmp/"); Command.append(X); char *const argv[] = {const_cast<char*>(Command.data()) ,NULL}; posix_spawn(&Pid,Command.data(),&N,&M,argv,NULL); Command.erase(Command.begin(),Command.end()); //... } We encapsulate the attributes for the posix_spawn() routine in a class named child_process . Encapsulating all of the information needed to use the posix_spawn() routine within a class makes it easier to use posix_spawn() and provides a natural interface to the attributes of a process that will be created using posix_spawn() . Notice in Example 13.9 that we defined the operator () for the child_process class. This means that the class can be used as a function object with the for_each() algorithm. As the blackboard decides which knowledge sources will be involved in a problem-solving effort, it stores the name of the knowledge sources in a container we call Solve . Later, during the construction of the blackboard, the knowledge sources are activated using the for_each() algorithm. // Constructor //... child_process Task; for_each(Solve.begin(),Solve.end(),Task); This will cause the operator() method shown in Example 13.9 to be executed for each element of the Solve container. Once these knowledge sources are activated, they access a reference to the blackboard and can begin the problem-solving process. Although these are not PVM tasks they connect to the blackboard in the same manner (see section 13.5.3.2) and they perform the work in the same manner. The difference is the interprocess communication between standard UNIX/Linux processes and the interprocess communication that is possible using the PVM environment. Also, the PVM tasks may be located on separate computers. While processes created with posix_spawn() exist on the same computer. If processes created by either posix_spawn() or the fork-exec routines are to be used in conjunction with the SIMD model, then the argc and argv parameters can be used in addition to the blackboard to assign the knowledge sources a specific area of the problem to solve. In the case where the blackboard is on the same computer as the knowledge sources and the blackboard activates the knowledge sources in its constructor, then technically the blackboard is the parent of the knowledge sources and the knowledge sources will inherit the environment variables of the blackboard. The environment variables of the blackboard are an additional method that can be used to pass information to the knowledge sources. These environment variables can be easily manipulated using the: #include <stdlib.h> //... setenv(); unsetenv(); putenv(); routines. When the knowledge sources are implemented in processes that were created using either posix_spawn() or the fork-exec routines, the programs look like regular CORBA programs and can take advantage of all of the facilities that the CORBA protocol has to offer. |
EAN: 2147483647
Pages: 133